Python正则表达式指南
2013-11-11 11:31
211 查看
转自http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html

博客园
首页
博问
闪存
订阅
管理
本文介绍了Python对于正则表达式的支持,包括正则表达式基础以及Python正则表达式标准库的完整介绍及使用示例。本文的内容不包括如何编写高效的正则表达式、如何优化正则表达式,这些主题请查看其他教程。
注意:本文基于Python2.4完成;如果看到不明白的词汇请记得百度谷歌或维基,whatever。
尊重作者的劳动,转载请注明作者及原文地址 >.<html
下图展示了使用正则表达式进行匹配的流程:
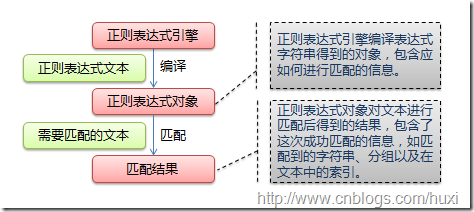
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:

re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):
返回(start(group), end(group))。
expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
pattern: 编译时用的表达式字符串。
flags: 编译时用的匹配模式。数字形式。
groups: 表达式中分组的数量。
groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
实例方法[ | re模块方法]:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
全文结束
分类: 学习笔记, Python
绿色通道: 好文要顶 关注我 收藏该文与我联系


AstralWind
关注 - 1
粉丝 - 145
+加关注
71
0
(请您对文章做出评价)
« 上一篇:Python线程指南
» 下一篇:Python字符编码详解
posted @ 2010-07-04 23:56 AstralWind 阅读(126979)
评论(40) 编辑 收藏
评论列表
#1楼 2010-07-06
14:08 Lucker
精彩,好文!
支持(1)反对(0)
#2楼 2010-12-17
11:20 iTech
超级好文,转载了
支持(1)反对(0)
#3楼 2010-12-17
11:24 iTech
此文实在是太好了,我转载了,点击率超级高啊,打破了历史水平啊!高的我都不好意思啊!我只是想收藏此精彩文章,没有其他的意思。
支持(0)反对(0)
#4楼[楼主] 2010-12-17
21:35 AstralWind
@iTech
对大家有帮助就好,也没打算靠版权挣钱呵呵~
支持(1)反对(0)
#5楼 2011-05-06
10:59 青怪
很好的文章,学习了。谢谢!
支持(0)反对(0)
#6楼 2011-06-28
10:37 Sackula[未注册用户]
宇宙无敌好文~~~~~~~~
#7楼 2011-07-20
15:35 vijay
不错,收藏并转载
支持(0)反对(0)
#8楼 2011-07-31
03:50 dawb[未注册用户]
非常好,写的深入浅出
#9楼 2011-07-31
09:48 lidashuang
非常不错,博主第一图是用什么工具做的?
支持(0)反对(0)
#10楼[楼主] 2011-07-31
12:54 AstralWind
@lidashuang
PowerPoint :)
支持(0)反对(0)
#11楼 2011-08-14
10:24 junjie020[未注册用户]
您好!
有一个问题关于python的条件表达式的
我发现,如果在条件表达式里面,使用别名,python是不行的(我使用的版本是2.7.2和3.2.1)
如 :
reobj = re.match(r"(?P<N1>8)(?(?P=N1)8)", "88")
这样是无法匹配的,如果使用:
reobj = re.match(r"(8)(?(1)8", "88")
这样是可以的,不知道楼主是否有试过这样使用别名来引用条件表达式呢?还是我有没有写错的?
希望指教!
#12楼[楼主] 2011-08-15
09:43 AstralWind
@junjie020
你好!抱歉回复晚了,是这样,你第一个正则
应该写成
这样就没有问题了。(?(?P=N1)8)这是个不合法的正则表达式,无法编译。
支持(0)反对(0)
#13楼 2011-10-03
22:24 shirne
python的正则很强大,学习收藏了
支持(0)反对(0)
#14楼 2011-11-07
11:59 eason@pku
不错.
支持(0)反对(0)
#15楼 2011-12-09
15:03 qqzhao
不错...
