贝叶斯信念网络
2014-01-11 22:37
281 查看
贝叶斯分类是统计学分类方法。它们可以预测类成员关系的可能性,如给定样本属于一个特定类的概率。
贝叶斯定理是就是在给定的数据概率来表示未知的后验概率。比如已知某水果是红色的情况下,判断该水果有多大的概率是苹果,用数学符号表示就是
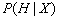
(后验概率),其中X表示“这个水果是红色的”,H表示“这个水果是苹果”。这个概率我们是不知道的,但是如果我们有大量的水果样本,就可以计算水果样本中的统计信息来逼近这个概率。
下面的三个概率都是可以通过样本统计简单计算得到的:“一个水果的颜色是红色”的概率P(X);“一个水果是苹果” 的概率 P(H)(先验概率);“如果一个水果是苹果那么它的颜色是红色”的概率

。
我们可以推理得到:

=
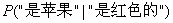
=

/

=
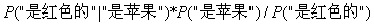
=
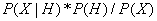
抽象得到的公式
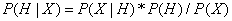
就是著名的贝叶斯定理。
贝叶斯分类的基本思路就是把
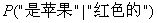
、
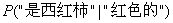
、

、
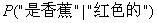
……的概率都算出来,当有未知分类的样本时,就认为这个样本是后验概率最大的那个分类的。
朴素贝叶斯分类
实际情况要比上面的那个例子复杂一些,因为一个事物的属性是多维的,一个水果的属性可能就要包括:颜色、形状、重量、体积……。
实际上的分类可能是要算这样一个概率:
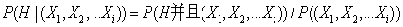
如果属性相互独立,那么
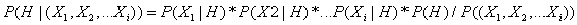
朴素贝叶斯的朴素之处在于不管属性独不独立,都按独立来算,这样可以使运算大大简化。
归纳一下朴素贝叶斯的运算流程:
1. 每个数据样本用一个n维特征向量
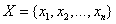
表示,描述由属性

对样本的n个度量。
2. 假定有m个类

。给定一个未知的数据样本X(即,没有类标号),分类法将预测X属于具有最高后验概率(条件X下)的类。即,朴素贝叶斯分类将未知的样本分配给类Ci
,当且仅当:
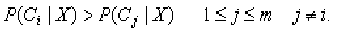
这样,我们最大化
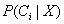
。其

最大的类Ci称为最大后验假定。根据贝叶斯定理:
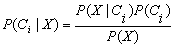
3.由于P(X) 对于所有类为常数,只需要
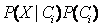
最大即可。如果类的先验概率未知,则通常假定这些类是等概率的;即,

。并据此对只
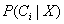
最大化。否则,我们最大化
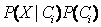
。注意,类的先验概率可以用

计算;其中,si是类C中的训练样本数,而s是训练样本总数。
4.给定具有许多属性的数据集,计算
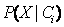
的开销可能非常大。为降低计算
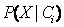
的开销,可以做类条件独立的朴素假定。给定样本的类标号,假定属性值条件地相互独立。即,在属性间,不存在依赖关系。这样,

概率
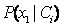
,

,...,
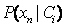
可以由训练样本估值,其中,
(a) 如果Ak是分类属性,则
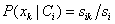
;其中sik
是在属性Ak 上具有值xk 的类Ci 的训练样本数,而si 是Ci中的训练样本数。
(b) 如果是连续值属性,则通常假定该属性服从高斯分布。因而,

其中,给定类Ci的训练样本属性Ak的值,
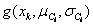
是属性Ak的高斯密度函数,而
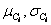
分别为平均值和标准差。
5.为对未知样本X分类,对每个类Ci,计算

。样本X被指派到类Ci,当且仅当:
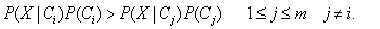
换言之,X被指派到其
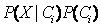
最大的类Ci。
贝叶斯信念网络
朴素贝叶斯假定属性之间是独立的。贝叶斯信念网络说明联合概率分布,它提供一种因果关系的图形,可以在其上进行学习。
信念网络由两部分定义。第一部分是有向无环图,其每个结点代表一个随机变量,而每条弧代表一个概率依赖。如果一条弧由结点Y到Z,则Y是Z的双亲或直接前驱,而Z是Y的后继。第二部分是每个属性一个条件概率表(CPT)。
下面是一个LungCancer的CPT。

在贝叶斯信念网络中对应于属性或变量
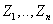
的任意元组

的联合概率由下式计算:

如上图,对于FamilyHistory,Smoker,LungCancer这三个属性,用朴素贝叶斯计算,得到的联合概率是

。
但是如果用贝叶斯信念网络计算得到的联合概率将会是:

,会更为准确。
贝叶斯信念网络的问题
1、如果贝叶斯信念网络的网络结构和所有数值都是给定的,那么可以直接进行计算。但是,数据是隐藏的,比如上图中的FamilyHistory/Somker到LungCancer的条件概率是未知的,只是知道存在这样的依存关系,这时就需要进行条件概率的估算。梯度训练算法和EM算法常被用于处理此问题。
2、贝叶斯网络的数据结构可能是未知的,这时就需要根据已知数据启发式学习贝叶斯网络结构。K2算法可用于解决此问题。
梯度训练算法
梯度训练是用于解决信念网络中隐藏数据问题的,就是已知上图(a),但是不知道上图(b)。
设D是d个训练样本

