MySQL 5.7 的多源复制
2013-10-08 17:14
302 查看
近日ORACLE发布几个新的功能在最新的Mysql5.7.2的版本上,由此有了此篇文章。大多数的改善是在数据库性能和复制相关的功能上,这个新版本会带给我们不可思议的效果。在这篇文章里,我将要用一些简单的步奏来尝试了解这新的多源复制工作原理以及我们怎样进行自己的测试。需要说明的是,这还是一个开发版本,不是给生产环境准备的。因此这篇文章是打算给那些想了解此新功能的人,看看它是如何在应用中工作的,都是在临时环境中进行相关操作。
首先,我们需要清楚 multi-master与multi-source 复制不是一样的. Multi-Master 复制通常是环形复制,你可以在任意主机上将数据复制给其他主机。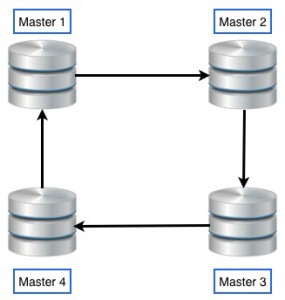 Multi-source 是不同的. MySQL在这个新版本中修复了一个复制限制 , 这限制是一个从站只能有一个主站. 这是一个在我们设计复制环境中的限制因素,也有一些极客使它正常工作了。但是现在有一个官方的解决办法了。所以。简单的说, Multi-Source 意味着一个从站能有一个以上主站. 现在, 像下图一样的复制环境是可能的:
Multi-source 是不同的. MySQL在这个新版本中修复了一个复制限制 , 这限制是一个从站只能有一个主站. 这是一个在我们设计复制环境中的限制因素,也有一些极客使它正常工作了。但是现在有一个官方的解决办法了。所以。简单的说, Multi-Source 意味着一个从站能有一个以上主站. 现在, 像下图一样的复制环境是可能的: 这将帮助我们创建一些复制的层次结构,这在过去是不可能的。 举个例子,你可以 将一个从站放在你的办公室里。在办公室里从所有主站中复制数据传播到世界各地。
这将帮助我们创建一些复制的层次结构,这在过去是不可能的。 举个例子,你可以 将一个从站放在你的办公室里。在办公室里从所有主站中复制数据传播到世界各地。
现在我们有了通信渠道的概念,每一个通信渠道都是一个从服务器从主服务器获得2进制日志的链接。这意味着每个通信渠道都得有一个IO_THREAD .我们需要运行不同的 “CHANGE MASTER” 命令, 对于每一个主服务器。我们需要用到 “FOR CHANNEL”这个参数来提供通信链接的名字。
很容易. 有一个单一的先决条件。从服务器需要在mysql5.6上配置安全功能,这意味着信息通常包含在主服务器上。信息或日志应该在一个表中,让我们开始配置吧
首先你需要下载测试版的mysql。点这个链接:下载.我们需要有一个从服务器和两个主服务器的沙箱环境. 我不会细节的说明怎样配置server_id, binary logs 和 replication users.我假设已经配置好了。 如果你不知道怎么做。你可以看这个链接首先,我们在从服务器上实现事故安全功能。
让后重启从服务器。我们可以开始创建通信渠道,用 “master1″ 和 “master2″这两个名字:
按照所设定的通信名字启动从服务器。
现在我们检查一下从服务器状态:
啊。是空的。我们需要写上通信名字。重新检查下从服务器状态:
我们也可以检查正在运行的 IO_THREAD 和 SQL_THREADS :
测试看一下:
正常工作了。看起来很简单!
这个新的multi-source功能使在过去需要一些复杂操作创建的复制环境变得简单了。当然,你应用程序可以考虑这个新的特性设计和开发,使用 multi-master, multi-source都需要特别注意,不要把你的数据都弄乱了。在每一个新的版本中,mysql的复制功能给我们更多的配置,性能和设计的可能性。所有这些新功能都可以结合起来。在你新(老)的功能中增加复制功能,你的复制环境会更加出色。举个例子:你可以配置 GTID 可以用 multi-threaded
slave per schema或 intra-database.英文原文:MySQL 5.7 multi-source replicationRecently Oracle announced several new features for the latest available development version of MySQL that is 5.7.2 at the time of writing this article. Most of them are performance and replication related that show us how incredible the new release will be.In this post I’m going to try to explain in some easy steps how the new multi-source replication works and how we can configure it for our own tests. It is important to mention that this is a development release, so it is not production ready. Therefore this
post is intend to people that want to test the new feature and see how it works with their application, always in a staging environment.
