drbd介绍、工作原理及脑裂故障处理
2013-11-25 01:58
218 查看
一、drbd基本介绍
drbd(全称为Distributed Replicated Block Device,简称drbd)分布式块设备复制,说白了就是在不同节点上两个相同大小的设备块级别之间的数据同步镜像。drbd是由内核模块和相关脚本而构成,用以构建高可用性的集群。
在高可用(HA)解决方案中使用drbd的功能,可以代替使用一个共享盘阵存储设备。因为数据同时存在于本地主机和远程主机上,在遇到需要切换的时候,远程主机只需要使用它上面的那份备份数据,就可以继续提供服务了。
二、drbd的结构示意图及工作原理
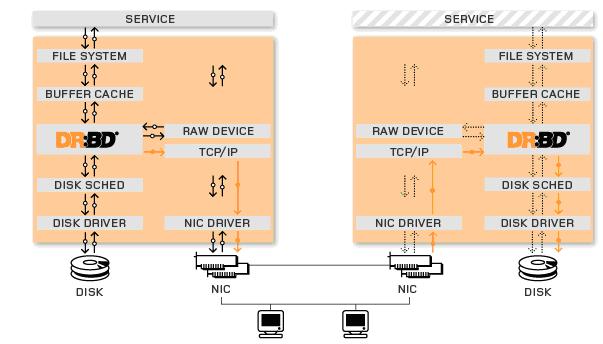
从上图我们可以清晰的看出drbd是以主从(Primary/Secondary)方式工作的,这点原理与mysql的主从复制的架构有些相似。主节点上的drbd提升为Primary并负责接收写入数据,当数据到达drbd模块时,一份继续往下走写入到本地磁盘实现数据的持久化,同时并将接收到的要写入的数据发送一分到本地的drbd设备上通过tcp传到另外一台主机的drbd设备上(Secondary node),另一台主机上的对应的drbd设备再将接收到的数据存入到自己的磁盘当中。这里与mysql的基于通过二进制日志完成数据的复制的确很相似,但是也有一些不同之处。比如:mysql的从节点不能写但是可以读,但是drbd的从节点是不能读、不能挂载。
因此,drbd对同一设备块每次只允许对主节点进行读、写操作,从节点不能写也不能读。这样感觉是不是对主机有资源浪费,的确HA架构中为了提供冗余能力是有资源浪费,但是你可以对上图的两台主机建立两个drbd资源并互为主从,这样两台机器都能利用起来,但是配置起来就复杂了。但是话又说回来,用drbd作为廉价的共享存储设备,要节约很多成本,因为价格要比专用的存储网络便宜很多,其性能与稳定性方面也还不错。
三、drbd的复制模式(协议)
A协议:
异步复制协议。一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。因此,这种模式效率最高,但是数据不安全,存在数据丢失。
B协议:
内存同步(半同步)复制协议。一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据可能不会被提交到磁盘
C协议:
同步复制协议。只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有数据丢失,所以这是一个群集节点的流行模式,但I/O吞吐量依赖于网络带宽。因此,这种模式数据相对安全,但是效率比较低。
四、drbd的安装配置
1、安装 sudo apt-get install drbd8-utils
2、两节点准备工作
node1、node2时间同步;
两节点各自准备一个大小相同的分区块;
建立双机互信,实现互信登陆
3、drbd文件结构说明
/etc/drbd.conf 主配置文件
/etc/drbd.d/global_common.conf 定义配置global、common段
/etc/drbd.d/*.res 定义资源
4、drbd配置
4.1、global_common.conf
global {
usage-count no; 是否加入统计
}
common {
protocol C; 使用什么协议
handlers {
定义处理机制程序,/usr/lib/drbd/ 里有大量的程序脚本,但是不一定靠谱
}
startup {
定义启动超时等
}
disk {
磁盘相关公共设置,比如I/O,磁盘故障了怎么办
}
net {
定义网络传输、加密算法等
}
syncer {
rate 1000M; 定义网络传输速率
}
}
4.2、资源配置(*.res)
resource name{
meta-disk internal; # node1/node2 公用部分可以提取到顶部
on node1{
device /dev/drbd0;
disk /dev/sda6;
address 192.168.1.101:7789;
}
on node2 {
device /dev/drbd0;
disk /dev/sda6;
address 192.168.1.102:7789;
}
}
5、以上文件在两个节点上必须相同,因此,可以基于ssh将刚才配置的文件全部同步至另外一个节点
# scp -p /etc/drbd.d/* node2:/etc/drbd.d /
6、启动测试
1)初始化资源,在Node1和Node2上分别执行:
# sudo drbdadm create-md mydata
2)启动服务,在Node1和Node2上分别执行:
# sudo service drbd start
3)查看启动状态
# cat /proc/drbd
4)从上面的信息中可以看出此时两个节点均处于Secondary状态。于是,我们接下来需要将其中一个节点设置为Primary。在要设置为Primary的节点上执行如下命令:
# sudo drbdadm -- --overwrite-data-of-peer primary all (第一次执行此命令)
# sudo drbdadm primary --force mydata
第一次执行完此命令后,在后面如果需要设置哪个是主节点时,就可以使用另外一个命令:
# /sbin/drbdadm primary r0或者/sbin/drbdadm primary all
5)监控数据同步
