Android 4.4(KitKat)中的设计模式-Graphics子系统
2013-12-21 14:22
363 查看
原文地址:http://blog.csdn.net/jinzhuojun/article/details/17427491
本文主要从设计模式角度简单地侃下Android4.4(KitKat)的Graphics子系统。作为一个操作系统,Android需要考虑到灵活性,兼容性,可用性,可维护性等方方面面 ,为了达到这些需求,它需要良好的设计。因此,在Android源码中可以看到很多设计模式的身影。光是本文涉及的Graphics子系统中,就用到了如Observer, Proxy, Singleton, Command, Decorator, Strategy,
Adapter, Iterator和Simple Factory等模式。如果要学习设计模式,我想Android源代码是一个比较好的实例教材。当然很多用法和GoF书中的经典示例不一样,但其理念还是值得学习的。本文仍以大体流程为纲,在涉及到时穿插相应的设计模式。这样既涵盖了Android工作原理,又能一窥其设计理念,一举两得。这里本意是想自顶向下地展开,因为Android源代码庞大,很容易迷失在code的海洋中。本着divide-and-conquer的原则,本文重点先介绍SurfaceFlinger也就是服务端的工作流程,而对于应用程序端的App
UI部分留到以后再讲。
为了让分析不过于抽象,首先,让我们先找一个可以跑的实例为起点,使得分析更加有血有肉。这里选的是/frameworks/native/services/surfaceflinger/tests/resize/resize.cpp。选这个测试用例原因有几:一、它是一个Native程序,不牵扯它们在Java层的那一坨代理和Jni调用。二、麻雀虽小,五脏俱全,应用程序在Native层的主干它都有。三、程序无废话,简约而不简单,高端洋气上档次。注意这个用例默认编译有错的,不过好在对于码农们不是大问题,改发改发也就过了。
下面是该用例中最核心的几行,我们来看看这样简单的任务后面Android到底做了神马。
这儿的大概流程是先创建SurfaceComposerClient,再通过它创建SurfaceControl,再得到Surface,然后通过lock()分配图形缓冲区,接着把要渲染的东西(这里是简单的红色)画好后,用unlockAndPost()交给SurfaceFlinger去放到硬件缓冲区中,也就是画到屏幕上。最后结果是屏幕上应该能看到一个小红色块。这里先不急着挖代码,先放慢脚步直观地理解下这些概念。SurfaceComposer可以理解为SurfaceFlinger的别称,因为SurfaceFlinger主要就是用来做各个图层的Composition操作的。但SurfaceFlinger是在服务端的,作为应用程序要让它为之服务需要先生成它所对应的客户端,也就是SurfaceComposerClient,因为SurfaceComposerClient是懂得和服务端打交道的协议的。SurfaceComposerClient位于服务端的代理叫Client,应用程序通过前者发出的远程过程调用就是通过后者来实现的。有了它之后,应用程序就可以通过它来申请SurfaceFlinger为自己创建Surface,这个Surface就是要绘制的表面的抽象。去除次要元素,下图简要勾勒了这些类之间的总体结构:
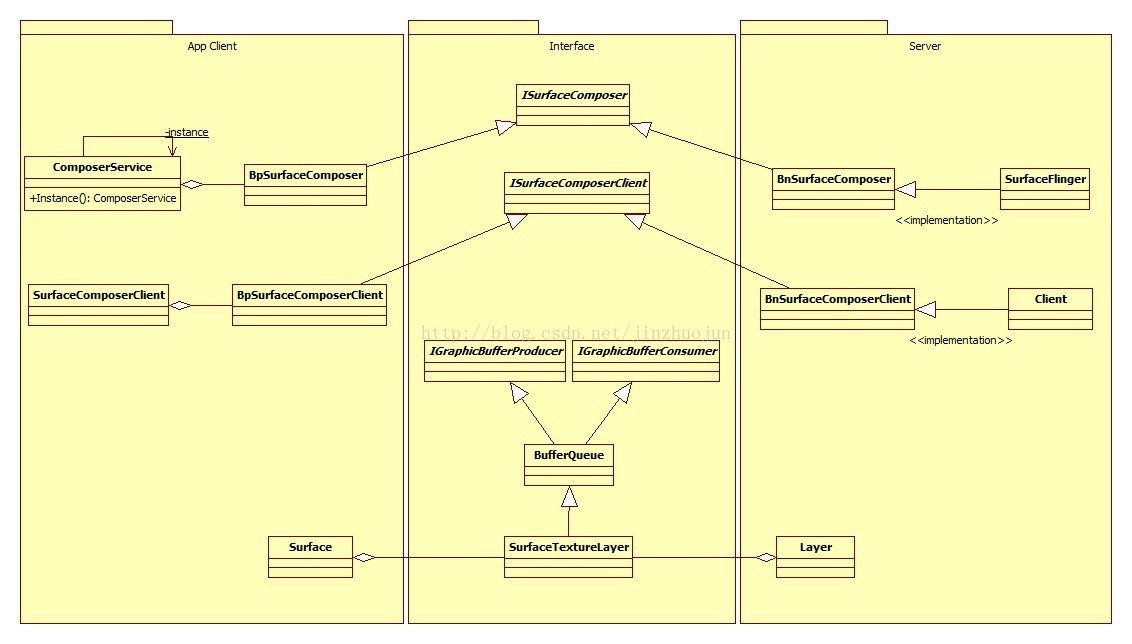
把这些个结构画出来后,优美而对称的C/S架构就跃然电脑上了。中间为接口层,两边的服务端和客户端(也就是应用程序)通过接口就可以相互通信。这样两边都可以做到设计中的“面向接口编程”。只要接口不变,两边实现怎么折腾都行。可以看到,应用程序要通过SurfaceFlinger将自己的内容渲染到屏幕上是一个客户端请求服务的过程。其中应用程序端为生产者,提供要渲染的图形缓冲区,SurfaceFlinger为消费者,拿图形缓冲区去合并渲染。从结构上来看,可以看到应用程序端的东西在服务端都有对应的对象。注意它们的生成顺序是由上到下的,即对于应用程序来说,先有ComposerService,再有SurfaceComposerClient,再有Surface;对于服务端来说,依次有SurfaceFlinger,Client和Layer。
这里至少看到两种设计模式 :Singleton和Proxy模式。当然用法可能和教科书中不一样,但是思想是一致的。ComposerService用来抽象SurfaceFlinger,SurfaceFlinger全局只有一个,所以ComposerService是Singleton对象。另一方面,应用程序想要让服务端为其做事,但服务端不在同一进程中,这就需要在服务端创建本地对象在服务端的代理(如Client),这就是Proxy模式了。Proxy模式应用很广,可用于远程对象访问(remote
proxy),虚拟化(virtual proxy),权限控制(protection
proxy)和智能指针(smart reference proxy)等。这里用的是remote
proxy(当然也有protection proxy的因素)。另外smart
reference proxy模式的例子如Android中的智能指针。
大体结构讲完,下面分步讲流程。首先,创建SurfaceComposerClient的流程见下面的序列图:
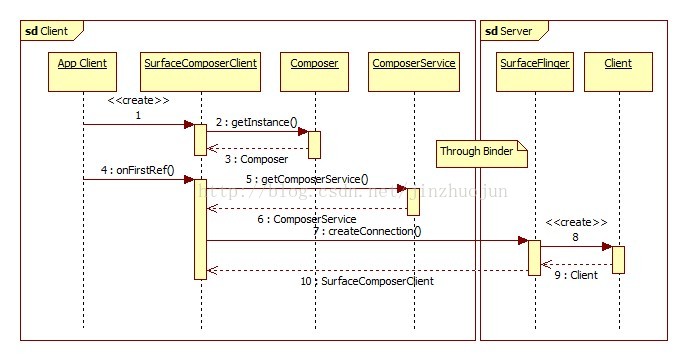
没啥亮点,一笔带过。前戏结束,下面进入正题,应用程序创建Surface过程如下:

挺直观的过程,细节从略。要注意的有几点:
一、客户端到服务端的调用都是通过Binder来进行的。如果不知道Binder是什么也没关系,只要把它看作一个面向系统级的IPC机制就行。上面在客户端和服务端之间很多的进程间过程调用就是用它来完成的。
二、现实中,像调用SurfaceFlinger的createLayer()函数这种并不那么直接,而是采用异步调用方式。这个一会再讲。
三、IGraphicBufferProducer,IGraphicBufferConsumer, BufferQueue, SurfaceTextureLayer这几个类是一脉相承的。所以图中当服务端创建一个SurfaceTextureLayer对象,传到客户端被转成IGraphicBufferProducer是完全OK的。这种面向接口编程的用法还有很多,其理论基础是里氏替换原则。这里也体现了接口隔离原则,同样的对象在客户端只暴露作为生产者的接口,而在服务端暴露消费者的接口,避免了接口污染。
那么上面的过程中用到了哪些设计模式呢?我觉得比较明显的有以下几个:
Proxy模式这里被用来解除环形引用和避免对象被回收。ConsumerBase先创建一个类型为BufferQueue::ConsumerListerner的对象listerner,然后再在外面包了层类型为QueueBuffer::ProxyConsumerListener的代理对象proxy,它拥有一个指向listerner的弱指针(因弱引用不影响回收)。一方面,加了这一层代理相当于把相互的强引用变成了单向的强引用,之所以这样做是为了避免对象间的环形引用导致难以回收。另一方面,如果用的强指针,那在ConsumerBase构造函数中,一旦函数结束,对于ConsumerListener(即ConsumerBase)的强引用就没有了,那么onLastStrongRef()就可能被调用,从而回收这个还有用的对象。前面我们看到Proxy模式在远程对象访问中的应用,这里我们看到了另一种用法。
Observer模式被用做在应用程序渲染完后提交给服务端时的通知机制。首先consumerConnect()会建立起BufferQueue到ConsumerBase对象的引用,放于成员变量mConsumerListener之中,接着setFrameAvailableListener()建立起ConsumerBase对象到Layer的引用。这样就形成了下面这样一个链式Observer模式:

注意虽是链式,但和Chain of Responsiblity模式没啥关系。注册完成之后,日后当应用程序处理完图形缓冲区后调用queueBuffer()时,BufferQueue就会调用这个listener的回调函数onFrameAvailable(),然后途经ConsumerBase调用Layer的回调函数onFrameAvailable(),最后调用signalLayerUpdate()使SurfaceFlinger得到通知。这样就使得SurfaceFlinger可以专心干自己的事,当有需求来时自然会被通知到。事实上,当被通知有新帧需要渲染时,SurfaceFlinger也不是马上停下手上的事,而是先做一个轻量级的处理,也就是把相应消息放入消息队列留到以后处理。这就使得各个应用程序和SurfaceFlinger可以异步工作,保证SurfaceFlinger的性能不被影响。而这又引入了下面的Command模式。
Command模式被用来使得SurfaceFlinger可以和其它模块异步工作。Command模式常被用来实现undo操作或是延迟处理,这里显然是用了后者。简单地概括下就是:当有消息来(如INVALIDATE消息),先把它通过MessageQueue存起来(实际是存在Looper里),然后SurfaceFlinger线程会不断去查询这个消息队列。如果队列不为空且约定处理时间已到,就会取出做相应处理。具体流程后面谈到SurfaceFlinger时再说。为什么要这么麻烦呢,主要还是要保证SurfaceFlinger的稳定和高效。消息可以随时过来,但SurfaceFlinger可以异步处理。这样就可以保证不打乱SurfaceFlinger那最摇摆的节奏,从而保证用户体验。
创建不同功能的BufferQueue使用的是类似于Builder的设计模式。当BufferQueue被创建出来后,它拥有默认的参数,客户端为把它打造成想要的BufferQueue,通过其接口设定一系列的参数即可,就像Wizard一样。为什么要这么做呢,先了解下背景知识。一个图形缓冲区从应用程序到屏幕的路上两个地方用到了BufferQueue。一个用来将应用程序渲染好的图形缓冲传给SurfaceFlinger,另一个用来把SurfaceFlinger合成好的图形缓冲放到硬件图形缓冲区上。

BufferQueue中核心数据是一个GraphicBuffer的队列。而GraphicBuffer根据使用场合的不同可以从共享内存(即Ashmem,因为这块内存要在应用程序和服务端程序两个进程间共享)或者从硬件图形缓冲区(即Framebuffer,因为它是SurfaceFlinger渲染完要放到屏幕上的)中分配。另外因为用途不同,它的格式,大小,以及在BufferQueue中的数量都可能是不同的。虽然是同一个类,用于不同场合出身就不同,那又怎么区分哪个是高富帅,哪个是矮穷挫呢。很简单,当BufferQueue被创建出来之后,由Layer或是FramebufferSurface来充当导演的角色,打造相应的BufferQueue。它们调用一系列的函数(如setConsumerUsageBits()和setDefaultMaxBufferCount()等)将构建出来的BufferQueue变得适用于自己。
另外,Adapter和Decorator模式在代码中也经常会出现。从目的上讲,由于被调用者提供的接口或功能常常不能满足调用者的需求,如果是接口不满足就用Adapter模式,如果要增加额外功能就用Decorator模式。从结构上讲,Adapter可以是Subclassing结构也可以是Composition结构,而Decorator一般是Composition结构。事实上这两个模式经常混在一起用。实用中我觉得没必要太在意到底是什么模式,能起到作用就行。举例来说,SurfaceFlingerConsumer是GLConsumer的Wrapper,当Layer调用SurfaceFlingerConsumer的接口,底层会部分使用GLConsumer的相应实现(事实上SurfaceFlingerConsumer和GLConsumer实现中有重复代码)。我觉得它是用了subclassing结构来达到了类似Decorator模式的目的。当然这里模式用得不是很清晰,只是借机引下相关模式,例子跳过也罢。
回到我们的测试用例主线上,现在应用程序中Surface创建好了,下面几行主要功能是把应用程序所绘图层的z轴值设得很大,也就是很牛逼肯定能看到的地方。
像这种更改屏幕或是应用程序窗口属性的动作需要用openGlobalTransaction()和closeGlobalTransaction()包起来,这样中间的更改操作就成为一个事务。事务中的操作暂时只在本地,只有当closeGlobalTransaction()被调用时才一起通过Binder发给SurfaceFlinger处理。这主要是由另一个Singleton对象Compoesr来实现的。属性改变的事务化优化了系统资源,因为更改这些属性的操作往往很heavy,意味着很多东西需要重新计算,所以这里把这些费时操作打了一个包,避免重复劳动。由于这块并不复杂也不是重点,而且部分流程和后面重复,所以就跳过直接进入高潮
- 写图形缓冲区和交由SurfaceFlinger合成输出到屏幕。让我们看看下面这几行背后都做了些什么:
代码首先定义了图形缓冲区,它就是应用程序用来画图的缓冲区了。但这里只有元信息,放绘制数据的地方还没分配出来。先看下面这两行绘制缓冲区的语句,它们的目的很简单,就是把图形缓冲区整成红色。注意Surface格式是PIXEL_FORMAT_RGB_565,所以红色对应0xF800。
绘制缓冲区前后分别用lock()和unlockAndPost()包起来,这两个函数主要用途是向服务端申请图形缓冲区,再把绘制好的图形缓冲区交给SurfaceFlinger处理。大体流程如下:
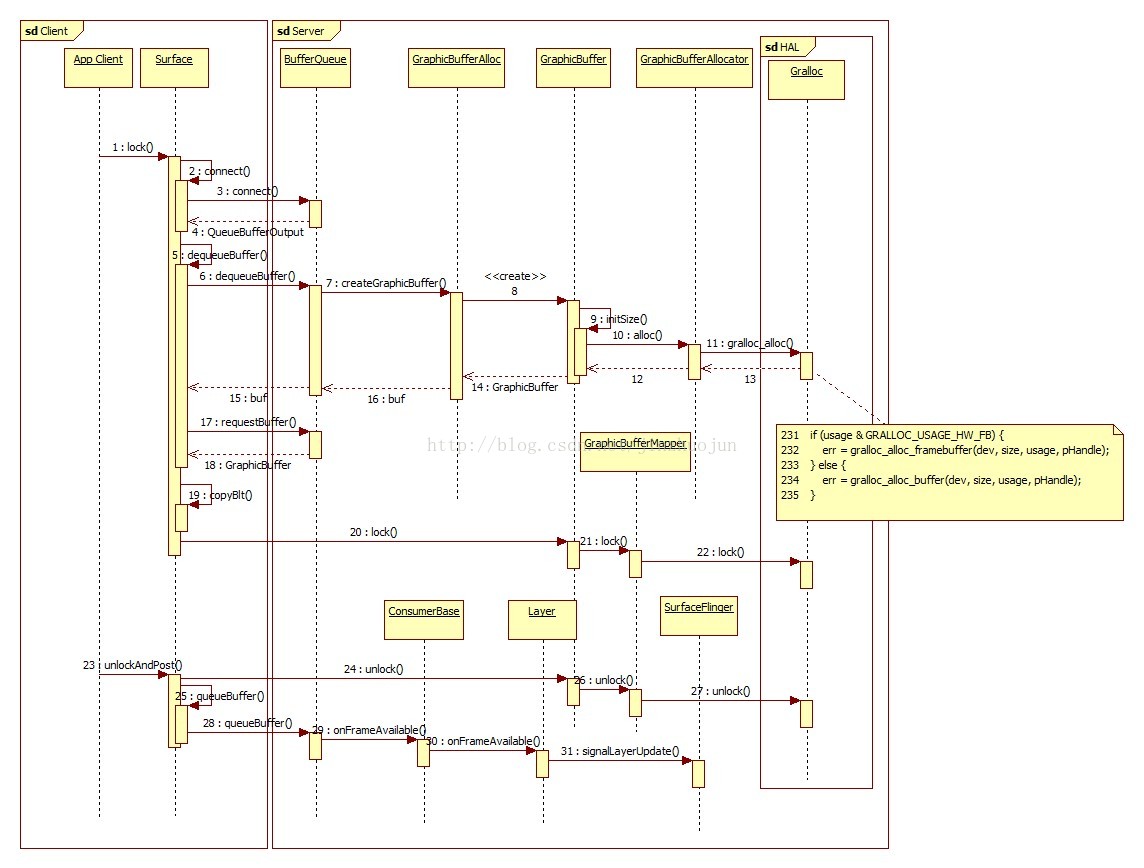
