SlopOne 改进
2013-11-13 09:46
68 查看
lope One
其基本的想法来自于简单的一元线性模型 $w = f(v) = v + b$。已知一组训练点 ${(v_i, w_i)}_{i=1}^n$,利用此线性模型最小化预测误差的平方和,我们可以获得
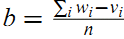
利用上式获得了$b$的取值后,对于新的数据点$v_{new}$,我们可以利用 $w_{new} = b + v_{new}$ 获得它的预测值。
直观上我们可以把上面求偏移 $b$ 的公式理解为 $w_i$ 和 $v_i$ 差值的平均值。
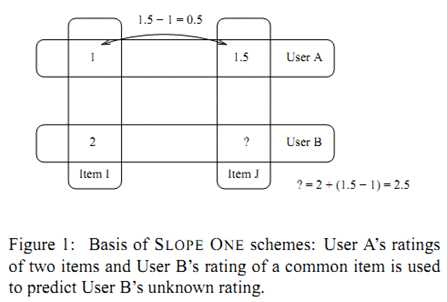
利用上面的直观,我们定义item $i$ 相对于 item $j$ 的平均偏差:
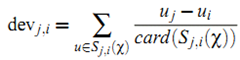
其中 $S_{j,i}()$ 表示同时对item $i$ 和 $j$ 给予了评分的用户集合,而 $card()$ 表示集合包含的元素数量。
有了上面的定义后,我们可以使用
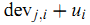
获得用户 $u$ 对 item $j$ 的预测值。当把所有这种可能的预测平均起来,可以得到:
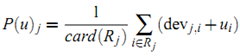
其中 $R_j$ 表示所有用户 $u$ 已经给予评分且满足条件 ($i \neq j$ 且 $S_{j,i}$非空) 的item集合。
对于足够稠密的数据集,我们可以使用近似
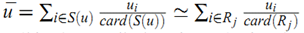
把上面的预测公式简化为
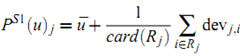
Weighted Slope One
Slope One中在计算 item $i$ 相对于 item $j$ 的平均偏差 $dev_{j,i}$ 时没有考虑到使用不同的用户数量平均得到的 $dev_{j,i}$,其可信度不同。假设有 $2000$ 个用户同时评分了 item $j$ 和 $k$,而只有$20$ 个用户同时评分了 item $j$ 和 $l$,那么显然获得的 $dev_{j, k}$ 比 $dev_{j, l}$
更具有说服力(类似于kNN中压缩相似度的思想)。所以一个修正是对最终的平均使用加权:
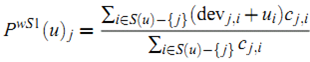
其中
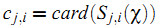
(根据在Netflix上的经验,可能把 $c_{j,i}$ 再开方更合适)
Bi-Polar Slope One
Bi-Polar Slope One 进一步把用户已经给予评分的item划分为两类——like和dislike,而其划分的方法是判断对应的评分是否大于此用户的平均评分:
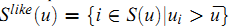
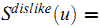
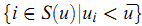
类似地,可以定义对item $i$ 和 $j$ 具有相同喜好的用户集合:
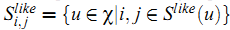
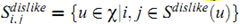
利用上面的定义,我们可以使用下面的公式为(like或dislike的item)获得新的偏差值:
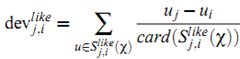
这样可以计算从item $i$ 计算得到的预测值:
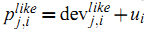
或者
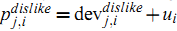
最终 Bi-Polar Slope One 的预测公式为
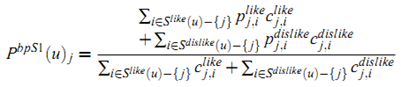
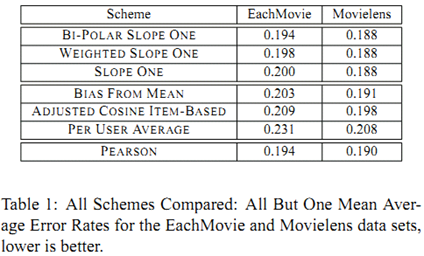
最后的实验比较使用的度量为 MAE,其结果如下:
其基本的想法来自于简单的一元线性模型 $w = f(v) = v + b$。已知一组训练点 ${(v_i, w_i)}_{i=1}^n$,利用此线性模型最小化预测误差的平方和,我们可以获得