# watch -n1 'cat /proc/drbd'
6)数据同步完成格式化drbd分区,并挂载
# sudo mke2fs -t ext4 /dev/drbd0
# sudo moun/dev/drbd0 /mnt
# ls -l /mnt

测试OK~
五、脑裂故障处理

在做Corosync+DRBD的高可用MySQL集群实验中,意外发现各个节点无法识别对方,连接为StandAlone则主从节点无法通信,效果如上图。
以下为drbd脑裂手动恢复过程(以node1的数据位主,放弃node2不同步数据):
1)将Node1设置为主节点并挂载测试,mydata为定义的资源名
# drbdadm primary mydata
# mount /dev/drbd0 /mydata
# ls -lh /mydata 查看文件情况
2)将Node2设置为从节点并丢弃资源数据
# drbdadm secondary mydata
# drbdadm -- --discard-my-data connect mydata
3)在Node1主节点上手动连接资源
# drbdadm connect mydata
4)最后查看各个节点状态,连接已恢复正常
# cat /proc/drbd
测试效果如下图(故障修复):

六、drbd其他相关(文献部分):
1、 DRBD各种状态含义The resource-specific output from
2、 DRBD连接状态A resource may have one of the following connectionstates:
本文出自 “学而实习之” 博客,请务必保留此出处http://bruce007.blog.51cto.com/7748327/1330959
drbd(全称为Distributed Replicated Block Device,简称drbd)分布式块设备复制,说白了就是在不同节点上两个相同大小的设备块级别之间的数据同步镜像。drbd是由内核模块和相关脚本而构成,用以构建高可用性的集群。
在高可用(HA)解决方案中使用drbd的功能,可以代替使用一个共享盘阵存储设备。因为数据同时存在于本地主机和远程主机上,在遇到需要切换的时候,远程主机只需要使用它上面的那份备份数据,就可以继续提供服务了。
二、drbd的结构示意图及工作原理
从上图我们可以清晰的看出drbd是以主从(Primary/Secondary)方式工作的,这点原理与mysql的主从复制的架构有些相似。主节点上的drbd提升为Primary并负责接收写入数据,当数据到达drbd模块时,一份继续往下走写入到本地磁盘实现数据的持久化,同时并将接收到的要写入的数据发送一分到本地的drbd设备上通过tcp传到另外一台主机的drbd设备上(Secondary node),另一台主机上的对应的drbd设备再将接收到的数据存入到自己的磁盘当中。这里与mysql的基于通过二进制日志完成数据的复制的确很相似,但是也有一些不同之处。比如:mysql的从节点不能写但是可以读,但是drbd的从节点是不能读、不能挂载。
因此,drbd对同一设备块每次只允许对主节点进行读、写操作,从节点不能写也不能读。这样感觉是不是对主机有资源浪费,的确HA架构中为了提供冗余能力是有资源浪费,但是你可以对上图的两台主机建立两个drbd资源并互为主从,这样两台机器都能利用起来,但是配置起来就复杂了。但是话又说回来,用drbd作为廉价的共享存储设备,要节约很多成本,因为价格要比专用的存储网络便宜很多,其性能与稳定性方面也还不错。
三、drbd的复制模式(协议)
A协议:
异步复制协议。一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。因此,这种模式效率最高,但是数据不安全,存在数据丢失。
B协议:
内存同步(半同步)复制协议。一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据可能不会被提交到磁盘
C协议:
同步复制协议。只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有数据丢失,所以这是一个群集节点的流行模式,但I/O吞吐量依赖于网络带宽。因此,这种模式数据相对安全,但是效率比较低。
四、drbd的安装配置
1、安装 sudo apt-get install drbd8-utils
2、两节点准备工作
node1、node2时间同步;
两节点各自准备一个大小相同的分区块;
建立双机互信,实现互信登陆
3、drbd文件结构说明
/etc/drbd.conf 主配置文件
/etc/drbd.d/global_common.conf 定义配置global、common段
/etc/drbd.d/*.res 定义资源
4、drbd配置
4.1、global_common.conf
global {
usage-count no; 是否加入统计
}
common {
protocol C; 使用什么协议
handlers {
定义处理机制程序,/usr/lib/drbd/ 里有大量的程序脚本,但是不一定靠谱
}
startup {
定义启动超时等
}
disk {
磁盘相关公共设置,比如I/O,磁盘故障了怎么办
}
net {
定义网络传输、加密算法等
}
syncer {
rate 1000M; 定义网络传输速率
}
}
4.2、资源配置(*.res)
resource name{
meta-disk internal; # node1/node2 公用部分可以提取到顶部
on node1{
device /dev/drbd0;
disk /dev/sda6;
