一例 jvm file.encoding 属性引起的 MapReduce/HBase 乱码问题
2013-11-05 14:06
381 查看
文章转载自:http://my.oschina.net/leejun2005/blog/157338
最近在往 HBase 写中文的时候,发现 hbase 查出来的数据会有部分中文乱码了,而部分中文又是正常的,按理来说,一般的乱码问题要么全乱,要么不乱。考虑到出现中文的地方都是来源于 hdfs 上的一个配置文件,而这个配置文件可以确定是 utf-8 编码的,那排除了原始文件导致的乱码,想想 MR 代码里也没有转码的逻辑,也排除了代码的问题,那就只有一种可能:Hadoop
集群的系统环境是异构的,这里面可能涉及到 linux 、java 的环境变量、配置的问题。
(1)打印了整个集群的 echo $LANG、echo $LC_ALL 等linux系统变量,发现都是一致的,排除了 os 环境的问题。
(2)剩下的重点放在了 java 环境上,在代码里加上如下两句,打印每条记录的 ip 和 jvm 编码,然后看看乱码的记录是那台机器产生的,并且当时 jvm child 的编码情况:
同时也直接 System.out.println
出相应的中文字段,看是写进 hbase 之前还是之后乱掉的。
跑了一份测试数据后,发现 hbase 里的 ip、jvm 编码是没有规律的,然后查看 syso 打印的 log 发现,在写 hbase 之前已经就已经乱码了,然后想想 hbase 里的数据乱码之所以没有规律是因为
map 后要 shuffle、reduce 才能到 hbase。PS:sysout本身无编码概念,类似 linux 下的 cat、head、more 等。
然后再次把 ip、jvm编码 统计代码放到 map 阶段输出,果真发现了规律,集群中有两台机器的 jvm 编码不一致,不是 utf-8 的:
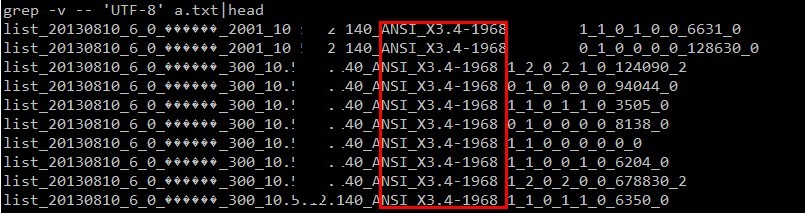
到这里我们可以知道原因了:由于集群中两台机器的 jvm 参数(file.encoding)不一致导致了部分中文结果的乱码。
知道原因了,那就看如何解决了,目的就是要改变 file.encoding 的值 。
由于这个参数是 jvm 的启动参数,运行时不可被更改(你可以理解为这个参数是个全局参数,而且被缓存了,如果一旦运行时更改了, 可能会造成整个 jvm 里面的程序奔溃),你只能修改系统的charset,
或者jvm的启动参数里加上 -Dfile.encoding="UTF-8" 来指定,你运行时 setProperty("file.encoding","ISO-8859-1"); 这样是没用的,so,永久的解决办法是:啥时候把这两台机器offline
改编码后再online,然后再手动执行下 data balance。
不想这么大动干戈,想要临时解决方案,也行,那就需要在咱们自己的业务代码里绕开 jvm 提供的默认 file.encoding 编码,自己指定编码:
上面一句是我之前乱码的代码,如果你没有指定读取编码,那么 jvm 会使用自己的 file.encoding,这样就会造成在某些机器上读取文件就乱掉了。下面一句是自己指定编码,这样绕开了 jvm 的默认编码,与 jvm
从此形同陌路~
PS:FileReader 貌似没有提供指定编码的构造方法,所以换成了下面的类。
为什么之前一直都没乱码,而这次读文件却乱码了呢?
那是因为 hbase 的 Bytes、map 的 fileinputformat key/value、mapreduce
的 context.write 默认都是自己硬编码了 utf-8,做到了 和 jvm 编码无关,所以不会遇到上述问题。
上面说了这么多,可能有同学还是不大明白:jvm 的这参数有毛用啊?为毛之前都没听过这玩意呢?
恩,没听过正常,之前我也没听过哈~
在JDK 1.6.0_20的src.zip文件中,查找包含file.encoding字眼的文件.