利用上式获得了$b$的取值后,对于新的数据点$v_{new}$,我们可以利用 $w_{new} = b + v_{new}$ 获得它的预测值。
直观上我们可以把上面求偏移 $b$ 的公式理解为 $w_i$ 和 $v_i$ 差值的平均值。
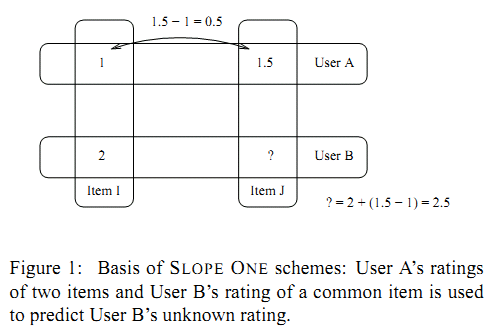
利用上面的直观,我们定义item $i$ 相对于 item $j$ 的平均偏差:

其中 $S_{j,i}()$ 表示同时对item $i$ 和 $j$ 给予了评分的用户集合,而 $card()$ 表示集合包含的元素数量。
有了上面的定义后,我们可以使用
获得用户 $u$ 对 item $j$ 的预测值。当把所有这种可能的预测平均起来,可以得到:
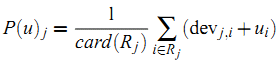
其中 $R_j$ 表示所有用户 $u$ 已经给予评分且满足条件 ($i \neq j$ 且 $S_{j,i}$非空) 的item集合。
对于足够稠密的数据集,我们可以使用近似
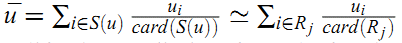
把上面的预测公式简化为

Weighted Slope One
Slope One中在计算 item $i$ 相对于 item $j$ 的平均偏差 $dev_{j,i}$ 时没有考虑到使用不同的用户数量平均得到的 $dev_{j,i}$,其可信度不同。假设有 $2000$ 个用户同时评分了 item $j$ 和 $k$,而只有$20$ 个用户同时评分了 item $j$ 和 $l$,那么显然获得的 $dev_{j, k}$ 比 $dev_{j, l}$
更具有说服力(类似于kNN中压缩相似度的思想)。所以一个修正是对最终的平均使用加权:
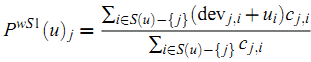
其中
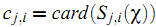
(根据在Netflix上的经验,可能把 $c_{j,i}$ 再开方更合适)
Bi-Polar Slope One
Bi-Polar Slope One 进一步把用户已经给予评分的item划分为两类——like和dislike,而其划分的方法是判断对应的评分是否大于此用户的平均评分:
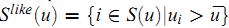
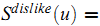
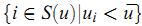
类似地,可以定义对item $i$ 和 $j$ 具有相同喜好的用户集合:

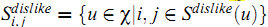
利用上面的定义,我们可以使用下面的公式为(like或dislike的item)获得新的偏差值:
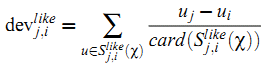
这样可以计算从item $i$ 计算得到的预测值:
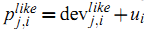
或者
最终 Bi-Polar Slope One 的预测公式为

最后的实验比较使用的度量为 MAE,其结果如下:


相关文章推荐
- SlopOne 改进
- Servlet 3.0 (6) 现有API的改进及小结
- CLog做了些许改进
- Spring mvc 3.0与2.5的改进
- 人脸识别之人脸对齐(四)--CLM算法及概率图模型改进
- 策略模式 用其它方法改进
- 开源公司内部的微信爬虫,寻求志同道合的人一起来改进
- EJB 3.1五大模式改进令Java EE 6更好用
- 顺序表应用4-2:元素位置互换之逆置算法(数据改进)
- MoSonic:对SubSonic的分布式存储、缓存改进方案尝试(1)
- 改进的Python贴吧爬虫代码
- jQuery1.5的改进细节
- C++实现改进的冒泡排序
- ASP.NET中生成Excel遇到的问题及改进方法
- QT 验证改进后Bresenham算法
- 改进的防盗链功能
- c++11改进我们的程序之垃圾回收
- 改进版CTEXT
- HTTP/2.0 相比1.0有哪些重大改进?
- 改进Source Insight对汉字的支持