学习笔记:逻辑斯蒂回归(logistic regression)
2013-12-28 13:17
453 查看
什么是逻辑斯蒂回归,参见维基百科的解释点击打开链接。
后面的参考博客已经给逻辑斯蒂回归做了很多基础东西的讲解(越是基础的东西越难讲清楚)。在这里我对逻辑斯蒂回归记录一点自己的认识。
两个问题:
Q1,为什么选用logistic function?
Q2,logistic regression模型参数怎么找?
[b]Q1,为什么选用logistic function?
[/b]
参考博客4中给出的一个解释,在此进行罗列。
一个线性模型的输出值 y 越大,这个事件 P(Y=1|x) 发生的概率就越大。 另一方面,我们可以用事件的几率(odds)来表示事件发生与不发生的比值,假设发生的概率是
p ,那么发生的几率(odds)是 p/(1-p) , odds 的值域是 0 到正无穷,几率越大,发生的可能性越大。将我们的直觉与几率联系起来的就是下面这个(log odds)或者是 logit 函数
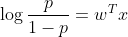
由上述函数可以可以得到逻辑斯蒂回归模型:
=%5Cfrac%7Be%5E%7Bw%5E%7BT%7Dx%7D%7D%7B1+e%5E%7Bw%5E%7BT%7Dx%7D%7D=%5Cfrac%7B1%7D%7B1+e%5E%7B-w%5E%7BT%7Dx%7D%7D)
=%5Cfrac%7B1%7D%7B1+e%5E%7Bw%5E%7BT%7Dx%7D%7D=%5Cfrac%7Be%5E%7B-w%5E%7BT%7Dx%7D%7D%7B1+e%5E%7B-w%5E%7BT%7Dx%7D%7D)
Q2,logistic regression[b]模型参数怎么找?[/b]
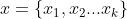
是样本,每个样本是由一组样本特征表示。
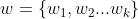
是参数组,每个参数组由对应特征的参数组成。
logistic regression建模时候无非就是找到一组非常合适的参数
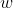
。这组参数按照什么样的标准去找? 参数
变化导致什么在变? 我觉得这两个问题弄清楚,那么对logistic regression也就有了一个直观的认识。
简单起见,stanford的Andrew的课程中,从cost function出发去分析。为什么选用这个cost function。课程里面讲解是因为有牛人证明过他是凸的,他是有全局最优解的,我们可以使用梯度下降,牛顿法等去寻找这参数组
。当然也可能存在其他的cost function,按照其他的标准去寻找。
在coursera中:
hypothesis是:
=g(w%5E%7BT%7Dx)=%5Cfrac%7B1%7D%7B1+e%5E%7B-w%5E%7BT%7Dx%7D%7D)
[ 这里出来的数值表示x被标记为1(正例)的概率 ]
单个样本cost function是:
=&space;%5Cleft%5C%7B&space;%5Cbegin%7Barray%7D%7Bc%7D&space;-log(h_%7Bw%7D(x))&space;%5Cquad&space;%5C&space;%5C&space;%5C&space;%5C&space;%5C&space;if&space;%5C&space;y&space;=&space;1&space;%5C%5C&space;-log(1-h_%7Bw%7D(x))&space;%5Cquad&space;if&space;%5C&space;y&space;=&space;0%5C%5C&space;%5Cend%7Barray%7D&space;%5Cright.)