共找到4个, 分别是:
(a)先上重头戏 java.nio.Charset类:
在java中,如果没有指定charset的时候,比如new String(byte[] bytes), 都会调用Charset.defaultCharset()的方法,我们可以清楚的看到defaultCharset是只能被初始化一次,这里还是有点小问题的,在多线程并发调用的时候还是会初始话多次,当然后面都是从cache(lookup的函数)里读出来的,问题也不大。
当我们在改变System.getProperties里的file.encoding 的时候,defaultCharset已经被初始化过了,所以不会在调用初始化的代码。
当jvm 启动的时候,load class, 最后调用main函数之前,defaultCharset已经初始化好,而很多函数里都掉用了这个方法象String.getBytes, 还有 InputStreamReader, InputStreamWriter 都是调用了 Charset.defaultCharset()的方法。
(b)java.net.URLEncoder的静态构造方法, 影响到的方法
java.net.URLEncoder.encode(String)
恩,这里也需要注意,之前已经有同学掉坑里去了,请使用:encode(String s, String enc) 方法,此法无侧漏,一觉睡到大天亮~
(c)com.sun.org.apache.xml.internal.serializer.Encoding的getMimeEncoding方法(209行起)
(d)最后一个javax.print.DocFlavor类的静态构造方法
可以看到,系统变量file.encoding影响到
1. Charset.defaultCharset() Java环境中最关键的编码设置
2. URLEncoder.encode(String) Web环境中最常遇到的编码使用
3. com.sun.org.apache.xml.internal.serializer.Encoding 影响对无编码设置的xml文件的读取
4. javax.print.DocFlavor 影响打印的编码
This property is used for the default encoding in Java, all readers and writers would default to use this property. “file.encoding” is set to the default locale of Windows operationg system since Java 1.4.2. System.getProperty(“file.encoding”) can be used to
access this property. Code such as System.setProperty(“file.encoding”, “UTF-8”) can be used to change this property. However, the default encoding can not be changed dynamically even this property can be changed. So the conclusion is that the default encoding
can’t be changed after JVM starts. “java -Dfile.encoding=UTF-8” can be used to set the default encoding when starting a JVM. I have searched for this option Java official documentation. But I can’t find it.
系统变量file.encoding对Java的运行影响有多大?
http://www.blogjava.net/ivanwan/archive/2011/01/31/343810.html
Setting the default Java character encoding?
http://stackoverflow.com/questions/361975/setting-the-default-java-character-encoding
1、问题:
最近在往 HBase 写中文的时候,发现 hbase 查出来的数据会有部分中文乱码了,而部分中文又是正常的,按理来说,一般的乱码问题要么全乱,要么不乱。考虑到出现中文的地方都是来源于 hdfs 上的一个配置文件,而这个配置文件可以确定是 utf-8 编码的,那排除了原始文件导致的乱码,想想 MR 代码里也没有转码的逻辑,也排除了代码的问题,那就只有一种可能:Hadoop集群的系统环境是异构的,这里面可能涉及到 linux 、java 的环境变量、配置的问题。
2、排查:
(1)打印了整个集群的 echo $LANG、echo $LC_ALL 等linux系统变量,发现都是一致的,排除了 os 环境的问题。(2)剩下的重点放在了 java 环境上,在代码里加上如下两句,打印每条记录的 ip 和 jvm 编码,然后看看乱码的记录是那台机器产生的,并且当时 jvm child 的编码情况:
1 | java.net.InetAddress test = java.net.InetAddress.getByName( "localhost" ); |
2 | put.add(Bytes.toBytes( "cf" ), Bytes.toBytes( "ip" ), Bytes.toBytes(test.getLocalHost().getHostAddress())); |
3 | put.add(Bytes.toBytes( "cf" ), Bytes.toBytes( "ec" ), Bytes.toBytes(System.getProperty( "file.encoding" ))); |
出相应的中文字段,看是写进 hbase 之前还是之后乱掉的。
跑了一份测试数据后,发现 hbase 里的 ip、jvm 编码是没有规律的,然后查看 syso 打印的 log 发现,在写 hbase 之前已经就已经乱码了,然后想想 hbase 里的数据乱码之所以没有规律是因为
map 后要 shuffle、reduce 才能到 hbase。PS:sysout本身无编码概念,类似 linux 下的 cat、head、more 等。
然后再次把 ip、jvm编码 统计代码放到 map 阶段输出,果真发现了规律,集群中有两台机器的 jvm 编码不一致,不是 utf-8 的:
到这里我们可以知道原因了:由于集群中两台机器的 jvm 参数(file.encoding)不一致导致了部分中文结果的乱码。
3、解决方案:
知道原因了,那就看如何解决了,目的就是要改变 file.encoding 的值 。
(1)永久方案:
由于这个参数是 jvm 的启动参数,运行时不可被更改(你可以理解为这个参数是个全局参数,而且被缓存了,如果一旦运行时更改了, 可能会造成整个 jvm 里面的程序奔溃),你只能修改系统的charset,或者jvm的启动参数里加上 -Dfile.encoding="UTF-8" 来指定,你运行时 setProperty("file.encoding","ISO-8859-1"); 这样是没用的,so,永久的解决办法是:啥时候把这两台机器offline
改编码后再online,然后再手动执行下 data balance。
(2)临时工方案:
不想这么大动干戈,想要临时解决方案,也行,那就需要在咱们自己的业务代码里绕开 jvm 提供的默认 file.encoding 编码,自己指定编码:1 | BufferedReader in = new BufferedReader( new FileReader(path.toString())); |
2 | 换成: |
