高性能的MySQL(5)索引策略-索引案例分析
2013-10-22 20:13
543 查看
理解索引最好的办法是结合实例,接下来分析一个例子。
假设要设计一个在线约会网站,用户信息表有很多列,包括国家,地区,城市,性别,眼睛颜色等等。网站必须支持上面的各种组合来搜索用户,包括根据用户的最后在线时间,评分等进行排序的限制。
需要考虑是需要索引来排序还是先检索数据再排序,因为使用索引排序会严格限制索引和查询的设计。如果MySQL使用了某个索引的范围查询,也就无法再使用另一个索引或者是该索引的后续字段进行排序了。接下来一步步讨论:
1、支持多种过滤条件
country列的选择性通常不高,但是可能很多查询会用到。sex列的选择性很低,但是也会有很多查询用到。所以考虑到使用频率,建议创建不同组合的时候将(country,sex)作为前缀。
这和以前说的不应该在选择性低的列上创建索引是矛盾的,这么做有2个理由:
a、因为sex使用的太频繁。
b、更重要的一点是索引加了这一列没有什么坏处,即使查询没有使用sex,我们也可以通过技巧绕过,那就是在查询条件中增加and sex in ('m','f'),这样写不会过滤任何行,而且能够匹配索引最左前缀,这个非常有效,但是不要让in()列表太长。
因为查询条件的复杂,可能会有很多需要常见的符合索引比如,(sex,country,age),(sex,country,region,age),(sex,country,region,city,age),如果想尽可能重用索引,那么in()技巧是很重要的,但是也不可滥用,如果列表太长的话,组合到一起会很影响性能。
我们会注意到一点,我们一直将age列放到索引的最后面。这是因为age特点,age列会有很多范围查询,而最左前缀中,遇到第一个范围查询,则后面的列索引就不能使用了。
所以一个重要的原则是将范围查询较多的列放在后面。
2、避免多个范围查询
什么是范围查询?从explain的输出很难区分范围查询(<,>,between)和列表值查询in(),因为explain中的type都是range,但是两种访问效率不同,对于后面字段的索引使用也是完全不一样的。前者后面的索引不能用了,后者却可以。
3、优化排序
使用文件排序对小数据是很快的,但是如果上百万数据,如何排序?
比如创建(sex,rating)索引用于下面的排序
通过使用覆盖索引查询返回需要的主键,再根据这写主键关联原表获得需要的行,这可以减少mysql扫描那些需要丢弃的行

看如下2个语句的差别:

可以明显看到时间上的差异,不是在一个量级的。
注意:这个差距在InnoDB里是很明显的,因为只有在InnoDB中,这样子查询的索引才能用到覆盖索引,如果是在MyISAM就不会有这么明显的效果了,如下图:

本文出自 “phper-每天一点点~” 博客,请务必保留此出处http://janephp.blog.51cto.com/4439680/1313556
假设要设计一个在线约会网站,用户信息表有很多列,包括国家,地区,城市,性别,眼睛颜色等等。网站必须支持上面的各种组合来搜索用户,包括根据用户的最后在线时间,评分等进行排序的限制。
需要考虑是需要索引来排序还是先检索数据再排序,因为使用索引排序会严格限制索引和查询的设计。如果MySQL使用了某个索引的范围查询,也就无法再使用另一个索引或者是该索引的后续字段进行排序了。接下来一步步讨论:
1、支持多种过滤条件
country列的选择性通常不高,但是可能很多查询会用到。sex列的选择性很低,但是也会有很多查询用到。所以考虑到使用频率,建议创建不同组合的时候将(country,sex)作为前缀。
这和以前说的不应该在选择性低的列上创建索引是矛盾的,这么做有2个理由:
a、因为sex使用的太频繁。
b、更重要的一点是索引加了这一列没有什么坏处,即使查询没有使用sex,我们也可以通过技巧绕过,那就是在查询条件中增加and sex in ('m','f'),这样写不会过滤任何行,而且能够匹配索引最左前缀,这个非常有效,但是不要让in()列表太长。
因为查询条件的复杂,可能会有很多需要常见的符合索引比如,(sex,country,age),(sex,country,region,age),(sex,country,region,city,age),如果想尽可能重用索引,那么in()技巧是很重要的,但是也不可滥用,如果列表太长的话,组合到一起会很影响性能。
我们会注意到一点,我们一直将age列放到索引的最后面。这是因为age特点,age列会有很多范围查询,而最左前缀中,遇到第一个范围查询,则后面的列索引就不能使用了。
所以一个重要的原则是将范围查询较多的列放在后面。
2、避免多个范围查询
什么是范围查询?从explain的输出很难区分范围查询(<,>,between)和列表值查询in(),因为explain中的type都是range,但是两种访问效率不同,对于后面字段的索引使用也是完全不一样的。前者后面的索引不能用了,后者却可以。
3、优化排序
使用文件排序对小数据是很快的,但是如果上百万数据,如何排序?
比如创建(sex,rating)索引用于下面的排序
select <clos> from profiles where sex='M' order by rating limit 10;如过数据需要翻页,那么比较靠后的查询可能会像这样
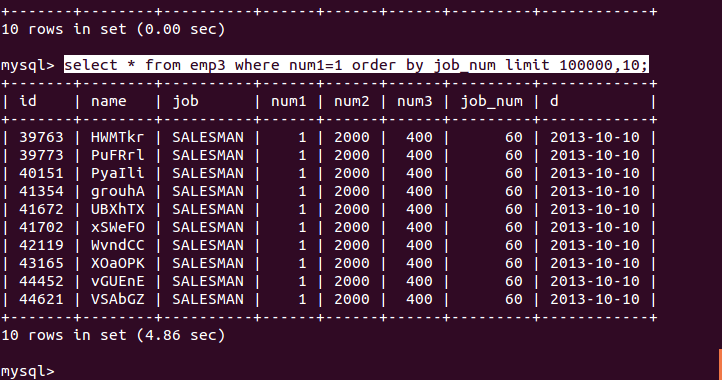
select <cols> from profiles where sex='M' order by rating limit 100000,10;这样即使有合适的索引,依旧是个严重的问题,除了预先计算,缓存可以优化这列问题,令一个比较好的策略是使用延迟关联
通过使用覆盖索引查询返回需要的主键,再根据这写主键关联原表获得需要的行,这可以减少mysql扫描那些需要丢弃的行
select <cols> from profiles inner join( select <primary key cols> from profiles where sex='M' order by rating limit 100000,10) as x using(<primary key cols>);接下来我们看这个例子:
CREATE TABLE `emp3` ( `id` int(11) NOT NULL DEFAULT '0', `name` varchar(100) NOT NULL, `job` varchar(100) NOT NULL, `num1` int(10) DEFAULT NULL, `num2` int(10) DEFAULT NULL, `num3` int(10) DEFAULT NULL, `job_num` int(10) DEFAULT NULL, `d` date DEFAULT NULL, PRIMARY KEY (`id`), KEY `num1` (`num1`,`job_num`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;表里有100万记录,如图:
看如下2个语句的差别:
select * from emp3 where num1=1 order by job_num limit 100000,10;
select * from emp3 inner join ( select id from emp3 where num1=1 order by job_num limit 100000,10) as x using(id);
可以明显看到时间上的差异,不是在一个量级的。
注意:这个差距在InnoDB里是很明显的,因为只有在InnoDB中,这样子查询的索引才能用到覆盖索引,如果是在MyISAM就不会有这么明显的效果了,如下图:
CREATE TABLE `emp4` ( `id` int(11) NOT NULL DEFAULT '0', `name` varchar(100) NOT NULL, `job` varchar(100) NOT NULL, `num1` int(10) DEFAULT NULL, `num2` int(10) DEFAULT NULL, `num3` int(10) DEFAULT NULL, `job_num` int(10) DEFAULT NULL, `d` date DEFAULT NULL, PRIMARY KEY (`id`), KEY `num1` (`num1`,`job_num`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;20W的数据测试结果如下:
本文出自 “phper-每天一点点~” 博客,请务必保留此出处http://janephp.blog.51cto.com/4439680/1313556

相关文章推荐
- Mysql高性能索引的策略
- Java之JVM调优案例分析与实战(1) - 高性能硬件上的程序部署策略
- MySQL索引背后的之使用策略及优化(高性能索引策略)
- JVM调优案例分析与实战:高性能硬件上的程序部署策略
- 高性能的MySQL(5)索引策略一聚簇索引
- MySQL索引背后的之使用策略及优化(高性能索引策略)
- 高性能的MySQL(5)索引策略一聚簇索引
- 高性能可扩展mysql(执行计划,索引分析优化改写,删除重复数据,区间统计,满查询日志)
- 高性能的MySQL(5)索引策略-索引和表的维护
- 高性能的MySQL(5)索引策略-覆盖索引与索引排序
- 高性能的MySQL(5)索引策略一聚簇索引
- MySQL的索引单表优化案例分析
- mysql-高性能索引策略
- mysql-高性能索引策略
- 高性能的MySQL(5)索引策略一压缩,冗余,重复,索引和锁
- MySQL——高性能索引策略
- MySQL 基础与高性能索引策略
- MySQL索引优化的实际案例分析
- 高性能的MySQL(5)索引策略-覆盖索引与索引排序
- MySQL索引背后的之使用策略及优化(高性能索引策略)