First, we need to have clear that multi-masterand multi-source replication are not the same. Multi-Master replication is the usual circular replication where you can write on any server and data gets replicated to all others. Multi-source is different. MySQL replication had a limitation, fixed with this new release, that said that one slave could have only one master. That is a
Multi-source is different. MySQL replication had a limitation, fixed with this new release, that said that one slave could have only one master. That is a
limiting factor when we are designing our replication environment. There were some “hacks” to make it work, but now there is an official way. So, in a nutshell, Multi-Source means that a slave can have more than one master. Now, replication environments like
these one are possible: This will help us create some replication hierarchies that were impossible in the past. For example, you can have a slave in your office replicating the data
This will help us create some replication hierarchies that were impossible in the past. For example, you can have a slave in your office replicating the data
from all servers that you have in the offices spread around the world.
Now we have the concept of communication channels. Each communication channel is a connection from slave to masterto get the binary log events. That means we will have one IO_THREAD for each communication channel. We will need to run different “CHANGE MASTER”
commands, one for each master, with the “FOR CHANNEL” argument that we will use to give a name to that channel.Shell
Pretty easy. There is one single pre-requisite. The slave should have been configured first with the crash-safe feature of MySQL 5.6. That means that info usually included in master.info or relay-log.info should be on a table. Let’s start with the configuration.
First you need to download the lab version of mysql from this link.We have a sandbox environment with 2 masters and 1 slave servers. I won’t go over the details of how to configure the server_id, binary logs or replication users. I assume they are well configured. If you need a howto, you can follow this
one.First, we have to enable the crash safe feature on the slave:Shell
After a restart of the slave we can start creating the channels with the names “master1″ and “master2″:Shell
To start the slave processes you need to specify what channel are you referring to:Shell
Now, we want to check the status of the slave:Shell
Oh, it is empty. We have to specify again which channel we want to check:Shell
and we can also check that the IO_THREAD and SQL_THREADS are running:Shell
Let’s test it:Shell
It works, that easy!
The new multi-source feature allow us to create new replication environments that were impossible in the past without some complex “hacks”. Of course, your application should be designed and developed with this new architecture in mind. Like with multi-master,
multi-source needs special care to not end up with your data messed up.MySQL replication is getting better on every release giving us more configuration, performance and design possibilities. And all those new features can be combined. Your replication environment can be even better if you mix some of the new (and old) features
added recently to the replication. For example, you can configure GTID or
enable multi-threaded slave per
schema orintra-database.
什么是多源复制?
首先,我们需要清楚 multi-master与multi-source 复制不是一样的. Multi-Master 复制通常是环形复制,你可以在任意主机上将数据复制给其他主机。Multi-source 是不同的. MySQL在这个新版本中修复了一个复制限制 , 这限制是一个从站只能有一个主站. 这是一个在我们设计复制环境中的限制因素,也有一些极客使它正常工作了。但是现在有一个官方的解决办法了。所以。简单的说, Multi-Source 意味着一个从站能有一个以上主站. 现在, 像下图一样的复制环境是可能的:这将帮助我们创建一些复制的层次结构,这在过去是不可能的。 举个例子,你可以 将一个从站放在你的办公室里。在办公室里从所有主站中复制数据传播到世界各地。
它是怎么工作的呢?
现在我们有了通信渠道的概念,每一个通信渠道都是一个从服务器从主服务器获得2进制日志的链接。这意味着每个通信渠道都得有一个IO_THREAD .我们需要运行不同的 “CHANGE MASTER” 命令, 对于每一个主服务器。我们需要用到 “FOR CHANNEL”这个参数来提供通信链接的名字。1 | CHANGE MASTER MASTER_HOST= 'something' , MASTER_USER=... FOR CHANNEL= "name_of_channel" ; |
来个例子!