这样应用程序就把自己渲染好的图形缓冲区华丽丽地交给SurfaceFlinger了。其中最主要的是图形缓冲区的传递处理,图形缓冲区对应的类为GraphicBuffer。BufferQueue为它的缓冲队列,可以看作是一个元素为GraphicBuffer的队列。插播下背景知识,BufferQueue中的GraphicBuffer有以下几种状态,之间的转换关系如下:

这部分用到的设计模式主要有以下几个:
Memento模式。从BufferQueue传回的GraphicBuffer是在共享内存中分配的,而这块内存又是用句柄来表示的。我们知道一个进程的句柄或地址到另一个进程中就不一定合法了。那么为什么Surface的lock()函数拿到这个GraphicBuffer后就直接拿来当本地对象用了呢。这里就要引入Memento模式了。GraphicBuffer继承了Flattenable类,实现了flatten()和unflatten函数。当GraphicBuffer被从进程A经由Binder传递到进程B时,先在进程A中它的flatten()函数被调用,再在进程B中unflatten()函数被调用。这样就可以保证GraphicBuffer跨进程后仍然有效。简要地看下flatten()和unflatten()的实现。服务端在传递GraphicBuffer前调用flatten()函数把GraphicBuffer的基本信息存在结构体中,应用程序端拿到后调用unflatten()将这个结构体拿出来后调用GraphicBufferMapper::registerBuffer()(它接着会调用gralloc模块中的gralloc_register_buffer(),接着调用gralloc_map(),最后用mmap()完成映射)将远端GraphicBuffer映射到本地地址空间,然后据此在BpGraphicBufferProducer::requestBuffer()中重新构建了一个GraphicBuffer。这样应用程序端和服务端中的GraphicBuffer就被映射到了同一块物理空间,达到了共享的目的,而且对于上层应用这个转化的过程完全是透明的。QueueBufferOutput和QueueBufferInput的处理与GraphicBuffer的处理目的相同,都是进程间传递对象,不同之处在于前两者相当于在另一个进程中拷贝了一份。因为它们只包含少量POD成员,所以拷贝对性能影响不大。
Iterator模式在Android源码中也很散落地应用着。如Surface::lock()中,为了使得frontBuffer可以重用(图形渲染一般采用双缓冲,frontBuffer用于显示输出,backBuffer用于作图,这样两者可以同时进行互不影响。很多时候其实下一帧和前一帧比只有一小块是需要重新渲染的,如切水果时很多时候其实就水果周围一块区域需要重渲染,这块区域即为脏区域),我们需要知道脏区域。脏区域信息用Region表示。而Region本身是由多个矩形组成的,而作为客户端要访问Region中的这些矩形,不需要知道它们的内在实现。这样在访问这个脏区域时就可以这么写:
这样客户端的代码就不依赖于Region的实现了,无论Region中是数组也好,队列也好,上层代码不变,无比优美。同理还有BufferQueue::queueBuffer()中用到的Fifo::iterator等。
Strategy模式用于让系统可以优雅地适应不同平台中的HAL模块。尽管这儿部分代码是用C写的,和标准的Strategy用法略有不同,但精神是一样的。举例来说,由于gralloc模块是平台相关的,在不同平台有不同的实现。那么作为上层客户端,如GraphicBufferMapper来说,它不希望依赖于这种变化。于是要求所有平台提供的gralloc模块提供统一的接口,而这个接口对应的对象的符号统一为HAL_MODULE_INFO_SYM。这样不管是哪个平台,上层客户端就只要用dlopen()和dlsym()去载入和查询这个结构体就可以得到这些接口相应的实现了(载入流程见hw_get_module()
->hw_get_module_by_class() -> load())。这里涉及到的是gralloc_module_t接口,也就是GraphicBufferMapper要用到的接口,各个平台提供的gralloc都要实现这个接口。同理的还有对同在HAL层的hwcomposer模块的处理。
另外,我们还看到了前面提到过的设计模式又一次次地出现,如死亡通知是基于Binder的Observer模式,另外GraphicBufferMapper对gralloc模块gralloc_module_t的封装可看作是Adapter模式的应用。
回到主线,前面的流程进行到Layer调用signalLayerUpdate()通知SurfaceFlinger就结束了。下面分析下SurfaceFlinger的流程及对于应用程序图形缓冲区的后续处理过程。为了让文章看起来更加完整些,我们还是从SurfaceFlinger的初始化开始,然后再接着讲那signalLayerUpdate()之后的故事。这里就从SurfaceFlinger的创建开始讲起吧。本来SurfaceFlinger有两种启动方式,由SystemServer以线程方式启动,或是由init以进程方式启动。不过Android
4.4上好像前者去掉了,反正我是没找到。。。。那故事就从main_surfaceflinger.cpp讲起吧。

上半部分是SurfaceFlinger的初始化,下半部分是SurfaceFlinger对于VSync信号的处理,也就是一次合并渲染的过程。由于代码里分支较多,为了说明简便,这里作了几点假设:首先假设平台支持硬件VSync信号,这样就不会创建VSyncThread来用软件模拟了。另外假设INVALIDATE_ON_VSYNC为1,也就是把INVALIDATE操作放到VSync信号来时再做。值得注意的是SurfaceFlinger线程模型相较之前版本有了较大变化,主要原因是引入了VSync的虚拟化。相关的线程有EventThread(vsyncSrc),
EventThread(sfVsyncSrc), EventControlThread和DispSyncThread。这个东西比较好玩,所以单独放一篇文章来讲(http://blog.csdn.net/jinzhuojun/article/details/17293325)。
先粗略介绍下几个重要类的基本作用:
EventControlThread是一个简单地另人发指的线程,用来根据标志位开关硬件VSync信号。
RenderEngine是对一坨egl和gl函数的封装。引入它可能是觉得egl和gl函数混杂在其它模块中里看起来太乱了。它把GL相关的东西封装起来了,只暴露出GL无关的接口,这样SurfaceFlinger等模块作为客户端不需要了解底层细节。
Looper是一个通用的类,负责将事件和消息存成队列,并提供轮询接口处理队列中的事件和消息。在这里主要用于处理TRANSACTION,
INVALIDATE和REFRESH消息以及VSync事件。
MessageQueue主要操作Looper。由于Looper不是专用于SurfaceFlinger的,MessageQueue封装了一些SurfaceFlinger专用的信息,使得EventThread和SurfaceFlinger等模块可以通过它来间接使用Looper类。