address 192.168.1.101:7789;
}
on node2 {
device /dev/drbd0;
disk /dev/sda6;
address 192.168.1.102:7789;
}
}
5、以上文件在两个节点上必须相同,因此,可以基于ssh将刚才配置的文件全部同步至另外一个节点
# scp -p /etc/drbd.d/* node2:/etc/drbd.d /
6、启动测试
1)初始化资源,在Node1和Node2上分别执行:
# sudo drbdadm create-md mydata
2)启动服务,在Node1和Node2上分别执行:
# sudo service drbd start
3)查看启动状态
# cat /proc/drbd
4)从上面的信息中可以看出此时两个节点均处于Secondary状态。于是,我们接下来需要将其中一个节点设置为Primary。在要设置为Primary的节点上执行如下命令:
# sudo drbdadm -- --overwrite-data-of-peer primary all (第一次执行此命令)
# sudo drbdadm primary --force mydata
第一次执行完此命令后,在后面如果需要设置哪个是主节点时,就可以使用另外一个命令:
# /sbin/drbdadm primary r0或者/sbin/drbdadm primary all
5)监控数据同步
# watch -n1 'cat /proc/drbd'
6)数据同步完成格式化drbd分区,并挂载
# sudo mke2fs -t ext4 /dev/drbd0
# sudo moun/dev/drbd0 /mnt
# ls -l /mnt
测试OK~
五、脑裂故障处理
在做Corosync+DRBD的高可用MySQL集群实验中,意外发现各个节点无法识别对方,连接为StandAlone则主从节点无法通信,效果如上图。
以下为drbd脑裂手动恢复过程(以node1的数据位主,放弃node2不同步数据):
1)将Node1设置为主节点并挂载测试,mydata为定义的资源名
# drbdadm primary mydata
# mount /dev/drbd0 /mydata
# ls -lh /mydata 查看文件情况
2)将Node2设置为从节点并丢弃资源数据
# drbdadm secondary mydata
# drbdadm -- --discard-my-data connect mydata
3)在Node1主节点上手动连接资源
# drbdadm connect mydata
4)最后查看各个节点状态,连接已恢复正常
# cat /proc/drbd
测试效果如下图(故障修复):
六、drbd其他相关(文献部分):
1、 DRBD各种状态含义The resource-specific output from
/proc/drbdcontains various pieces ofinformation about the resource:
cs(connection state). Status of the network connection. See the section called “Connection states” for details about the various connection states.
ro(roles). Roles of the nodes. The role of the local node isdisplayed first, followed by the role of the partnernode shown after the slash. See the section called “Resource roles” for details about thepossible resource roles.
ds(disk states). State of the hard disks. Prior to the slash thestate of the local node is displayed, after the slashthe state of the hard disk of the partner node isshown. See the section called “Disk states” for details about the variousdisk states.
ns(network send). Volume of net data sent to the partner via thenetwork connection; in Kibyte.
nr(network receive). Volume of net data received by the partner viathe network connection; in Kibyte.
dw(disk write). Net data written on local hard disk; inKibyte.
dr(disk read). Net data read from local hard disk; in Kibyte.
al(activity log). Number of updates of the activity log area of the metadata.
bm(bit map). Number of updates of the bitmap area of the metadata.