上面两个合起来写就是:
=y*%5Clog&space;h_%7Bw%7D(x%5E%7B(i)%7D)&space;+&space;(1-y%5E%7B(i)%7D)*%5Clog&space;(1-h_%7Bw%7D(x(i)))
总体样本的cost function是:
=%5Cfrac&space;%7B1%7D%7Bm%7D%5Csum%5E%7Bn%7D_%7Bi=1%7DCost(h_%7Bw%7D(x%5E%7B(i)%7D),&space;y%5E%7B(i)%7D))
**********************************************************************************************************************************************************
《统计学习方法》(李航 著)
逻辑斯蒂回归模型,概率分布为:
再用极大似然估计法估计模型参数的时候,似然函数为:
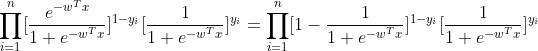
对数似然函数
*&space;%5Clog&space;(1-&space;%5Cfrac%7B1%7D%7B1+e%5E%7B-w%5E%7BT%7Dx%7D%7D)%5D)
到此,发现上述总体样本的cost function和这个对数似然函数似乎是一个东西。
**********************************************************************************************************************************************************
我们的目标就是去寻找一组参数组
;,最小化上述的总体样本的cost即
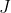
的数值。cost function是什么样的?我们将单个cost function拆开来看,如下图
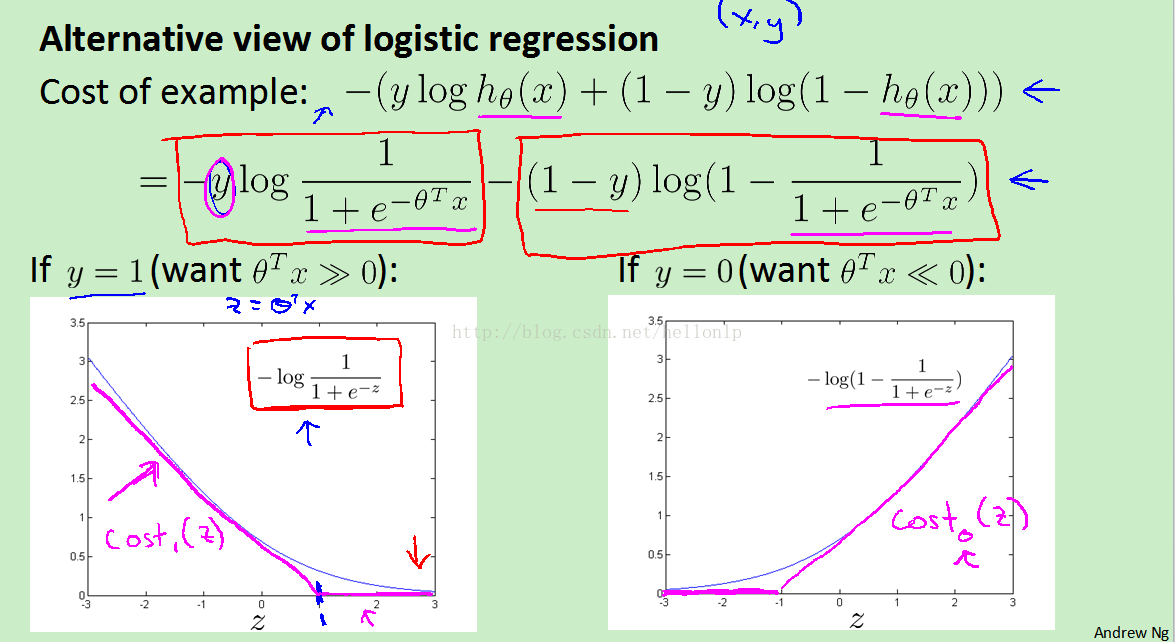
图1,logistic regression对于单个样本的cost function(平滑的那条线,不是那边折线)
*图片来自coursera中Andrew Ng讲授的Machine Learning的课件

图2,经过参数组w映射后的logit函数。
*图片来自coursera中Andrew Ng讲授的Machine Learning的课件
我们会发现对于单个样本
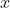
, 他进过映射后(也就是
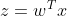
)成为

进入另一个坐标系(图1中画的那个坐标系)。我们看到对于
,在我们的寻找标准(也就是cost function)中,我们是希望这个训练样本
,如果它是正例(标记为1的样本,对应于图1中左边的坐标系),我们希望他进过映射后的
能够很大,以至于cost很小,接近于0;如果他是负例(标记为0的样本,对应于图1中右边的坐标系),我们希望它经过映射后的
能够很小,以至于cost很小,接近于0。单看某一个样本,调整参数组
,它自己的cost可以很小。但是我们是希望总体的cost即
(注意
是对所有样本的cost求和)最小。
对于某一个样本
,变化参数组
,它自身的cost可能变小很多,但是对于其他的样本,他们的cost也同时在变化。也就是说对于单个样本最好的参数组
,不一定是对于所有样本最好的参数组
。我们调整参数组
,就是希望样本映射后的
,在图2中正例尽量往右侧靠(它的p就非常接近1),负例尽量往左侧靠(它的p非常接近0)。[在图2中正例尽量往左侧靠(它的p就非常接近1),负例尽量往右侧靠(它的p非常接近0)。
感谢网友指出]具体做法,就是选择一组参数
,然后观察样本映射后的分布。然后按照最小化cost的标准去调整参数组
,使用调整后的
去映射样本,然后继续观察样本映射后的分布,继续调整下去.....
