利用svn检出hadoop源文件
2013-12-04 15:43
183 查看
由于hadoop项目非常的复杂,版本也较多,因此在学习hadoop源码的时候可能会遇到困难,尤其是如何得到hadoop源码,我们利用svn来获取hadoop源码。
首先记住hadoop源码的svn检出地址:http://svn.apache.org/repos/asf/hadoop/common/branches/
1.在eclipse中点击File>>Import找到其中的svn选项(前提是正确的安装eclipsesvn插件),点击从svn中检出项目,如下图所示:
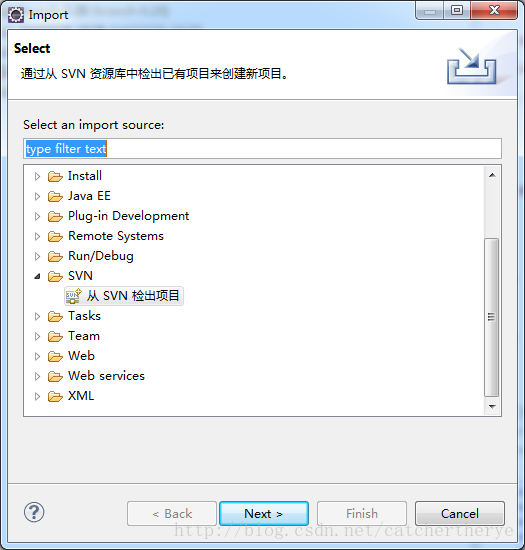
2.选择创建新的资源库位置,然后next
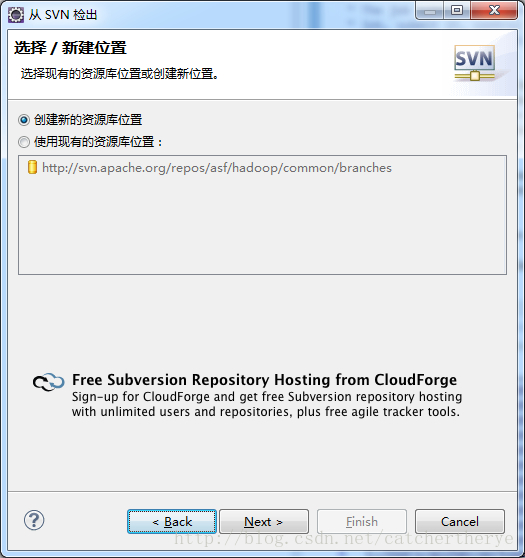
3.在URL后的文本框中输入上面说的hadoop源码检出地址
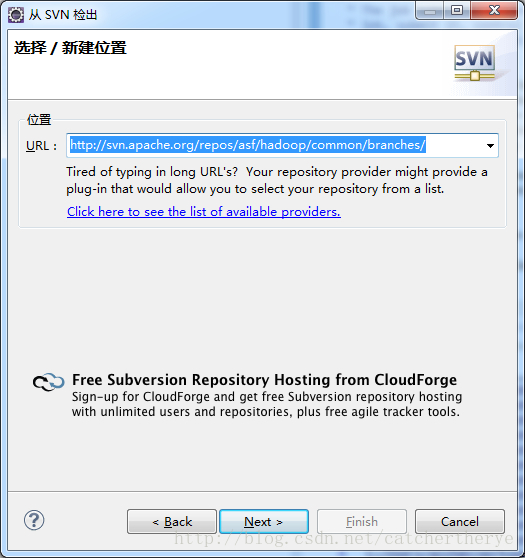
4.如果检出地址输入正确就会出现下图的选择文件列表,从中选择一个想要研究的hadoop源码文件夹
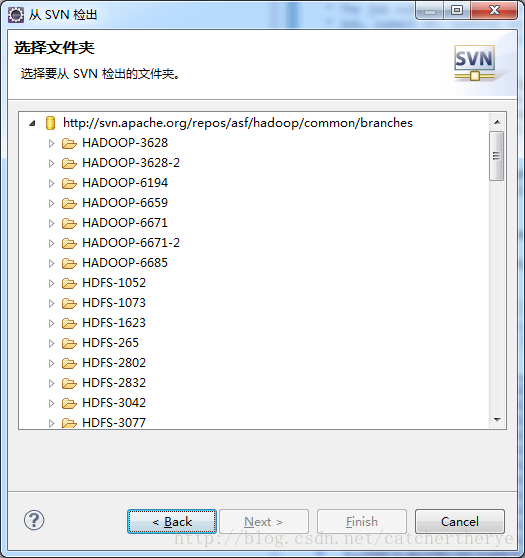
5.选择好文件夹后点击next,注意别着急点finish,在next后还有设置选项。下图默认选项为“作为新项目检出,并使用新项目向导进行配置”,如果选择这个选项需要新建一个项目然后svn中检出的代码放在这个项目中。如果为了省事可以选择第二个选项“作为工作空间中的项目检出”,选择这个选项,插件会在当前项目空间中新建一个项目,项目名称为下面文本框中的名字,当然也可以自己设置,这样一来就比较省事。
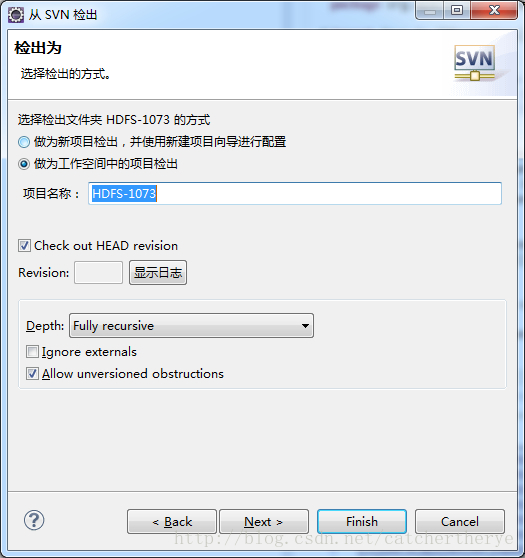
6.在上个步骤中选择之后点击Finish选项,svn就开始从服务器中检出代码。
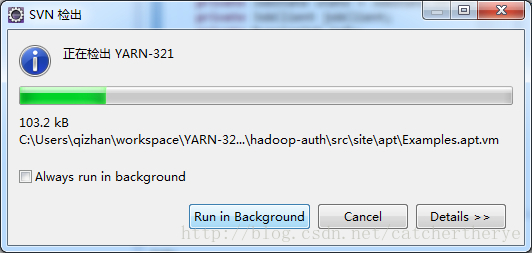
7.检出完成之后,eclipse中就多了一个YARN-321的项目。到这里就可以方便的阅读hadoop的源码了。
首先记住hadoop源码的svn检出地址:http://svn.apache.org/repos/asf/hadoop/common/branches/
1.在eclipse中点击File>>Import找到其中的svn选项(前提是正确的安装eclipsesvn插件),点击从svn中检出项目,如下图所示:
2.选择创建新的资源库位置,然后next
3.在URL后的文本框中输入上面说的hadoop源码检出地址
4.如果检出地址输入正确就会出现下图的选择文件列表,从中选择一个想要研究的hadoop源码文件夹
5.选择好文件夹后点击next,注意别着急点finish,在next后还有设置选项。下图默认选项为“作为新项目检出,并使用新项目向导进行配置”,如果选择这个选项需要新建一个项目然后svn中检出的代码放在这个项目中。如果为了省事可以选择第二个选项“作为工作空间中的项目检出”,选择这个选项,插件会在当前项目空间中新建一个项目,项目名称为下面文本框中的名字,当然也可以自己设置,这样一来就比较省事。
6.在上个步骤中选择之后点击Finish选项,svn就开始从服务器中检出代码。
7.检出完成之后,eclipse中就多了一个YARN-321的项目。到这里就可以方便的阅读hadoop的源码了。

相关文章推荐
- yum搭建svn apache 利用钩子检出到web目录 自动同步
- 利用ant批量检出svn上的特定资源
- 如何利用CHtmlView类实现IE“查看->源文件”命令?
- eclipse利用svn插件导入项目后存在的环境问题处理办法。
- 关于Android 项目从svn中检出无R.java文件问题
- 分享一个生产环境中利用SVN上线代码的脚本
- svn检出maven项目的步骤
- (转)svn检出的时候报 Unable to connect to a repository at URL错误
- 利用ambari搭建hadoop、hbase集群
- 本地从SVN检出的项目导入Eclipse后未能自动与Eclipse的svn插件关联
- eclipse svn检出项目为非JAVA项目
- Svn 服务器布置java项目,并添加到myeclipse中,在客户端检出,更新和提交图 步骤
- Java 利用 svnKit 操作SVN 【获取所有文件夹、添加文件、文件下载】
- hadoop1.0.3 源码通过svn导入eclipse
- svn检出历史版本
- hadoop用户使用svn时无法保存密钥的解决办法
- svn检出数据无法验证问题解决方法
- 如何检出SVN老版本代码
- myeclipse10.6无法检出svn项目的问题,我的一个笨办法
- 利用Hadoop提供的RPC API实现简单的RPC程序