首先你需要下载测试版的mysql。点这个链接:下载.我们需要有一个从服务器和两个主服务器的沙箱环境. 我不会细节的说明怎样配置server_id, binary logs 和 replication users.我假设已经配置好了。 如果你不知道怎么做。你可以看这个链接首先,我们在从服务器上实现事故安全功能。1 | master_info_repository= TABLE ; |
2 | relay_log_info_repository= TABLE ; |
1 | slave > change master to master_host= "127.0.0.1" , master_port=12047, master_user= "msandbox" , master_password= "msandbox" for channel= "master1" ; |
2 | slave > change master to master_host= "127.0.0.1" , master_port=12048, master_user= "msandbox" , master_password= "msandbox" for channel= "master2" ; |
1 | slave > start slave for channel= "master1" ; |
2 | slave > start slave for channel= "master2" ; |
1 | slave > show slave status\G |
2 | Empty set (0.00 sec) |
01 | slave > SHOW SL***E STATUS FOR CHANNEL= "master1" \G |
02 | *************************** 1. row *************************** |
03 | Slave_IO_State: Waiting for master to send event |
04 | Master_Host: 127.0.0.1 |
05 | Master_User: msandbox |
06 | Master_Port: 12047 |
07 | Connect_Retry: 60 |
08 | Master_Log_File: mysql-bin.000002 |
09 | Read_Master_Log_Pos: 232 |
10 | Relay_Log_File: squeeze-relay-bin-master1.000003 |
11 | Relay_Log_Pos: 395 |
12 | Relay_Master_Log_File: mysql-bin.000002 |
13 | Slave_IO_Running: Yes |
14 | Slave_SQL_Running: Yes |
15 | [...] |
slave > SHOW PROCESSLIST; |
+ ----+-------------+-----------------------------------------------------------------------------+ |
| Id | User | |
+ ----+-------------+-----------------------------------------------------------------------------+ |
| 2 |system user | Waiting for master to send event| |
| 3 |system user | Slave has read all relay log; waiting for the slave I/O thread to update it | |
| 4 |system user | Waiting for master to send event| |
| 5 |system user | Slave has read all relay log; waiting for the slave I/O thread to update it | |
+ ----+-------------+-----------------------------------------------------------------------------+ |
master1 >[code]create database master1;master2 > [/code] create database master2; |
slave > show databases like 'master%' ; |
+ --------------------+ |
| Database (master%) | |
+ --------------------+ |
| |
| |
+ --------------------+ |
结论
这个新的multi-source功能使在过去需要一些复杂操作创建的复制环境变得简单了。当然,你应用程序可以考虑这个新的特性设计和开发,使用 multi-master, multi-source都需要特别注意,不要把你的数据都弄乱了。在每一个新的版本中,mysql的复制功能给我们更多的配置,性能和设计的可能性。所有这些新功能都可以结合起来。在你新(老)的功能中增加复制功能,你的复制环境会更加出色。举个例子:你可以配置 GTID 可以用 multi-threadedslave per schema或 intra-database.英文原文:MySQL 5.7 multi-source replicationRecently Oracle announced several new features for the latest available development version of MySQL that is 5.7.2 at the time of writing this article. Most of them are performance and replication related that show us how incredible the new release will be.In this post I’m going to try to explain in some easy steps how the new multi-source replication works and how we can configure it for our own tests. It is important to mention that this is a development release, so it is not production ready. Therefore this
post is intend to people that want to test the new feature and see how it works with their application, always in a staging environment.
What is multi-source replication?
First, we need to have clear that multi-masterand multi-source replication are not the same. Multi-Master replication is the usual circular replication where you can write on any server and data gets replicated to all others.Multi-source is different. MySQL replication had a limitation, fixed with this new release, that said that one slave could have only one master. That is alimiting factor when we are designing our replication environment. There were some “hacks” to make it work, but now there is an official way. So, in a nutshell, Multi-Source means that a slave can have more than one master. Now, replication environments like
these one are possible:
This will help us create some replication hierarchies that were impossible in the past. For example, you can have a slave in your office replicating the datafrom all servers that you have in the offices spread around the world.
