如何随机获取数据库不连续ID的数据?
2013-11-14 10:27
295 查看
这个问题的来由是我朋友要为一网站实现一个标签云功能,和我交流后我给出了一个方案,在此略作记录,亦求拍砖。
大概需求这是样的:
在数据库有一张表A如下图:
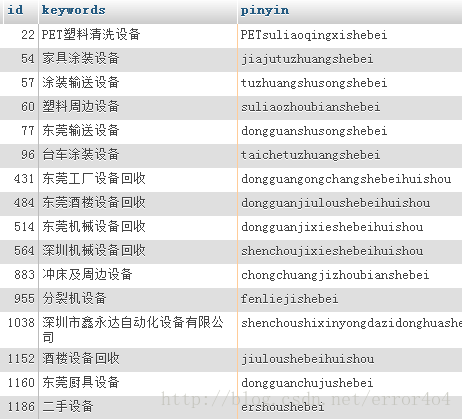
其中id字段的值未必是连续的,现在我朋友要做的事情就是要从这张表获取5条数据,但这5条数据是具有随机性的,比如可能是[6,2,5,10,17]
解决方案和推理过程如下:
1、先求出这张表最小和最大的id还有数据的条数, 设 min为最小id,
max为最大id,count为数据的条数
从上表得知 :
min=22;
max=1186;
count=16;
那么可用的连续的 IDS=[min,max],即从22到1186之间,但这之间有些id是没对应上数据的,比如如果某id是23,那么在上表则没有对应的数据。根据要求需要从这张表随机取5条数据,那么就是说我们可以从min到max之间随机产生5个id,但问题来了,很明显从上表可以看出产生的这5个id未必会是表中存在的id,那么就是说我们需要产生多少个
随机id才能保证至少能获取到5条数据呢?推理过程如下:
表中不存在的ID数目=max-count=1186-16=1170,就是说我们有1170个id是不存在上表中的,就是说我们至少要生产1170+1个不同的id才能保证击中上表的某个id,如果需要击中n个id则的公式则为max-count+n,上面的要求是n=5,所以至少要生产的随机id为1170+5=1175个id,然后我们可以组装select
* from A where id in [1175个id] 的方式进行数据库查询了,这样我们就可以至少得到5条随机的数据了。
从上表也可以看出一个问题,就是当id的不连续区间比较大的时候需要生产的随机id就要越多,比如上面的最大id是1186,而这张表却只有16条数据,就是说count越接近max则需要生产的随机id则越少,则此算法的效率则越高。
PS1:
此前朋友也在网上搜索了一种解决方案,但我觉得不太好,所以就有了上面的文字。方案如下:
这个问题来自论坛提问。很多人都知道类似下面的语句
PS2:
本文章还有一个朋友阿木的帮助才能得以完成,这种策略是我提出的,数学上的推理是阿木协助我完成的。再次感叹数学之重要。
PS3:
最后为朋友淘宝小店打个小广告:
https://vinnienz.taobao.com/
大概需求这是样的:
在数据库有一张表A如下图:
其中id字段的值未必是连续的,现在我朋友要做的事情就是要从这张表获取5条数据,但这5条数据是具有随机性的,比如可能是[6,2,5,10,17]
解决方案和推理过程如下:
1、先求出这张表最小和最大的id还有数据的条数, 设 min为最小id,
max为最大id,count为数据的条数
从上表得知 :
min=22;
max=1186;
count=16;
那么可用的连续的 IDS=[min,max],即从22到1186之间,但这之间有些id是没对应上数据的,比如如果某id是23,那么在上表则没有对应的数据。根据要求需要从这张表随机取5条数据,那么就是说我们可以从min到max之间随机产生5个id,但问题来了,很明显从上表可以看出产生的这5个id未必会是表中存在的id,那么就是说我们需要产生多少个
随机id才能保证至少能获取到5条数据呢?推理过程如下:
表中不存在的ID数目=max-count=1186-16=1170,就是说我们有1170个id是不存在上表中的,就是说我们至少要生产1170+1个不同的id才能保证击中上表的某个id,如果需要击中n个id则的公式则为max-count+n,上面的要求是n=5,所以至少要生产的随机id为1170+5=1175个id,然后我们可以组装select
* from A where id in [1175个id] 的方式进行数据库查询了,这样我们就可以至少得到5条随机的数据了。
从上表也可以看出一个问题,就是当id的不连续区间比较大的时候需要生产的随机id就要越多,比如上面的最大id是1186,而这张表却只有16条数据,就是说count越接近max则需要生产的随机id则越少,则此算法的效率则越高。
PS1:
此前朋友也在网上搜索了一种解决方案,但我觉得不太好,所以就有了上面的文字。方案如下:
这个问题来自论坛提问。很多人都知道类似下面的语句
select top 2000 * from tb order by newid()
但是在海量数据下,它的性能是无法忍受的。这里我用一个变通的办法来实现性能的提升,思路为:表必须存在一个guid类型的主键或者索引列,然后用这个列去like一个随机字符串,随机字符串必须为guid规定的字符集合(数字+A到Z)。下面例子只用到了数字,并且只用了4个数字来匹配,你可以更改like后面的语句来调整这个策略。
--生成测试环境 use master go create table test(id uniqueidentifier,name varchar(100)) insert into test select newid(),name from syscolumns --随机提取 select top 10 * from test where id like char(48+abs(checksum(newid())%10))+ '%'+ char(48+abs(checksum(newid())%10))+ '%'+ char(48+abs(checksum(newid())%10))+ '%'+ char(48+abs(checksum(newid())%10))+'%' --删除测试环境 drop table test我测试了300万数据提取2000条,耗时大约1秒左右。另外提醒一点,索引对like语句是有效的。
PS2:
本文章还有一个朋友阿木的帮助才能得以完成,这种策略是我提出的,数学上的推理是阿木协助我完成的。再次感叹数学之重要。
PS3:
最后为朋友淘宝小店打个小广告:
https://vinnienz.taobao.com/

相关文章推荐
- 如何随机获取数据库不连续ID的数据?
- 如何准确高效的获取数据库新插入数据的主键id
- 如何获取数据库新插入数据的主键id
- LINQ通过视图获取数据库随机数据
- JSP 如何获取下拉列表的选中的值是数据库表的对应数据
- SQLServer 如何获取刚插入数据的Id号
- swing——combobox如何获取数据库数据并显示
- 在 MySQL中,从10 万条主键不连续的数据里随机取 3000 条,如何做到高效?
- 数据库如何查询第二条数据且ID不同
- 如何动态获取数据库表中的数据,数据库中的字段是在变化的
- 四种数据库随机获取N条数据的方法
- THINKPHP如何在添加数据的时候获取主键id的值
- 如果数据表中‘Id’为主键,如何利用数据库自带工具导入数据呢
- Atitit.并发测试解决方案(2) -----获取随机数据库记录 随机抽取数据 随机排序 原理and实现
- 如何在控制器获取数据库的数据并且在模板输出
- ID值并不是连续的,如何读取到中间一段数据
- 使用 SQL 语句从数据库一个表中随机获取一些数据
- 从数据库获取 10 条随机数据
- 数据库表中获取随机数据
- Atitit.并发测试解决方案(2) -----获取随机数据库记录 随机抽取数据 随机排序 原理and实现