SurfaceFlinger,DisplayDevice,FramebufferSurface和HWComposer这几个类之间的关系比较暧昧。SurfaceFlinger是这部分里最大的客户端。DisplayDevice抽象了显示设备,封装了用于渲染的Surface和HWComposer模块等,从而尽可能使得SurfaceFlinger只要和它打交道。FramebufferSurface抽象了SurfaceFlinger用来画图的Surface,该Surface对应一个BufferQueue用于多缓冲渲染。它和之前提到的应用端用到的Surface区别在于它是基于硬件图形缓冲区的,而不是Ashmem。HWComposer封装了两个重要的HAL模块,即framebuffer和hwcomposer,前者对应硬件缓冲区,后者对应hwcomposer硬件。hwcomposer控制VSync信号,管理屏幕信息和操作framebuffer。HWComposer主要工作是负责将平台相关的HAL模块加载好,并且使得上层模块通过它来使用HAL模块。注意两个容易混淆的概念:HWComposer是类,肯定会有;hwcomposer是硬件模块,在某些平台可能会不可用。这几个类的大致结构如下:

SurfaceFlinger的渲染工作主要是由VSync信号驱动的。EventThread负责发出虚拟VSync信号(由硬件VSync信号偏移指定相位虚拟化得到)。初始化时,MessageQueue在setEventThread()函数中先与EventThread建立连接,然后将与EventThread之间通信的socket(BitTube)句柄注册进Looper,同时也注册了自己的回调函数。另一方面,SurfaceFlinger会通过Looper不断轮询这个句柄,看该句柄上有没有数据。当在该句柄上接收到数据,就会调用MessageQueue相应的回调函数。经过一番处理后,最后MessageQueue的Handler基于收到的消息调用到SurfaceFlinger的相应处理函数。就这样,EventThread->Looper->MessageQueue->SurfaceFlinger的事件消息传递过程形成了。
这里又看到了比较熟悉的设计模式,如Iterator模式用于遍历所有图层(HWComposer::LayerListIterator),
Observer模式用于虚拟VSync信号线程向DispSyncThread申请虚拟VSync事件(DispSyncThread::EventListener),还有前面提到过的Command模式用于消息的延迟处理(postMessageAsync())。
除了这些熟悉的身影外,我们还能看到些新面孔。如RenderEngine::create()应用了简单工厂模式,它根据GLES版本号创建相应的RenderEngine。这样,作为RenderEngine的使用者SurfaceFlinger和Layer自然就成了Strategy模式的受益者,它们不用关心RenderEngine在各个不同版本间实现的差异。还有Mediator模式在Service管理中的应用。SurfaceFlinger进程中,addService()函数向Service
Manager注册了SurfaceFlinger服务。这样Service Manager作为中介的角色在Client和Service之间做沟通,它使得一个网状的模块结构变成了一个优美的星形结构。当然在这里因为就一个服务看不出来,因此这个另作章节再讲。
可以看到,当VSync信号到来时,SurfaceFlinger最主要是通过处理INVALIDATE和REFRESH消息来做合并渲染和输出的工作的。这里的核心思想是能少处理一点是一点,所以在渲染前有很多脏区域的计算工作,这样后面只要处理那些区域的更新就可以了。这样是有现实意义的,一方面由于图层间的遮盖,有些不可见图层不需要渲染。另一方面,因为我们的应用程序中前后帧一般只有一小部分变化,要是每帧都全变估计人都要看吐了。这里主要是调用了这几个函数:
handleMessageTransaction()主要处理之前对屏幕和应用程序窗口的改动。因这些改动很有可能会改变图层的可见区域,进而影响脏区域的计算。
handleMessageInvalidate()主要调用handlePageFlip()函数。这里Page
Flip是指从BufferQueue中取下一个图形缓冲区内容,就好像是“翻页”一样。该函数主要是从各Layer对应的BufferQueue中拿图形缓冲区数据,并根据内容更新脏区域。
handleMessageRefresh()就是合并和渲染输出了。作为重头戏,这步步骤多一些,大体框架如下:

文章一开始的测试用例主干部分背后的故事大概就这么些了。篇幅有限,省略了很多细节。我们可以看到,在服务端做了这么多的事,而对于应用程序来说只要先lock(),再填buffer,最后unlockAndPost()就OK了。这也算是Facade模式的体现了吧。
总结地说,从Android源码中我们可以温习到应用设计模式的基本原则:一是只在合适的地方用。很多时候我们学习设计模式恰恰是为了不用,准确地说是不滥用。二是要用的话不需要过于拘泥于原有的或经典的用法,以解决问题为目的适当自由发挥。
本文主要从设计模式角度简单地侃下Android4.4(KitKat)的Graphics子系统。作为一个操作系统,Android需要考虑到灵活性,兼容性,可用性,可维护性等方方面面 ,为了达到这些需求,它需要良好的设计。因此,在Android源码中可以看到很多设计模式的身影。光是本文涉及的Graphics子系统中,就用到了如Observer, Proxy, Singleton, Command, Decorator, Strategy,
Adapter, Iterator和Simple Factory等模式。如果要学习设计模式,我想Android源代码是一个比较好的实例教材。当然很多用法和GoF书中的经典示例不一样,但其理念还是值得学习的。本文仍以大体流程为纲,在涉及到时穿插相应的设计模式。这样既涵盖了Android工作原理,又能一窥其设计理念,一举两得。这里本意是想自顶向下地展开,因为Android源代码庞大,很容易迷失在code的海洋中。本着divide-and-conquer的原则,本文重点先介绍SurfaceFlinger也就是服务端的工作流程,而对于应用程序端的App
UI部分留到以后再讲。
为了让分析不过于抽象,首先,让我们先找一个可以跑的实例为起点,使得分析更加有血有肉。这里选的是/frameworks/native/services/surfaceflinger/tests/resize/resize.cpp。选这个测试用例原因有几:一、它是一个Native程序,不牵扯它们在Java层的那一坨代理和Jni调用。二、麻雀虽小,五脏俱全,应用程序在Native层的主干它都有。三、程序无废话,简约而不简单,高端洋气上档次。注意这个用例默认编译有错的,不过好在对于码农们不是大问题,改发改发也就过了。