How does it work?
Now we have the concept of communication channels. Each communication channel is a connection from slave to masterto get the binary log events. That means we will have one IO_THREAD for each communication channel. We will need to run different “CHANGE MASTER”commands, one for each master, with the “FOR CHANNEL” argument that we will use to give a name to that channel.Shell
| 1 | CHANGEMASTERMASTER_HOST='something',MASTER_USER=...FORCHANNEL="name_of_channel"; |
Show me an example!
First you need to download the lab version of mysql from this link.We have a sandbox environment with 2 masters and 1 slave servers. I won’t go over the details of how to configure the server_id, binary logs or replication users. I assume they are well configured. If you need a howto, you can follow thisone.First, we have to enable the crash safe feature on the slave:Shell
| 12 | master_info_repository=TABLE;relay_log_info_repository=TABLE; |
| 12 | slave>changemastertomaster_host="127.0.0.1",master_port=12047,master_user="msandbox",master_password="msandbox"forchannel="master1";slave>changemastertomaster_host="127.0.0.1",master_port=12048,master_user="msandbox",master_password="msandbox"forchannel="master2"; |
| 12 | slave>startslaveforchannel="master1";slave>startslaveforchannel="master2"; |
| 12 | slave>showslavestatus\GEmptyset(0.00sec) |
| 123456789101112131415 | slave>SHOWSL***ESTATUSFORCHANNEL="master1"\G***************************1.row***************************Slave_IO_State:Waitingformastertosendevent Master_Host:127.0.0.1 Master_User:msandbox Master_Port:12047 Connect_Retry:60Master_Log_File:mysql-bin.000002Read_Master_Log_Pos:232Relay_Log_File:squeeze-relay-bin-master1.000003 Relay_Log_Pos:395Relay_Master_Log_File:mysql-bin.000002 Slave_IO_Running:Yes Slave_SQL_Running:Yes[...] |
| 123456789 | slave>SHOWPROCESSLIST;+----+-------------+-----------------------------------------------------------------------------+|Id|User|State|+----+-------------+-----------------------------------------------------------------------------+| 2|systemuser|Waitingformastertosendevent|| 3|systemuser|Slavehasreadallrelaylog;waitingfortheslaveI/Othreadtoupdateit|| 4|systemuser|Waitingformastertosendevent|| 5|systemuser|Slavehasreadallrelaylog;waitingfortheslaveI/Othreadtoupdateit|+----+-------------+-----------------------------------------------------------------------------+ |
| 123456789 | master1>createdatabasemaster1;master2>createdatabasemaster2;slave>showdatabaseslike'master%';+--------------------+|Database(master%)|+--------------------+|master1 ||master2 |+--------------------+ |
Conclusion
The new multi-source feature allow us to create new replication environments that were impossible in the past without some complex “hacks”. Of course, your application should be designed and developed with this new architecture in mind. Like with multi-master,multi-source needs special care to not end up with your data messed up.MySQL replication is getting better on every release giving us more configuration, performance and design possibilities. And all those new features can be combined. Your replication environment can be even better if you mix some of the new (and old) features
added recently to the replication. For example, you can configure GTID or
enable multi-threaded slave per
schema orintra-database.

相关文章推荐
- 初试mysql5.7.2新特性:多源复制(MySQL 5.7 multi-source replication)
- MySQL5.7的多源复制
- MySQL5.7之多源复制&Nginx中间件(上)【转】
- MySQL 5.7 的多源复制
- MySQL 5.7 的多源复制
- MySQL 5.7的多源复制
- 【数据库】MySQL 5.7 的多源复制
- MySQL5.7新特性之Multi-Source多源复制
- mysql5.7 多源复制
- mysql 5.7的多源复制搭建
- MySQL 5.7 的多源复制
- mysql 5.7 多源复制 原创
- MySQL 5.7的多源复制
- MySQL5.7 基于GTID的多源复制
- MySQL 5.7 的多源复制
- mysql多源复制
- mysql 5.7 主从复制
- MySQL 5.7 并行复制实现原理与调优
- Mysql 5.7从节点配置多线程主从复制的方法详解
- Mysql 5.7主主复制配置