支持(0)反对(0)
#16楼 2011-12-19
17:16 你能记住几个
您好,能不能分享下文中的图片和表格是用什么软件画的,很好看啊
支持(0)反对(0)
#17楼[楼主] 2011-12-19
18:46 AstralWind
@你能记住几个
ms office
支持(0)反对(0)
#18楼 2011-12-25
17:47 会长
好哇,我每次写正则表达式时,都来这看。脑子不行,记不住规则,只能随写随查
支持(0)反对(0)
#19楼 2011-12-26
17:02 pyt123
谢谢楼主分享
支持(0)反对(0)
#20楼 2012-01-19
10:01 naslang[未注册用户]
不错,受益了。
#21楼 2012-02-12
15:53 ruyunlong[未注册用户]
我也顶一下,哈哈,感谢楼主奉献
#22楼 2012-02-25
15:40 dazi
好东西 python 是个好东西 正则也是个好东西
支持(0)反对(0)
#23楼 2012-02-29
17:08 mimicom
这个我经常来看..... 呵呵...
支持(0)反对(0)
#24楼 2012-03-09
11:20 mimicom
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
奇怪... 怎么会有第三组? .
(?P<sign>.*) 这个是别名啊?.. 难道因为后面的 .* 也在括号里面?对应的后面的感叹号.
支持(0)反对(0)
#25楼 2012-03-09
11:26 mimicom
哦..明白了...
(?P<sign>.*)
sign是.*的别名...
支持(0)反对(0)
#26楼 2012-03-12
11:25 villion
文章太好了!!!
支持(0)反对(0)
#27楼 2012-06-29
10:02 TonyKong
cnblog博文的质量普遍很高啊。收藏了
支持(0)反对(0)
#28楼 2012-07-17
15:25 小北北北
就是java里面的Pattern Matcher的python实现
支持(0)反对(0)
#29楼 2012-09-07
08:10 邓三皮
靠!比书上讲得好,哈哈。 楼主太感谢你了,哈哈
支持(0)反对(0)
#30楼 2012-10-06
09:39 Orangeink
收藏了! 放到evernote里了。
求问博主,第一张图用什么软件制作的?
支持(0)反对(0)
#31楼 2012-10-07
15:31 iamzhaiwei
如何匹配不是以abc开头的单词?
我想到的办法是
p = re.compile(r'\b[d-zA-Z0-9]\w*\b')
支持(0)反对(0)
#32楼 2012-10-07
15:32 iamzhaiwei
有什么更好的办法吗?
支持(0)反对(0)
#33楼 2012-10-17
23:36 MyDetail
虽然写的很漂亮,当对我这个初学者,没有找到我要的点,为什么你的示例都用的常量啊,来个变量就更好啦
支持(1)反对(0)
#34楼 2012-12-07
14:42 txwsqk
这样的排版不管是自己看,还是别人看都看着舒服清晰明了,赞一个,果断收藏.
支持(0)反对(0)
#35楼 2013-03-09
21:49 xiangzi888
match方法不能匹配字串吗?re.match(r'hello', 'sd hellofgd ') 返回是空啊。。。
支持(0)反对(0)
#36楼[楼主] 2013-03-09
23:22 AstralWind
@xiangzi888
严格地说,你这个需求指的是搜索,所以你应该用search()。
支持(0)反对(0)
#37楼 2013-04-04
17:38 account51
非常感谢博主,对Python中的RE终于能够理解一些了。有两个问题想请教一下博主,
1. 如果一个分组会匹配多个字串,比如:
(?:\((\w*)\))+
用来匹配:
(abc)(123)(xyz)
采用\1来获取分组时,只能得到最后一次匹配结果,也就是xyz.
怎样才能获取abc和123的值呢?
2. 记得在哪里看到过Perl可以实现将小写字符到大写字符的转换,写法大概类似于这样(记不清了,可能写得不对):s/[a-z]/[A-Z]
在python中正则支持这样的用法吗?也就是不借助Python本身的函数如uppercase()等,而用正则来实现一个字符集到另一个字符集之间的映射转换(不限于大小写字符之间的转换)。
先谢谢博主了!
支持(0)反对(0)
#38楼 2013-04-14
16:46 moreeffort
@xiangzi888
引用
match方法不能匹配字串吗?re.match(r'hello', 'sd hellofgd ') 返回是空啊。。。
match()函数只检测RE是不是在string的开始位置匹配, search()会扫描整个string查找匹配, 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none
例如:
print(re.match(‘super’, ‘superstition’).span())会返回(0, 5)
而print(re.match(‘super’, ‘insuperable’))则返回None
search()会扫描整个字符串并返回第一个成功的匹配
例如:print(re.search(‘super’, ‘superstition’).span())返回(0, 5)
print(re.search(‘super’, ‘insuperable’).span())返回(2, 7)
内容来自网络
支持(0)反对(0)
#39楼[楼主] 2013-04-16
20:28 AstralWind
@account51
引用非常感谢博主,对Python中的RE终于能够理解一些了。有两个问题想请教一下博主,
1. 如果一个分组会匹配多个字串,比如:
(?:\((\w*)\))+
用来匹配:
(abc)(123)(xyz)
采用\1来获取分组时,只能得到最后一次匹配结果,也就是xyz.