下面是该用例中最核心的几行,我们来看看这样简单的任务后面Android到底做了神马。
39 sp<SurfaceComposerClient> client = new SurfaceComposerClient();
40
41 sp<SurfaceControl> surfaceControl = client->createSurface(String8("resize"),
42 160, 240, PIXEL_FORMAT_RGB_565, 0);
43
44 sp<Surface> surface = surfaceControl->getSurface();
45
46 SurfaceComposerClient::openGlobalTransaction();
47 surfaceControl->setLayer(100000);
48 SurfaceComposerClient::closeGlobalTransaction();
49
50 ANativeWindow_Buffer outBuffer;
51 surface->lock(&outBuffer, NULL);
52 ssize_t bpr = outBuffer.stride * bytesPerPixel(outBuffer.format);
53 android_memset16((uint16_t*)outBuffer.bits, 0xF800, bpr*outBuffer.height);
54 surface->unlockAndPost();这儿的大概流程是先创建SurfaceComposerClient,再通过它创建SurfaceControl,再得到Surface,然后通过lock()分配图形缓冲区,接着把要渲染的东西(这里是简单的红色)画好后,用unlockAndPost()交给SurfaceFlinger去放到硬件缓冲区中,也就是画到屏幕上。最后结果是屏幕上应该能看到一个小红色块。这里先不急着挖代码,先放慢脚步直观地理解下这些概念。SurfaceComposer可以理解为SurfaceFlinger的别称,因为SurfaceFlinger主要就是用来做各个图层的Composition操作的。但SurfaceFlinger是在服务端的,作为应用程序要让它为之服务需要先生成它所对应的客户端,也就是SurfaceComposerClient,因为SurfaceComposerClient是懂得和服务端打交道的协议的。SurfaceComposerClient位于服务端的代理叫Client,应用程序通过前者发出的远程过程调用就是通过后者来实现的。有了它之后,应用程序就可以通过它来申请SurfaceFlinger为自己创建Surface,这个Surface就是要绘制的表面的抽象。去除次要元素,下图简要勾勒了这些类之间的总体结构:
把这些个结构画出来后,优美而对称的C/S架构就跃然电脑上了。中间为接口层,两边的服务端和客户端(也就是应用程序)通过接口就可以相互通信。这样两边都可以做到设计中的“面向接口编程”。只要接口不变,两边实现怎么折腾都行。可以看到,应用程序要通过SurfaceFlinger将自己的内容渲染到屏幕上是一个客户端请求服务的过程。其中应用程序端为生产者,提供要渲染的图形缓冲区,SurfaceFlinger为消费者,拿图形缓冲区去合并渲染。从结构上来看,可以看到应用程序端的东西在服务端都有对应的对象。注意它们的生成顺序是由上到下的,即对于应用程序来说,先有ComposerService,再有SurfaceComposerClient,再有Surface;对于服务端来说,依次有SurfaceFlinger,Client和Layer。
这里至少看到两种设计模式 :Singleton和Proxy模式。当然用法可能和教科书中不一样,但是思想是一致的。ComposerService用来抽象SurfaceFlinger,SurfaceFlinger全局只有一个,所以ComposerService是Singleton对象。另一方面,应用程序想要让服务端为其做事,但服务端不在同一进程中,这就需要在服务端创建本地对象在服务端的代理(如Client),这就是Proxy模式了。Proxy模式应用很广,可用于远程对象访问(remote
proxy),虚拟化(virtual proxy),权限控制(protection
proxy)和智能指针(smart reference proxy)等。这里用的是remote
proxy(当然也有protection proxy的因素)。另外smart
reference proxy模式的例子如Android中的智能指针。
大体结构讲完,下面分步讲流程。首先,创建SurfaceComposerClient的流程见下面的序列图:
没啥亮点,一笔带过。前戏结束,下面进入正题,应用程序创建Surface过程如下:
挺直观的过程,细节从略。要注意的有几点:
一、客户端到服务端的调用都是通过Binder来进行的。如果不知道Binder是什么也没关系,只要把它看作一个面向系统级的IPC机制就行。上面在客户端和服务端之间很多的进程间过程调用就是用它来完成的。
二、现实中,像调用SurfaceFlinger的createLayer()函数这种并不那么直接,而是采用异步调用方式。这个一会再讲。
三、IGraphicBufferProducer,IGraphicBufferConsumer, BufferQueue, SurfaceTextureLayer这几个类是一脉相承的。所以图中当服务端创建一个SurfaceTextureLayer对象,传到客户端被转成IGraphicBufferProducer是完全OK的。这种面向接口编程的用法还有很多,其理论基础是里氏替换原则。这里也体现了接口隔离原则,同样的对象在客户端只暴露作为生产者的接口,而在服务端暴露消费者的接口,避免了接口污染。
那么上面的过程中用到了哪些设计模式呢?我觉得比较明显的有以下几个:
Proxy模式这里被用来解除环形引用和避免对象被回收。ConsumerBase先创建一个类型为BufferQueue::ConsumerListerner的对象listerner,然后再在外面包了层类型为QueueBuffer::ProxyConsumerListener的代理对象proxy,它拥有一个指向listerner的弱指针(因弱引用不影响回收)。一方面,加了这一层代理相当于把相互的强引用变成了单向的强引用,之所以这样做是为了避免对象间的环形引用导致难以回收。另一方面,如果用的强指针,那在ConsumerBase构造函数中,一旦函数结束,对于ConsumerListener(即ConsumerBase)的强引用就没有了,那么onLastStrongRef()就可能被调用,从而回收这个还有用的对象。前面我们看到Proxy模式在远程对象访问中的应用,这里我们看到了另一种用法。