注意,当某一组参数
;,使得样本的判别全部正确(正例样本都分类为1,负例样本都分类为0
),此时的
也不一定的最优的。因为全部全别正确,只是说明映射后在图2中正例全部在右侧,负例全部在左侧。但此时可能不是往两端靠近。切记,我们找到的参数组
,是使得样本映射后的
总体往两端靠的最远。
实际使用时候需要注意:
1.样本的特征需要进行feature scaling
2.为了减轻过拟合带来的影响,需要对模型进行regularization。通常是总体样本的cost function加上一个小尾巴
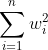
。
参考博客:
1. http://hi.baidu.com/hehehehello/item/40025c33d7d9b7b9633aff87
2. http://52opencourse.com/125/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AC%AC%E5%85%AD%E8%AF%BE-%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92-logistic-regression
3. http://blog.csdn.net/abcjennifer/article/details/7716281
4. http://www.cnblogs.com/daniel-D/archive/2013/05/30/3109276.html
后面的参考博客已经给逻辑斯蒂回归做了很多基础东西的讲解(越是基础的东西越难讲清楚)。在这里我对逻辑斯蒂回归记录一点自己的认识。
两个问题:
Q1,为什么选用logistic function?
Q2,logistic regression模型参数怎么找?
[b]Q1,为什么选用logistic function?
[/b]
参考博客4中给出的一个解释,在此进行罗列。
一个线性模型的输出值 y 越大,这个事件 P(Y=1|x) 发生的概率就越大。 另一方面,我们可以用事件的几率(odds)来表示事件发生与不发生的比值,假设发生的概率是
p ,那么发生的几率(odds)是 p/(1-p) , odds 的值域是 0 到正无穷,几率越大,发生的可能性越大。将我们的直觉与几率联系起来的就是下面这个(log odds)或者是 logit 函数
由上述函数可以可以得到逻辑斯蒂回归模型:
Q2,logistic regression[b]模型参数怎么找?[/b]
是样本,每个样本是由一组样本特征表示。
是参数组,每个参数组由对应特征的参数组成。
logistic regression建模时候无非就是找到一组非常合适的参数
。这组参数按照什么样的标准去找? 参数
变化导致什么在变? 我觉得这两个问题弄清楚,那么对logistic regression也就有了一个直观的认识。
简单起见,stanford的Andrew的课程中,从cost function出发去分析。为什么选用这个cost function。课程里面讲解是因为有牛人证明过他是凸的,他是有全局最优解的,我们可以使用梯度下降,牛顿法等去寻找这参数组
。当然也可能存在其他的cost function,按照其他的标准去寻找。
在coursera中:
hypothesis是:
[ 这里出来的数值表示x被标记为1(正例)的概率 ]
单个样本cost function是:
上面两个合起来写就是:
总体样本的cost function是:
**********************************************************************************************************************************************************
《统计学习方法》(李航 著)
逻辑斯蒂回归模型,概率分布为:
再用极大似然估计法估计模型参数的时候,似然函数为:
对数似然函数
到此,发现上述总体样本的cost function和这个对数似然函数似乎是一个东西。
**********************************************************************************************************************************************************
我们的目标就是去寻找一组参数组
;,最小化上述的总体样本的cost即
的数值。cost function是什么样的?我们将单个cost function拆开来看,如下图