怎样才能获取abc和123的值呢?
2. 记得在哪里看到过Perl可以实现将小写字符到大写字符的转换,写法大概类似于这样(记不清了,可能写得不对):s/[a-z]/[A-Z]
在python中正则支持这样的用法吗?也就是不借助Python本身的函数如uppercase()等,而用正则来实现一个字符集到另一个字符集之间的映射转换...
1. 无法获取这两个值,因为正则表达式本身不支持。为什么呢?
除了必然会增加实现复杂度、影响正则引擎的编译效率和匹配效率以外,仔细想想,这个需求本身就是不存在的。无论你需要获取第几个被覆盖的分组,都可以使用另外一个并不会长太多的正则表达式替代。
2. Python中不支持这种用法,必须使用函数。
支持(0)反对(0)
#40楼 2013-06-09
11:22 bhfo
让我很好理解了正则。
博主,有个问题想问问,我用的是3.3
是2.2的例子
import re
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
print "m.string:", m.string
……
编释出来
print("m.string:",m.string)
AttributeError: 'NoneType' object has no attribute 'string'
支持(0)反对(0)
刷新评论刷新页面返回顶部
注册用户登录后才能发表评论,请 登录 或 注册,访问网站首页。
博客园首页博问新闻闪存程序员招聘知识库
最新IT新闻:
· 圆通快递单被倒卖背后:一流硬件三流管理
· Twidere 开发者:95后的宅里奥
· WE大会马化腾要告诉我们什么?
· IE曝0day漏洞 影响XP及Win7系统
· 双11不眠夜:天猫京东不再二选一 挑战物流极限
» 更多新闻...
最新知识库文章:
· 一个IT人士的个人经历,给迷失方向的朋友
· 程序员最头疼的事:命名
· 工程师文化
· Serif和Sans-serif字体的区别
· 如何学习Javascript
» 更多知识库文章...
我的随笔
我的评论
我的参与
最新评论
我的标签
更多链接
Java(3)
JDK(1)
动态代理(1)
映射(1)
Calendar(1)
Hibernate(1)
Java(4)
Java web(1)
Other(1)
Python(13)
随笔(2)
学习笔记(3)
2011年7月 (3)
2011年6月 (2)
2011年3月 (2)
2011年1月 (1)
2010年12月 (2)
2010年7月 (1)
2010年6月 (2)
2009年12月 (6)
1. Re:博客启动计划&我个人理解的Python优缺点
为何要 哈哈(笑) 难道读者看不出 哈哈是在笑么?
--wisdomoon
2. Re:Python字符编码详解
非常有价值!
--紫禁之巅
3. Re:为什么我们用Python?
还可以这样子:
import string
mystr="1234"
table=string.maketrans(string.digits[1:5],string.digits[5:9])
print string.translate(mystr,table)
--一切有为法应作如是观
4. Re:Python字符编码详解
大牛说话真幽默,很好,很强大
--itatkakaxi2
5. Re:Python装饰器与面向切面编程
看了,有个疑问呀,
就是在修饰函数中, 不能使用 func() 而应该是 return func(), 我用过。
第二个问题就是 在 wrapper()调用 return func()就返回了, 有个变通方法,就是try: return func(); finally: xxxx
如有不对,请多指教,谢谢
--sam shenhz1
1. Python正则表达式指南(126979)
2. Python线程指南(25240)
3. Python字符编码详解(20888)
4. Python自省(反射)指南(16687)
5. Python装饰器与面向切面编程(16134)
1. Python正则表达式指南(40)
2. Python字符编码详解(25)
3. Python装饰器与面向切面编程(23)
4. Python线程指南(15)
5. 继承自java.util.Calendar的200年农历(12)
Copyright ©2013 AstralWind
AstralWind
首页
博问
闪存
订阅
管理
Python正则表达式指南
本文介绍了Python对于正则表达式的支持,包括正则表达式基础以及Python正则表达式标准库的完整介绍及使用示例。本文的内容不包括如何编写高效的正则表达式、如何优化正则表达式,这些主题请查看其他教程。注意:本文基于Python2.4完成;如果看到不明白的词汇请记得百度谷歌或维基,whatever。
尊重作者的劳动,转载请注明作者及原文地址 >.<html
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。下图展示了使用正则表达式进行匹配的流程:
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):
返回(start(group), end(group))。
expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
pattern: 编译时用的表达式字符串。
flags: 编译时用的匹配模式。数字形式。
groups: 表达式中分组的数量。
groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
搜索string,以列表形式返回全部能匹配的子串。
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
返回 (sub(repl, string[, count]), 替换次数)。
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
全文结束
分类: 学习笔记, Python
绿色通道: 好文要顶 关注我 收藏该文与我联系
AstralWind
关注 - 1
粉丝 - 145
+加关注
71
0
(请您对文章做出评价)
« 上一篇:Python线程指南
» 下一篇:Python字符编码详解
posted @ 2010-07-04 23:56 AstralWind 阅读(126979)
评论(40) 编辑 收藏
评论列表
#1楼 2010-07-06
14:08 Lucker
精彩,好文!