lo(local count). Number of open requests to the local I/O sub-systemissued by DRBD.
pe(pending). Number of requests sent to the partner, but thathave not yet been answered by the latter.
ua(unacknowledged). Number of requests received by the partner via thenetwork connection, but that have not yet beenanswered.
ap(application pending). Number of block I/O requests forwarded to DRBD, butnot yet answered by DRBD.
ep(epochs). Number of epoch objects. Usually 1. Might increaseunder I/O load when using either the
barrieror the
nonewriteordering method. Since 8.2.7.
wo(write order). Currently used write ordering method:
b(barrier),
f(flush),
d(drain) or
n(none). Since8.2.7.
oos(out of sync). Amount of storage currently out of sync; inKibibytes. Since 8.2.6.
2、 DRBD连接状态A resource may have one of the following connectionstates:
StandAlone. No network configuration available. The resourcehas not yet been connected, or has beenadministratively disconnected (using drbdadm disconnect), or has dropped its connectiondue to failed authentication or split brain.
Disconnecting. Temporary state during disconnection. The nextstate is StandAlone.
Unconnected. Temporary state, prior to a connection attempt.Possible next states: WFConnection andWFReportParams.
Timeout. Temporary state following a timeout in thecommunication with the peer. Next state:Unconnected.
BrokenPipe. Temporary state after the connection to the peerwas lost. Next state: Unconnected.
NetworkFailure. Temporary state after the connection to thepartner was lost. Next state: Unconnected.
ProtocolError. Temporary state after the connection to thepartner was lost. Next state: Unconnected.
TearDown. Temporary state. The peer is closing theconnection. Next state: Unconnected.
WFConnection. This node is waiting until the peer node becomesvisible on the network.
WFReportParams. TCP connection has been established, this nodewaits for the first network packet from thepeer.
Connected. A DRBD connection has been established, datamirroring is now active. This is the normalstate.
StartingSyncS. Full synchronization, initiated by theadministrator, is just starting. The next possiblestates are: SyncSource or PausedSyncS.
StartingSyncT. Full synchronization, initiated by theadministrator, is just starting. Next state:WFSyncUUID.
WFBitMapS. Partial synchronization is just starting. Nextpossible states: SyncSource or PausedSyncS.
WFBitMapT. Partial synchronization is just starting. Nextpossible state: WFSyncUUID.
WFSyncUUID. Synchronization is about to begin. Next possiblestates: SyncTarget or PausedSyncT.
SyncSource. Synchronization is currently running, with thelocal node being the source ofsynchronization.
SyncTarget. Synchronization is currently running, with thelocal node being the target ofsynchronization.
PausedSyncS. The local node is the source of an ongoingsynchronization, but synchronization is currentlypaused. This may be due to a dependency on thecompletion of another synchronization process, ordue to synchronization having been manuallyinterrupted by drbdadm pause-sync.
PausedSyncT. The local node is the target of an ongoingsynchronization, but synchronization is currentlypaused. This may be due to a dependency on thecompletion of another synchronization process, ordue to synchronization having been manuallyinterrupted by drbdadm pause-sync.
VerifyS. On-line device verification is currently running,with the local node being the source ofverification.
VerifyT. On-line device verification is currently running,with the local node being the target ofverification.
本文出自 “学而实习之” 博客,请务必保留此出处http://bruce007.blog.51cto.com/7748327/1330959

相关文章推荐
- drbd介绍、工作原理及脑裂故障处理
- DRBD安装配置、工作原理及故障恢复
- DRBD安装配置、工作原理及故障恢复
- DRBD脑裂问题故障处理
- drbd脑裂问题处理
- Polly 弹性和瞬态故障处理库 介绍
- DRBD 性能优化、管理和故障处理部分
- DRBD安装配置、工作原理及故障恢复
- DRBD Unknown故障处理过程
- DRBD 管理、故障处理部分
- DRBD安装配置、工作原理及故障恢复
- drbd脑裂问题处理
- KVM虚拟化开源高可用方案(六)ISCSI ON DRBD搭建及常见故障处理
- DRBD故障处理
- drbd脑裂处理
- drbd脑裂问题处理
- JVM虚拟机性能监测与故障处理工具简单介绍
- 记一次DRBD Unknown故障处理过程 推荐
- 已被.NET基金会认可的弹性和瞬态故障处理库Polly介绍
- DRBD脑裂故障处理