Observer模式被用做在应用程序渲染完后提交给服务端时的通知机制。首先consumerConnect()会建立起BufferQueue到ConsumerBase对象的引用,放于成员变量mConsumerListener之中,接着setFrameAvailableListener()建立起ConsumerBase对象到Layer的引用。这样就形成了下面这样一个链式Observer模式:
注意虽是链式,但和Chain of Responsiblity模式没啥关系。注册完成之后,日后当应用程序处理完图形缓冲区后调用queueBuffer()时,BufferQueue就会调用这个listener的回调函数onFrameAvailable(),然后途经ConsumerBase调用Layer的回调函数onFrameAvailable(),最后调用signalLayerUpdate()使SurfaceFlinger得到通知。这样就使得SurfaceFlinger可以专心干自己的事,当有需求来时自然会被通知到。事实上,当被通知有新帧需要渲染时,SurfaceFlinger也不是马上停下手上的事,而是先做一个轻量级的处理,也就是把相应消息放入消息队列留到以后处理。这就使得各个应用程序和SurfaceFlinger可以异步工作,保证SurfaceFlinger的性能不被影响。而这又引入了下面的Command模式。
Command模式被用来使得SurfaceFlinger可以和其它模块异步工作。Command模式常被用来实现undo操作或是延迟处理,这里显然是用了后者。简单地概括下就是:当有消息来(如INVALIDATE消息),先把它通过MessageQueue存起来(实际是存在Looper里),然后SurfaceFlinger线程会不断去查询这个消息队列。如果队列不为空且约定处理时间已到,就会取出做相应处理。具体流程后面谈到SurfaceFlinger时再说。为什么要这么麻烦呢,主要还是要保证SurfaceFlinger的稳定和高效。消息可以随时过来,但SurfaceFlinger可以异步处理。这样就可以保证不打乱SurfaceFlinger那最摇摆的节奏,从而保证用户体验。
创建不同功能的BufferQueue使用的是类似于Builder的设计模式。当BufferQueue被创建出来后,它拥有默认的参数,客户端为把它打造成想要的BufferQueue,通过其接口设定一系列的参数即可,就像Wizard一样。为什么要这么做呢,先了解下背景知识。一个图形缓冲区从应用程序到屏幕的路上两个地方用到了BufferQueue。一个用来将应用程序渲染好的图形缓冲传给SurfaceFlinger,另一个用来把SurfaceFlinger合成好的图形缓冲放到硬件图形缓冲区上。
BufferQueue中核心数据是一个GraphicBuffer的队列。而GraphicBuffer根据使用场合的不同可以从共享内存(即Ashmem,因为这块内存要在应用程序和服务端程序两个进程间共享)或者从硬件图形缓冲区(即Framebuffer,因为它是SurfaceFlinger渲染完要放到屏幕上的)中分配。另外因为用途不同,它的格式,大小,以及在BufferQueue中的数量都可能是不同的。虽然是同一个类,用于不同场合出身就不同,那又怎么区分哪个是高富帅,哪个是矮穷挫呢。很简单,当BufferQueue被创建出来之后,由Layer或是FramebufferSurface来充当导演的角色,打造相应的BufferQueue。它们调用一系列的函数(如setConsumerUsageBits()和setDefaultMaxBufferCount()等)将构建出来的BufferQueue变得适用于自己。
另外,Adapter和Decorator模式在代码中也经常会出现。从目的上讲,由于被调用者提供的接口或功能常常不能满足调用者的需求,如果是接口不满足就用Adapter模式,如果要增加额外功能就用Decorator模式。从结构上讲,Adapter可以是Subclassing结构也可以是Composition结构,而Decorator一般是Composition结构。事实上这两个模式经常混在一起用。实用中我觉得没必要太在意到底是什么模式,能起到作用就行。举例来说,SurfaceFlingerConsumer是GLConsumer的Wrapper,当Layer调用SurfaceFlingerConsumer的接口,底层会部分使用GLConsumer的相应实现(事实上SurfaceFlingerConsumer和GLConsumer实现中有重复代码)。我觉得它是用了subclassing结构来达到了类似Decorator模式的目的。当然这里模式用得不是很清晰,只是借机引下相关模式,例子跳过也罢。
回到我们的测试用例主线上,现在应用程序中Surface创建好了,下面几行主要功能是把应用程序所绘图层的z轴值设得很大,也就是很牛逼肯定能看到的地方。
46 SurfaceComposerClient::openGlobalTransaction(); 47 surfaceControl->setLayer(100000); 48 SurfaceComposerClient::closeGlobalTransaction();
像这种更改屏幕或是应用程序窗口属性的动作需要用openGlobalTransaction()和closeGlobalTransaction()包起来,这样中间的更改操作就成为一个事务。事务中的操作暂时只在本地,只有当closeGlobalTransaction()被调用时才一起通过Binder发给SurfaceFlinger处理。这主要是由另一个Singleton对象Compoesr来实现的。属性改变的事务化优化了系统资源,因为更改这些属性的操作往往很heavy,意味着很多东西需要重新计算,所以这里把这些费时操作打了一个包,避免重复劳动。由于这块并不复杂也不是重点,而且部分流程和后面重复,所以就跳过直接进入高潮
- 写图形缓冲区和交由SurfaceFlinger合成输出到屏幕。让我们看看下面这几行背后都做了些什么:
50 ANativeWindow_Buffer outBuffer; 51 surface->lock(&outBuffer, NULL); 52 ssize_t bpr = outBuffer.stride * bytesPerPixel(outBuffer.format); 53 android_memset16((uint16_t*)outBuffer.bits, 0xF800, bpr*outBuffer.height); 54 surface->unlockAndPost();
代码首先定义了图形缓冲区,它就是应用程序用来画图的缓冲区了。但这里只有元信息,放绘制数据的地方还没分配出来。先看下面这两行绘制缓冲区的语句,它们的目的很简单,就是把图形缓冲区整成红色。注意Surface格式是PIXEL_FORMAT_RGB_565,所以红色对应0xF800。
52 ssize_t bpr = outBuffer.stride * bytesPerPixel(outBuffer.format); 53 android_memset16((uint16_t*)outBuffer.bits, 0xF800, bpr*outBuffer.height);