支持(1)反对(0)
#2楼 2010-12-17
11:20 iTech
超级好文,转载了
支持(1)反对(0)
#3楼 2010-12-17
11:24 iTech
此文实在是太好了,我转载了,点击率超级高啊,打破了历史水平啊!高的我都不好意思啊!我只是想收藏此精彩文章,没有其他的意思。
支持(0)反对(0)
#4楼[楼主] 2010-12-17
21:35 AstralWind
@iTech
对大家有帮助就好,也没打算靠版权挣钱呵呵~
支持(1)反对(0)
#5楼 2011-05-06
10:59 青怪
很好的文章,学习了。谢谢!
支持(0)反对(0)
#6楼 2011-06-28
10:37 Sackula[未注册用户]
宇宙无敌好文~~~~~~~~
#7楼 2011-07-20
15:35 vijay
不错,收藏并转载
支持(0)反对(0)
#8楼 2011-07-31
03:50 dawb[未注册用户]
非常好,写的深入浅出
#9楼 2011-07-31
09:48 lidashuang
非常不错,博主第一图是用什么工具做的?
支持(0)反对(0)
#10楼[楼主] 2011-07-31
12:54 AstralWind
@lidashuang
PowerPoint :)
支持(0)反对(0)
#11楼 2011-08-14
10:24 junjie020[未注册用户]
您好!
有一个问题关于python的条件表达式的
我发现,如果在条件表达式里面,使用别名,python是不行的(我使用的版本是2.7.2和3.2.1)
如 :
reobj = re.match(r"(?P<N1>8)(?(?P=N1)8)", "88")
这样是无法匹配的,如果使用:
reobj = re.match(r"(8)(?(1)8", "88")
这样是可以的,不知道楼主是否有试过这样使用别名来引用条件表达式呢?还是我有没有写错的?
希望指教!
#12楼[楼主] 2011-08-15
09:43 AstralWind
@junjie020
你好!抱歉回复晚了,是这样,你第一个正则
支持(0)反对(0)
#13楼 2011-10-03
22:24 shirne
python的正则很强大,学习收藏了
支持(0)反对(0)
#14楼 2011-11-07
11:59 eason@pku
不错.
支持(0)反对(0)
#15楼 2011-12-09
15:03 qqzhao
不错...
支持(0)反对(0)
#16楼 2011-12-19
17:16 你能记住几个
您好,能不能分享下文中的图片和表格是用什么软件画的,很好看啊
支持(0)反对(0)
#17楼[楼主] 2011-12-19
18:46 AstralWind
@你能记住几个
ms office
支持(0)反对(0)
#18楼 2011-12-25
17:47 会长
好哇,我每次写正则表达式时,都来这看。脑子不行,记不住规则,只能随写随查
支持(0)反对(0)
#19楼 2011-12-26
17:02 pyt123
谢谢楼主分享
支持(0)反对(0)
#20楼 2012-01-19
10:01 naslang[未注册用户]
不错,受益了。
#21楼 2012-02-12
15:53 ruyunlong[未注册用户]
我也顶一下,哈哈,感谢楼主奉献
#22楼 2012-02-25
15:40 dazi
好东西 python 是个好东西 正则也是个好东西
支持(0)反对(0)
#23楼 2012-02-29
17:08 mimicom
这个我经常来看..... 呵呵...
支持(0)反对(0)
#24楼 2012-03-09
11:20 mimicom
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
奇怪... 怎么会有第三组? .