的集合,

是具有双亲
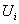
=
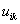
的变量

=
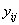
的CPT项。例如,如果

是上图(b)左上角的CPT项,则
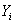
是LungCancer;
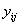
是其值“yes”;
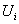
列出
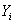
的双亲结点{FamilyHistory,
Smoker};而
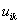
列出双亲结点的值{“yes”,
“yes”}。
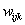
可以看作权,类似于神经网络中隐藏单元的权。权的集合记作
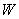
。
梯度训练算法就是求出最为满足

训练版本集的权的集合
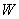
,用数学公式表示就是
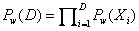
最大(
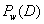
就表示
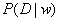
)。
具体的算法:
1、就是对每一个
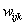
取偏导数,
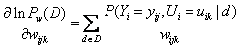
2、更新权值:沿梯度方向前进一小步。
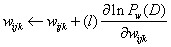
,其中l是学习率,是一个小常数。
3、由于权值
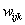
是概率值,它们必须在0.0和1.0之间,并且对于所有的i,k,
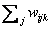
必须等于1。在权值被式更新后,可以对它们重新规格化来保证这一条件。
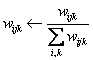
关于
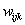
的偏导数推导如下:

佐证:Intro. to machine learning (CSI 5325) Lecture 14: Bayesian learning http://www.google.com.hk/url?sa=t&rct=j&q=Intro.%20to%20machine%20learning%20(CSI%205325)%20Lecture%2014%3A%20Bayesian%20learning&source=web&cd=1&ved=0CCcQFjAA&url=%68%74%74%70%3a%2f%2f%63%73%2e%65%63%73%2e%62%61%79%6c%6f%72%2e%65%64%75%2f%7e%68%61%6d%65%72%6c%79%2f%63%6f%75%72%73%65%73%2f%35%33%32%35%5f%31%31%73%2f%6c%65%63%74%75%72%65%73%2f%6c%65%63%74%75%72%65%5f%31%34%2e%70%64%66&ei=AVfRUqb1GYiPiAf3z4DYCQ&usg=AFQjCNGHKL3FXRYFiTE0aaTBcG_RljuPrg&bvm=bv.59026428,d.aGc&cad=rjt

贝叶斯定理是就是在给定的数据概率来表示未知的后验概率。比如已知某水果是红色的情况下,判断该水果有多大的概率是苹果,用数学符号表示就是

(后验概率),其中X表示“这个水果是红色的”,H表示“这个水果是苹果”。这个概率我们是不知道的,但是如果我们有大量的水果样本,就可以计算水果样本中的统计信息来逼近这个概率。
下面的三个概率都是可以通过样本统计简单计算得到的:“一个水果的颜色是红色”的概率P(X);“一个水果是苹果” 的概率 P(H)(先验概率);“如果一个水果是苹果那么它的颜色是红色”的概率
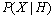
。
我们可以推理得到:

=

=

/

=

=

抽象得到的公式

就是著名的贝叶斯定理。
贝叶斯分类的基本思路就是把

、

、

、

……的概率都算出来,当有未知分类的样本时,就认为这个样本是后验概率最大的那个分类的。
朴素贝叶斯分类
实际情况要比上面的那个例子复杂一些,因为一个事物的属性是多维的,一个水果的属性可能就要包括:颜色、形状、重量、体积……。
实际上的分类可能是要算这样一个概率:

如果属性相互独立,那么

朴素贝叶斯的朴素之处在于不管属性独不独立,都按独立来算,这样可以使运算大大简化。
归纳一下朴素贝叶斯的运算流程:
1. 每个数据样本用一个n维特征向量

表示,描述由属性

对样本的n个度量。
2. 假定有m个类

。给定一个未知的数据样本X(即,没有类标号),分类法将预测X属于具有最高后验概率(条件X下)的类。即,朴素贝叶斯分类将未知的样本分配给类Ci
,当且仅当:

这样,我们最大化

。其

最大的类Ci称为最大后验假定。根据贝叶斯定理:

3.由于P(X) 对于所有类为常数,只需要

最大即可。如果类的先验概率未知,则通常假定这些类是等概率的;即,

。并据此对只

最大化。否则,我们最大化

。注意,类的先验概率可以用

计算;其中,si是类C中的训练样本数,而s是训练样本总数。
4.给定具有许多属性的数据集,计算
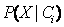
的开销可能非常大。为降低计算