绘制缓冲区前后分别用lock()和unlockAndPost()包起来,这两个函数主要用途是向服务端申请图形缓冲区,再把绘制好的图形缓冲区交给SurfaceFlinger处理。大体流程如下:
这样应用程序就把自己渲染好的图形缓冲区华丽丽地交给SurfaceFlinger了。其中最主要的是图形缓冲区的传递处理,图形缓冲区对应的类为GraphicBuffer。BufferQueue为它的缓冲队列,可以看作是一个元素为GraphicBuffer的队列。插播下背景知识,BufferQueue中的GraphicBuffer有以下几种状态,之间的转换关系如下:
这部分用到的设计模式主要有以下几个:
Memento模式。从BufferQueue传回的GraphicBuffer是在共享内存中分配的,而这块内存又是用句柄来表示的。我们知道一个进程的句柄或地址到另一个进程中就不一定合法了。那么为什么Surface的lock()函数拿到这个GraphicBuffer后就直接拿来当本地对象用了呢。这里就要引入Memento模式了。GraphicBuffer继承了Flattenable类,实现了flatten()和unflatten函数。当GraphicBuffer被从进程A经由Binder传递到进程B时,先在进程A中它的flatten()函数被调用,再在进程B中unflatten()函数被调用。这样就可以保证GraphicBuffer跨进程后仍然有效。简要地看下flatten()和unflatten()的实现。服务端在传递GraphicBuffer前调用flatten()函数把GraphicBuffer的基本信息存在结构体中,应用程序端拿到后调用unflatten()将这个结构体拿出来后调用GraphicBufferMapper::registerBuffer()(它接着会调用gralloc模块中的gralloc_register_buffer(),接着调用gralloc_map(),最后用mmap()完成映射)将远端GraphicBuffer映射到本地地址空间,然后据此在BpGraphicBufferProducer::requestBuffer()中重新构建了一个GraphicBuffer。这样应用程序端和服务端中的GraphicBuffer就被映射到了同一块物理空间,达到了共享的目的,而且对于上层应用这个转化的过程完全是透明的。QueueBufferOutput和QueueBufferInput的处理与GraphicBuffer的处理目的相同,都是进程间传递对象,不同之处在于前两者相当于在另一个进程中拷贝了一份。因为它们只包含少量POD成员,所以拷贝对性能影响不大。
Iterator模式在Android源码中也很散落地应用着。如Surface::lock()中,为了使得frontBuffer可以重用(图形渲染一般采用双缓冲,frontBuffer用于显示输出,backBuffer用于作图,这样两者可以同时进行互不影响。很多时候其实下一帧和前一帧比只有一小块是需要重新渲染的,如切水果时很多时候其实就水果周围一块区域需要重渲染,这块区域即为脏区域),我们需要知道脏区域。脏区域信息用Region表示。而Region本身是由多个矩形组成的,而作为客户端要访问Region中的这些矩形,不需要知道它们的内在实现。这样在访问这个脏区域时就可以这么写:
Region::const_iterator head(reg.begin());
Region::const_iterator tail(reg.end());
while (head != tail) {
…
}这样客户端的代码就不依赖于Region的实现了,无论Region中是数组也好,队列也好,上层代码不变,无比优美。同理还有BufferQueue::queueBuffer()中用到的Fifo::iterator等。
Strategy模式用于让系统可以优雅地适应不同平台中的HAL模块。尽管这儿部分代码是用C写的,和标准的Strategy用法略有不同,但精神是一样的。举例来说,由于gralloc模块是平台相关的,在不同平台有不同的实现。那么作为上层客户端,如GraphicBufferMapper来说,它不希望依赖于这种变化。于是要求所有平台提供的gralloc模块提供统一的接口,而这个接口对应的对象的符号统一为HAL_MODULE_INFO_SYM。这样不管是哪个平台,上层客户端就只要用dlopen()和dlsym()去载入和查询这个结构体就可以得到这些接口相应的实现了(载入流程见hw_get_module()
->hw_get_module_by_class() -> load())。这里涉及到的是gralloc_module_t接口,也就是GraphicBufferMapper要用到的接口,各个平台提供的gralloc都要实现这个接口。同理的还有对同在HAL层的hwcomposer模块的处理。
另外,我们还看到了前面提到过的设计模式又一次次地出现,如死亡通知是基于Binder的Observer模式,另外GraphicBufferMapper对gralloc模块gralloc_module_t的封装可看作是Adapter模式的应用。
回到主线,前面的流程进行到Layer调用signalLayerUpdate()通知SurfaceFlinger就结束了。下面分析下SurfaceFlinger的流程及对于应用程序图形缓冲区的后续处理过程。为了让文章看起来更加完整些,我们还是从SurfaceFlinger的初始化开始,然后再接着讲那signalLayerUpdate()之后的故事。这里就从SurfaceFlinger的创建开始讲起吧。本来SurfaceFlinger有两种启动方式,由SystemServer以线程方式启动,或是由init以进程方式启动。不过Android
4.4上好像前者去掉了,反正我是没找到。。。。那故事就从main_surfaceflinger.cpp讲起吧。
上半部分是SurfaceFlinger的初始化,下半部分是SurfaceFlinger对于VSync信号的处理,也就是一次合并渲染的过程。由于代码里分支较多,为了说明简便,这里作了几点假设:首先假设平台支持硬件VSync信号,这样就不会创建VSyncThread来用软件模拟了。另外假设INVALIDATE_ON_VSYNC为1,也就是把INVALIDATE操作放到VSync信号来时再做。值得注意的是SurfaceFlinger线程模型相较之前版本有了较大变化,主要原因是引入了VSync的虚拟化。相关的线程有EventThread(vsyncSrc),
EventThread(sfVsyncSrc), EventControlThread和DispSyncThread。这个东西比较好玩,所以单独放一篇文章来讲(http://blog.csdn.net/jinzhuojun/article/details/17293325)。
先粗略介绍下几个重要类的基本作用:
EventControlThread是一个简单地另人发指的线程,用来根据标志位开关硬件VSync信号。