(?P<sign>.*) 这个是别名啊?.. 难道因为后面的 .* 也在括号里面?对应的后面的感叹号.
支持(0)反对(0)
#25楼 2012-03-09
11:26 mimicom
哦..明白了...
(?P<sign>.*)
sign是.*的别名...
支持(0)反对(0)
#26楼 2012-03-12
11:25 villion
文章太好了!!!
支持(0)反对(0)
#27楼 2012-06-29
10:02 TonyKong
cnblog博文的质量普遍很高啊。收藏了
支持(0)反对(0)
#28楼 2012-07-17
15:25 小北北北
就是java里面的Pattern Matcher的python实现
支持(0)反对(0)
#29楼 2012-09-07
08:10 邓三皮
靠!比书上讲得好,哈哈。 楼主太感谢你了,哈哈
支持(0)反对(0)
#30楼 2012-10-06
09:39 Orangeink
收藏了! 放到evernote里了。
求问博主,第一张图用什么软件制作的?
支持(0)反对(0)
#31楼 2012-10-07
15:31 iamzhaiwei
如何匹配不是以abc开头的单词?
我想到的办法是
p = re.compile(r'\b[d-zA-Z0-9]\w*\b')
支持(0)反对(0)
#32楼 2012-10-07
15:32 iamzhaiwei
有什么更好的办法吗?
支持(0)反对(0)
#33楼 2012-10-17
23:36 MyDetail
虽然写的很漂亮,当对我这个初学者,没有找到我要的点,为什么你的示例都用的常量啊,来个变量就更好啦
支持(1)反对(0)
#34楼 2012-12-07
14:42 txwsqk
这样的排版不管是自己看,还是别人看都看着舒服清晰明了,赞一个,果断收藏.
支持(0)反对(0)
#35楼 2013-03-09
21:49 xiangzi888
match方法不能匹配字串吗?re.match(r'hello', 'sd hellofgd ') 返回是空啊。。。
支持(0)反对(0)
#36楼[楼主] 2013-03-09
23:22 AstralWind
@xiangzi888
严格地说,你这个需求指的是搜索,所以你应该用search()。
支持(0)反对(0)
#37楼 2013-04-04
17:38 account51
非常感谢博主,对Python中的RE终于能够理解一些了。有两个问题想请教一下博主,
1. 如果一个分组会匹配多个字串,比如:
(?:\((\w*)\))+
用来匹配:
(abc)(123)(xyz)
采用\1来获取分组时,只能得到最后一次匹配结果,也就是xyz.
怎样才能获取abc和123的值呢?
2. 记得在哪里看到过Perl可以实现将小写字符到大写字符的转换,写法大概类似于这样(记不清了,可能写得不对):s/[a-z]/[A-Z]
在python中正则支持这样的用法吗?也就是不借助Python本身的函数如uppercase()等,而用正则来实现一个字符集到另一个字符集之间的映射转换(不限于大小写字符之间的转换)。
先谢谢博主了!
支持(0)反对(0)
#38楼 2013-04-14
16:46 moreeffort
@xiangzi888
引用
match方法不能匹配字串吗?re.match(r'hello', 'sd hellofgd ') 返回是空啊。。。
match()函数只检测RE是不是在string的开始位置匹配, search()会扫描整个string查找匹配, 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none
例如:
print(re.match(‘super’, ‘superstition’).span())会返回(0, 5)
而print(re.match(‘super’, ‘insuperable’))则返回None
search()会扫描整个字符串并返回第一个成功的匹配
例如:print(re.search(‘super’, ‘superstition’).span())返回(0, 5)
print(re.search(‘super’, ‘insuperable’).span())返回(2, 7)
内容来自网络
支持(0)反对(0)
#39楼[楼主] 2013-04-16
20:28 AstralWind
@account51
引用非常感谢博主,对Python中的RE终于能够理解一些了。有两个问题想请教一下博主,
1. 如果一个分组会匹配多个字串,比如:
(?:\((\w*)\))+
用来匹配:
(abc)(123)(xyz)
采用\1来获取分组时,只能得到最后一次匹配结果,也就是xyz.
怎样才能获取abc和123的值呢?
2. 记得在哪里看到过Perl可以实现将小写字符到大写字符的转换,写法大概类似于这样(记不清了,可能写得不对):s/[a-z]/[A-Z]
在python中正则支持这样的用法吗?也就是不借助Python本身的函数如uppercase()等,而用正则来实现一个字符集到另一个字符集之间的映射转换...