3 | BufferedReader in = new BufferedReader(( new InputStreamReader( new FileInputStream(path.toString()), "utf-8" ))); |
从此形同陌路~
PS:FileReader 貌似没有提供指定编码的构造方法,所以换成了下面的类。
(3)疑问:
为什么之前一直都没乱码,而这次读文件却乱码了呢?那是因为 hbase 的 Bytes、map 的 fileinputformat key/value、mapreduce
的 context.write 默认都是自己硬编码了 utf-8,做到了 和 jvm 编码无关,所以不会遇到上述问题。
4、深入理解
jvm 的 -Dfile.encoding 参数
上面说了这么多,可能有同学还是不大明白:jvm 的这参数有毛用啊?为毛之前都没听过这玩意呢?恩,没听过正常,之前我也没听过哈~
(1)从源码开始追踪
在JDK 1.6.0_20的src.zip文件中,查找包含file.encoding字眼的文件.共找到4个, 分别是:
(a)先上重头戏 java.nio.Charset类:
01 | public static Charset
defaultCharset() { |
02 | if (defaultCharset == null )
{ |
03 | synchronized (Charset. class )
{ |
04 | java.security.PrivilegedAction pa = new GetPropertyAction( "file.encoding" ); |
05 | String csn = (String) AccessController.doPrivileged(pa); |
06 | Charset cs = lookup(csn); |
07 | if (cs != null ) |
08 | defaultCharset = cs; |
09 | else |
10 | defaultCharset = forName( "UTF-8" ); |
11 | } |
12 | } |
13 | return defaultCharset; |
14 | } |
当我们在改变System.getProperties里的file.encoding 的时候,defaultCharset已经被初始化过了,所以不会在调用初始化的代码。
当jvm 启动的时候,load class, 最后调用main函数之前,defaultCharset已经初始化好,而很多函数里都掉用了这个方法象String.getBytes, 还有 InputStreamReader, InputStreamWriter 都是调用了 Charset.defaultCharset()的方法。
(b)java.net.URLEncoder的静态构造方法, 影响到的方法
java.net.URLEncoder.encode(String)
恩,这里也需要注意,之前已经有同学掉坑里去了,请使用:encode(String s, String enc) 方法,此法无侧漏,一觉睡到大天亮~
(c)com.sun.org.apache.xml.internal.serializer.Encoding的getMimeEncoding方法(209行起)
(d)最后一个javax.print.DocFlavor类的静态构造方法
可以看到,系统变量file.encoding影响到
1. Charset.defaultCharset() Java环境中最关键的编码设置
2. URLEncoder.encode(String) Web环境中最常遇到的编码使用
3. com.sun.org.apache.xml.internal.serializer.Encoding 影响对无编码设置的xml文件的读取
4. javax.print.DocFlavor 影响打印的编码
(2)Java's file.encoding property on Windows platform
This property is used for the default encoding in Java, all readers and writers would default to use this property. “file.encoding” is set to the default locale of Windows operationg system since Java 1.4.2. System.getProperty(“file.encoding”) can be used toaccess this property. Code such as System.setProperty(“file.encoding”, “UTF-8”) can be used to change this property. However, the default encoding can not be changed dynamically even this property can be changed. So the conclusion is that the default encoding
can’t be changed after JVM starts. “java -Dfile.encoding=UTF-8” can be used to set the default encoding when starting a JVM. I have searched for this option Java official documentation. But I can’t find it.
5、Refer:
系统变量file.encoding对Java的运行影响有多大?http://www.blogjava.net/ivanwan/archive/2011/01/31/343810.html
Setting the default Java character encoding?
http://stackoverflow.com/questions/361975/setting-the-default-java-character-encoding

相关文章推荐
- jvm file.encoding 属性引起的 MapReduce/HBase 乱码问题
- jvm file.encoding 属性引起的storm/hbase乱码
- GDAL写入FileGDB中文属性乱码问题
- geotools修改shapefile 属性名乱码问题
- 工作积累(七)——Tomcat URIEncoding引起的中文乱码问题
- geotools修改shapefile 属性名乱码问题
- geotools获取shapefile 属性名乱码问题
- geotools修改shapefile 属性名乱码问题
- geotools修改shapefile 属性名乱码问题 (转载)
- 工作积累(七)——Tomcat URIEncoding引起的中文乱码问题
- Accept-Encoding 引起乱码的问题
- 关于javaBean属性乱码问题
- struts1.x tag 引起的 form 只生成id属性, 不生成name属性的问题及解决方法
- Troubleshooting:Shapefile 乱码与字符截断问题
- C#中关于搜狗地图web服务api的httpresponse中回应json中文乱码的问题 Encoding
- 【python问题系列--1】SyntaxError:Non-ASCII character '\xe5' in file kNN.py on line 2, but no encoding declared;
- PLSQL Developer 插入中文 乱码问题,如图 这个是由于oracle服务器端字符编码 和 Oracle 客户端 字符编码不一致引起的。 检查Oracle服务器端字符编码,用 sel
- nio FileChannel中文乱码问题
- hbase与mapreduce同时运行的问题
- GeoServer之shapefile中文乱码问题解决方案