图1,logistic regression对于单个样本的cost function(平滑的那条线,不是那边折线)
*图片来自coursera中Andrew Ng讲授的Machine Learning的课件
图2,经过参数组w映射后的logit函数。
*图片来自coursera中Andrew Ng讲授的Machine Learning的课件
我们会发现对于单个样本
, 他进过映射后(也就是
)成为
进入另一个坐标系(图1中画的那个坐标系)。我们看到对于
,在我们的寻找标准(也就是cost function)中,我们是希望这个训练样本
,如果它是正例(标记为1的样本,对应于图1中左边的坐标系),我们希望他进过映射后的
能够很大,以至于cost很小,接近于0;如果他是负例(标记为0的样本,对应于图1中右边的坐标系),我们希望它经过映射后的
能够很小,以至于cost很小,接近于0。单看某一个样本,调整参数组
,它自己的cost可以很小。但是我们是希望总体的cost即
(注意
是对所有样本的cost求和)最小。
对于某一个样本
,变化参数组
,它自身的cost可能变小很多,但是对于其他的样本,他们的cost也同时在变化。也就是说对于单个样本最好的参数组
,不一定是对于所有样本最好的参数组
。我们调整参数组
,就是希望样本映射后的
,在图2中正例尽量往右侧靠(它的p就非常接近1),负例尽量往左侧靠(它的p非常接近0)。[在图2中正例尽量往左侧靠(它的p就非常接近1),负例尽量往右侧靠(它的p非常接近0)。
感谢网友指出]具体做法,就是选择一组参数
,然后观察样本映射后的分布。然后按照最小化cost的标准去调整参数组
,使用调整后的
去映射样本,然后继续观察样本映射后的分布,继续调整下去.....
注意,当某一组参数
;,使得样本的判别全部正确(正例样本都分类为1,负例样本都分类为0
),此时的
也不一定的最优的。因为全部全别正确,只是说明映射后在图2中正例全部在右侧,负例全部在左侧。但此时可能不是往两端靠近。切记,我们找到的参数组
,是使得样本映射后的
总体往两端靠的最远。
实际使用时候需要注意:
1.样本的特征需要进行feature scaling
2.为了减轻过拟合带来的影响,需要对模型进行regularization。通常是总体样本的cost function加上一个小尾巴
。
参考博客:
1. http://hi.baidu.com/hehehehello/item/40025c33d7d9b7b9633aff87
2. http://52opencourse.com/125/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AC%AC%E5%85%AD%E8%AF%BE-%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92-logistic-regression
3. http://blog.csdn.net/abcjennifer/article/details/7716281
4. http://www.cnblogs.com/daniel-D/archive/2013/05/30/3109276.html

相关文章推荐
- 【学习笔记】斯坦福大学公开课(机器学习) 之逻辑斯蒂回归(续)
- Hinton Neural Networks课程笔记3c:学习逻辑斯蒂回归
- 逻辑斯蒂回归(logistic regression)学习笔记
- 【学习笔记】斯坦福大学公开课(机器学习) 之逻辑斯蒂回归
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 计算广告学习笔记 4.7竞价广告系统-逻辑回归优化方法介绍
- [TensorFlow]入门学习笔记(4)-BasicModel 线性回归,逻辑回归和最近邻模型
- sklearn学习笔记-逻辑回归LogisticRegression
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 线性回归、逻辑回归、cnn、lstm、faster-rcnn等等算法学习笔记
- Coursera吴恩达机器学习课程 总结笔记及作业代码——第3周逻辑回归
- 极大似然 S函数 逻辑回归 具体案例 学习笔记
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- Python学习笔记之逻辑回归
- Theano深度学习笔记(二)逻辑回归对MNIST分类
- TensorFlow深度学习笔记 逻辑回归 实践篇
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型