1. 无法获取这两个值,因为正则表达式本身不支持。为什么呢?
除了必然会增加实现复杂度、影响正则引擎的编译效率和匹配效率以外,仔细想想,这个需求本身就是不存在的。无论你需要获取第几个被覆盖的分组,都可以使用另外一个并不会长太多的正则表达式替代。
2. Python中不支持这种用法,必须使用函数。
支持(0)反对(0)
#40楼 2013-06-09
11:22 bhfo
让我很好理解了正则。
博主,有个问题想问问,我用的是3.3
是2.2的例子
import re
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
print "m.string:", m.string
……
编释出来
print("m.string:",m.string)
AttributeError: 'NoneType' object has no attribute 'string'
支持(0)反对(0)
刷新评论刷新页面返回顶部
注册用户登录后才能发表评论,请 登录 或 注册,访问网站首页。
博客园首页博问新闻闪存程序员招聘知识库
最新IT新闻:
· 圆通快递单被倒卖背后:一流硬件三流管理
· Twidere 开发者:95后的宅里奥
· WE大会马化腾要告诉我们什么?
· IE曝0day漏洞 影响XP及Win7系统
· 双11不眠夜:天猫京东不再二选一 挑战物流极限
» 更多新闻...
最新知识库文章:
· 一个IT人士的个人经历,给迷失方向的朋友
· 程序员最头疼的事:命名
· 工程师文化
· Serif和Sans-serif字体的区别
· 如何学习Javascript
» 更多知识库文章...
| ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 27 | 28 | 29 | 30 | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
常用链接
我的随笔我的评论
我的参与
最新评论
我的标签
更多链接
我的标签
Java(3)JDK(1)
动态代理(1)
映射(1)
Calendar(1)
Hibernate(1)
随笔分类
Java(4)Java web(1)
Other(1)
Python(13)
随笔(2)
学习笔记(3)
随笔档案
2011年7月 (3)2011年6月 (2)
2011年3月 (2)
2011年1月 (1)
2010年12月 (2)
2010年7月 (1)
2010年6月 (2)
2009年12月 (6)
最新评论

1. Re:博客启动计划&我个人理解的Python优缺点为何要 哈哈(笑) 难道读者看不出 哈哈是在笑么?
--wisdomoon
2. Re:Python字符编码详解
非常有价值!
--紫禁之巅
3. Re:为什么我们用Python?
还可以这样子:
import string
mystr="1234"
table=string.maketrans(string.digits[1:5],string.digits[5:9])
print string.translate(mystr,table)
--一切有为法应作如是观
4. Re:Python字符编码详解
大牛说话真幽默,很好,很强大
--itatkakaxi2
5. Re:Python装饰器与面向切面编程
看了,有个疑问呀,
就是在修饰函数中, 不能使用 func() 而应该是 return func(), 我用过。
第二个问题就是 在 wrapper()调用 return func()就返回了, 有个变通方法,就是try: return func(); finally: xxxx
如有不对,请多指教,谢谢
--sam shenhz1
阅读排行榜
1. Python正则表达式指南(126979)2. Python线程指南(25240)
3. Python字符编码详解(20888)
4. Python自省(反射)指南(16687)
5. Python装饰器与面向切面编程(16134)
评论排行榜
1. Python正则表达式指南(40)2. Python字符编码详解(25)
3. Python装饰器与面向切面编程(23)
4. Python线程指南(15)
5. 继承自java.util.Calendar的200年农历(12)
Copyright ©2013 AstralWind

相关文章推荐
- python pexpect模块详解附常用脚本
- 简明Python教程 1)介绍 2)安装 3)开始 4)
- python学习笔记之八:迭代器和生成器
- Python开发环境Wing IDE部分调试功能介绍
- Python开发环境Wing IDE使用教程:部分调试功能介绍
- how to keep Lispython in good condition?
- python BeautifulSoup的安装
- 用Python最原始的函数模拟eval函数的浮点数运算功能(2)
- Python3实现的腾讯微博自动发帖小工具
- Python开发环境Wing IDE部分调试功能简介
- python单元测试
- python自然语言处理学习笔记第三章3
- python ctypes 和windows DLL互相调用
- python BDD 框架之lettuce
- python3.x 与 python2.x的区别
- metaclass--Python元类终极解密(五分钟理解)
- python- module
- python 中List 与dictionary
- Python 函数参数*expression 之后为什么只能跟关键字参数
- python之路之python爬虫