RenderEngine是对一坨egl和gl函数的封装。引入它可能是觉得egl和gl函数混杂在其它模块中里看起来太乱了。它把GL相关的东西封装起来了,只暴露出GL无关的接口,这样SurfaceFlinger等模块作为客户端不需要了解底层细节。
Looper是一个通用的类,负责将事件和消息存成队列,并提供轮询接口处理队列中的事件和消息。在这里主要用于处理TRANSACTION,
INVALIDATE和REFRESH消息以及VSync事件。
MessageQueue主要操作Looper。由于Looper不是专用于SurfaceFlinger的,MessageQueue封装了一些SurfaceFlinger专用的信息,使得EventThread和SurfaceFlinger等模块可以通过它来间接使用Looper类。
SurfaceFlinger,DisplayDevice,FramebufferSurface和HWComposer这几个类之间的关系比较暧昧。SurfaceFlinger是这部分里最大的客户端。DisplayDevice抽象了显示设备,封装了用于渲染的Surface和HWComposer模块等,从而尽可能使得SurfaceFlinger只要和它打交道。FramebufferSurface抽象了SurfaceFlinger用来画图的Surface,该Surface对应一个BufferQueue用于多缓冲渲染。它和之前提到的应用端用到的Surface区别在于它是基于硬件图形缓冲区的,而不是Ashmem。HWComposer封装了两个重要的HAL模块,即framebuffer和hwcomposer,前者对应硬件缓冲区,后者对应hwcomposer硬件。hwcomposer控制VSync信号,管理屏幕信息和操作framebuffer。HWComposer主要工作是负责将平台相关的HAL模块加载好,并且使得上层模块通过它来使用HAL模块。注意两个容易混淆的概念:HWComposer是类,肯定会有;hwcomposer是硬件模块,在某些平台可能会不可用。这几个类的大致结构如下:
SurfaceFlinger的渲染工作主要是由VSync信号驱动的。EventThread负责发出虚拟VSync信号(由硬件VSync信号偏移指定相位虚拟化得到)。初始化时,MessageQueue在setEventThread()函数中先与EventThread建立连接,然后将与EventThread之间通信的socket(BitTube)句柄注册进Looper,同时也注册了自己的回调函数。另一方面,SurfaceFlinger会通过Looper不断轮询这个句柄,看该句柄上有没有数据。当在该句柄上接收到数据,就会调用MessageQueue相应的回调函数。经过一番处理后,最后MessageQueue的Handler基于收到的消息调用到SurfaceFlinger的相应处理函数。就这样,EventThread->Looper->MessageQueue->SurfaceFlinger的事件消息传递过程形成了。
这里又看到了比较熟悉的设计模式,如Iterator模式用于遍历所有图层(HWComposer::LayerListIterator),
Observer模式用于虚拟VSync信号线程向DispSyncThread申请虚拟VSync事件(DispSyncThread::EventListener),还有前面提到过的Command模式用于消息的延迟处理(postMessageAsync())。
除了这些熟悉的身影外,我们还能看到些新面孔。如RenderEngine::create()应用了简单工厂模式,它根据GLES版本号创建相应的RenderEngine。这样,作为RenderEngine的使用者SurfaceFlinger和Layer自然就成了Strategy模式的受益者,它们不用关心RenderEngine在各个不同版本间实现的差异。还有Mediator模式在Service管理中的应用。SurfaceFlinger进程中,addService()函数向Service
Manager注册了SurfaceFlinger服务。这样Service Manager作为中介的角色在Client和Service之间做沟通,它使得一个网状的模块结构变成了一个优美的星形结构。当然在这里因为就一个服务看不出来,因此这个另作章节再讲。
可以看到,当VSync信号到来时,SurfaceFlinger最主要是通过处理INVALIDATE和REFRESH消息来做合并渲染和输出的工作的。这里的核心思想是能少处理一点是一点,所以在渲染前有很多脏区域的计算工作,这样后面只要处理那些区域的更新就可以了。这样是有现实意义的,一方面由于图层间的遮盖,有些不可见图层不需要渲染。另一方面,因为我们的应用程序中前后帧一般只有一小部分变化,要是每帧都全变估计人都要看吐了。这里主要是调用了这几个函数:
handleMessageTransaction()主要处理之前对屏幕和应用程序窗口的改动。因这些改动很有可能会改变图层的可见区域,进而影响脏区域的计算。
handleMessageInvalidate()主要调用handlePageFlip()函数。这里Page
Flip是指从BufferQueue中取下一个图形缓冲区内容,就好像是“翻页”一样。该函数主要是从各Layer对应的BufferQueue中拿图形缓冲区数据,并根据内容更新脏区域。
handleMessageRefresh()就是合并和渲染输出了。作为重头戏,这步步骤多一些,大体框架如下:
文章一开始的测试用例主干部分背后的故事大概就这么些了。篇幅有限,省略了很多细节。我们可以看到,在服务端做了这么多的事,而对于应用程序来说只要先lock(),再填buffer,最后unlockAndPost()就OK了。这也算是Facade模式的体现了吧。
总结地说,从Android源码中我们可以温习到应用设计模式的基本原则:一是只在合适的地方用。很多时候我们学习设计模式恰恰是为了不用,准确地说是不滥用。二是要用的话不需要过于拘泥于原有的或经典的用法,以解决问题为目的适当自由发挥。

相关文章推荐
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android 4.4(KitKat)中的设计模式-Graphics子系统
- Android KitKat 4.4 Wifi移植之AP模式与网络共享功能调试记录
- Android 4.4(KitKat)窗口管理子系统 - 体系框架
- Android KitKat 4.4 Wifi移植AP模式和网络共享的调试日志
- Android 4.4(KitKat)窗口管理子系统 - 体系框架
- Android 4.4(KitKat)窗口管理子系统 - 体系框架
- Android 4.4(KitKat)窗口管理子系统 - 体系框架
- Android 4.4(KitKat)窗口管理子系统 - 体系框架
- Android 4.4(KitKat)窗口管理子系统 - 体系框架
- Android 内功心法(番外)——写在设计模式前,面对对象编程基础
- Android设计模式-模板方法模式