[python]第一炮:抓取图片的小爬虫
2013-10-03 10:15
295 查看
24K纯菜鸟的学习笔记,欢迎批评指点!
思路:通过查看页面源代码获取图片信息,即图片地址
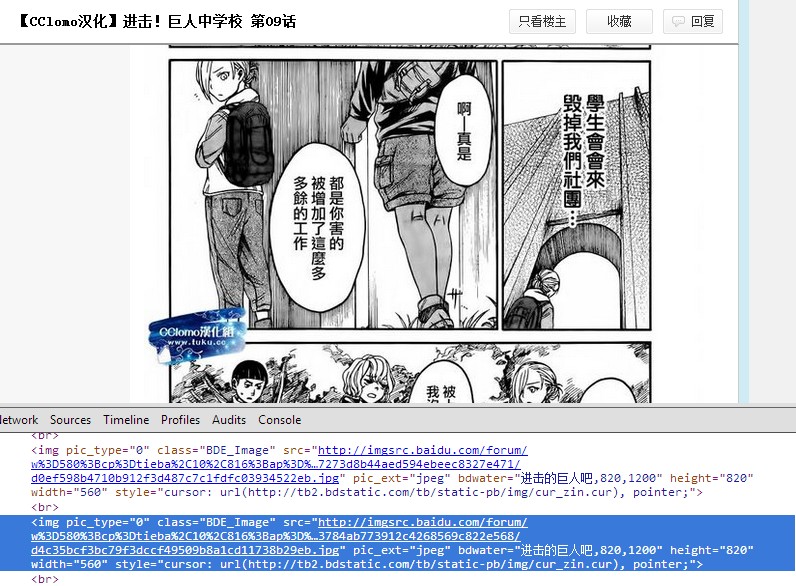
如上图:
图片对应的地址为:src='".*?\.jgp" pic_ext',该正则包括所有".jpg"格式图片的地址。所以下载的时候就去找命中这条正则的地址。
至此,我们知道了需要引如正则表达式组件“re”,以及打开网页的组件“urllib”。urllib组件有个方法用来打开网页,即:urllib.urlopen()
一个小爬虫诞生了,虽然功能很简单,但是在批量下载苍老师图片的时候可以很快搞定,再也不用一张一张右击保存了

思路:通过查看页面源代码获取图片信息,即图片地址
如上图:
图片对应的地址为:src='".*?\.jgp" pic_ext',该正则包括所有".jpg"格式图片的地址。所以下载的时候就去找命中这条正则的地址。
至此,我们知道了需要引如正则表达式组件“re”,以及打开网页的组件“urllib”。urllib组件有个方法用来打开网页,即:urllib.urlopen()
#!/usr/bin/python
import re
import urllib
#定义一个函数getHtml(),通过url获取页面源代码
def getHtml(url):
page=urllib.urlopen(url)
html=page.read()
return html
定义一个函数getJpg()
def getJpg(html):
reg=r'src="(.*?\.jpg)" pic_ext' #获得图片地址
jpgre=re.compile(reg) #编译正则,让正则跑的更快
jpglist=re.findall(jpgre,html) #返回所有匹配数据
x=0
for jpgurl in jpglist:
urllib.urlretrieve(jpgurl,'%s.jpg' % x) #下载文件,并重命名
x+=1
html= getHtml("http://tieba.baidu.com/p/2622651859")
print getJpg(html)一个小爬虫诞生了,虽然功能很简单,但是在批量下载苍老师图片的时候可以很快搞定,再也不用一张一张右击保存了

相关文章推荐
- python小爬虫—抓取pixabay网站的图片资源
- 一个简单的python爬虫,抓取单个页面的图片
- 第一个python程序,小爬虫--抓取网页图片
- 【python】100行代码python爬虫程序,抓取网站图片存储本地(附:中文链接解决)
- Python3简单爬虫抓取网页图片
- <四>、python爬虫抓取购物网站商品信息--图片价格名称
- python爬虫之抓取网页中的图片到本地
- 第二个python爬虫 多页面抓取美女图片
- Python使用爬虫抓取美女图片并保存到本地的方法【测试可用】
- Python3爬虫抓取TP官网案例图片
- Python3简单爬虫抓取网页图片
- Python爬虫学习笔记二:百度贴吧网页图片抓取
- Python爬虫抓取虎扑论坛帖子图片
- python爬虫 -- 抓取网页中链接的静态图片
- Python爬虫之一 PySpider 抓取淘宝MM的个人信息和图片
- python实现简单爬虫抓取图片
- 用python爬虫抓取知乎图片
- Python爬虫抓取糗百的图片,并存储在本地文件夹
- Python爬虫---------------<妹子图>图片抓取(1)