的开销,可以做类条件独立的朴素假定。给定样本的类标号,假定属性值条件地相互独立。即,在属性间,不存在依赖关系。这样,

概率

,

,...,

可以由训练样本估值,其中,
(a) 如果Ak是分类属性,则

;其中sik
是在属性Ak 上具有值xk 的类Ci 的训练样本数,而si 是Ci中的训练样本数。
(b) 如果是连续值属性,则通常假定该属性服从高斯分布。因而,

其中,给定类Ci的训练样本属性Ak的值,

是属性Ak的高斯密度函数,而

分别为平均值和标准差。
5.为对未知样本X分类,对每个类Ci,计算

。样本X被指派到类Ci,当且仅当:

换言之,X被指派到其

最大的类Ci。
贝叶斯信念网络
朴素贝叶斯假定属性之间是独立的。贝叶斯信念网络说明联合概率分布,它提供一种因果关系的图形,可以在其上进行学习。
信念网络由两部分定义。第一部分是有向无环图,其每个结点代表一个随机变量,而每条弧代表一个概率依赖。如果一条弧由结点Y到Z,则Y是Z的双亲或直接前驱,而Z是Y的后继。第二部分是每个属性一个条件概率表(CPT)。
下面是一个LungCancer的CPT。

在贝叶斯信念网络中对应于属性或变量

的任意元组

的联合概率由下式计算:

如上图,对于FamilyHistory,Smoker,LungCancer这三个属性,用朴素贝叶斯计算,得到的联合概率是

。
但是如果用贝叶斯信念网络计算得到的联合概率将会是:

,会更为准确。
贝叶斯信念网络的问题
1、如果贝叶斯信念网络的网络结构和所有数值都是给定的,那么可以直接进行计算。但是,数据是隐藏的,比如上图中的FamilyHistory/Somker到LungCancer的条件概率是未知的,只是知道存在这样的依存关系,这时就需要进行条件概率的估算。梯度训练算法和EM算法常被用于处理此问题。
2、贝叶斯网络的数据结构可能是未知的,这时就需要根据已知数据启发式学习贝叶斯网络结构。K2算法可用于解决此问题。
梯度训练算法
梯度训练是用于解决信念网络中隐藏数据问题的,就是已知上图(a),但是不知道上图(b)。
设D是d个训练样本

的集合,

是具有双亲

=

的变量

=
的CPT项。例如,如果

是上图(b)左上角的CPT项,则

是LungCancer;

是其值“yes”;

列出

的双亲结点{FamilyHistory,
Smoker};而

列出双亲结点的值{“yes”,
“yes”}。

可以看作权,类似于神经网络中隐藏单元的权。权的集合记作

。
梯度训练算法就是求出最为满足

训练版本集的权的集合

,用数学公式表示就是

最大(

就表示

)。
具体的算法:
1、就是对每一个

取偏导数,

2、更新权值:沿梯度方向前进一小步。

,其中l是学习率,是一个小常数。
3、由于权值

是概率值,它们必须在0.0和1.0之间,并且对于所有的i,k,

必须等于1。在权值被式更新后,可以对它们重新规格化来保证这一条件。

关于

的偏导数推导如下:

佐证:Intro. to machine learning (CSI 5325) Lecture 14: Bayesian learning http://www.google.com.hk/url?sa=t&rct=j&q=Intro.%20to%20machine%20learning%20(CSI%205325)%20Lecture%2014%3A%20Bayesian%20learning&source=web&cd=1&ved=0CCcQFjAA&url=%68%74%74%70%3a%2f%2f%63%73%2e%65%63%73%2e%62%61%79%6c%6f%72%2e%65%64%75%2f%7e%68%61%6d%65%72%6c%79%2f%63%6f%75%72%73%65%73%2f%35%33%32%35%5f%31%31%73%2f%6c%65%63%74%75%72%65%73%2f%6c%65%63%74%75%72%65%5f%31%34%2e%70%64%66&ei=AVfRUqb1GYiPiAf3z4DYCQ&usg=AFQjCNGHKL3FXRYFiTE0aaTBcG_RljuPrg&bvm=bv.59026428,d.aGc&cad=rjt

相关文章推荐
- [置顶] 贝叶斯网络(又称贝叶斯信念网络或信念网络)
- 朴素贝叶斯与贝叶斯信念网络
- 贝叶斯信念网络
- CB,朴素贝叶斯和贝叶斯信念网络
- 第九章 贝叶斯信念网络分类
- 贝叶斯信念网络 ——转
- 贝叶斯信念网络
- 第九章 贝叶斯信念网络分类
- 贝叶斯信念网络和马尔科夫链有什么区别
- 【theano-windows】学习笔记十六——深度信念网络DBN
- 贝叶斯网络的训练和推算
- 转】深度学习--深度信念网络(Deep Belief Network)
- 贝叶斯网络工具Hugin api的使用
- 受限玻尔兹曼机(RBM, Restricted Boltzmann machines)和深度信念网络(DBN, Deep Belief Networks)
- 贝叶斯网络
- 贝叶斯网络推理算法简单罗列
- 贝叶斯网络小结
- 贝叶斯网络的构建-学习-推理(C++源代码)分析
- 贝叶斯网络与LDA
- 贝叶斯神经网络工具包FullBNT,在Matlab中的导入及应用实例