决策树的ID3算法实现(Python版)
2013-09-24 22:41
591 查看
from math import log
def calcShannonEnt(dataSet): //计算你传给我的数据集的熵 输入参数: 数据集合
numEntries=len(dataSet)
labelCounts={}
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt=0.0
for key in labelCounts:
prob=float(labelCounts[key])/numEntries
shannonEnt-=prob*log(prob,2)
return shannonEnt
def createDataSet(): //创建数据集
dataSet=[[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
labels=['no surfacing','flippers']
return dataSet,labels
def createLabels(): //创建特征属性集合
labels=['no surfacing','flippers']
return labels
def splitDataSet(dataSet,axis,value): //将原特征集按照第axis属性 划分成子属性集 输入参数: 数据集合 特征属性下标axis 第axis属性特征值
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet): //选择最后的特征划分子属性集,该函数需要调用 splitDataSet函数 输入参数: 数据集合
numFeatures=len(dataSet[0])-1
baseEntropy=calcShannonEnt(dataSet)
bestInfoGain=0.0;bestFeature=-1
for i in range(numFeatures):
featList=[example[i] for example in dataSet]
uniqueVals=set(featList)
newEntropy=0.0
for value in uniqueVals:
subDataSet=splitDataSet(dataSet,i,value)
prob=len(subDataSet)/float(len(dataSet))
newEntropy+=prob*calcShannonEnt(subDataSet)
infoGain=baseEntropy-newEntropy
if infoGain>bestInfoGain:
bestInfoGain=infoGain
bestFeature=i
return bestFeature
分析公式:
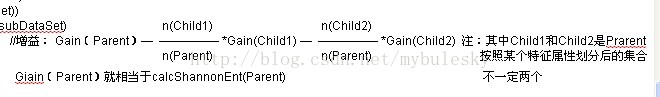
def majorityCnt(classList): //对于决策树构造到最后了,子数据集还包含好多类型,我们就用这个多数表决器函数,认为子数据集中类型较多的为最终的类型
classCount={} 输入参数: 子数据集的类型集合列表
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCOunt[vote]+=1
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels): //该函数构造决策树 输入参数: 数据集合 特征属性集合
classList=[example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
for value in uniqueVals:
subLabels=labels[:]
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
def getNumLeafs(myTree): //获得构造好的决策树叶子节点个数 输入参数:决策树
numLeafs=0
firstStr=myTree.keys()[0]
secondDict=myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs+=getNumLeafs(secondDict[key])
else: numLeafs+=1
return numLeafs
def getTreeDepth(myTree): //获得构造好的决策树深度 输入参数:决策树
maxDepth=0
firstStr=myTree.keys()[0]
secondDict=myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth=1+getNumLeafs(secondDict[key])
else: thisDepth=1
if thisDepth>maxDepth: maxDepth=thisDepth
return maxDepth
def classify(inputTree,featLabels,testVec): //使用决策树,对我们样本按照构造的对决策树进行分类 返回类型 输入参数:决策树 特征属性集合 测试样本
firstStr=inputTree.keys()[0]
secondDict=inputTree[firstStr]
featIndex=featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex]==key:
if type(secondDict[key]).__name__=='dict':
classLabel=classify(secondDict[key],featLabels,testVec)
else: classLabel=secondDict[key]
return classLabel
结果:
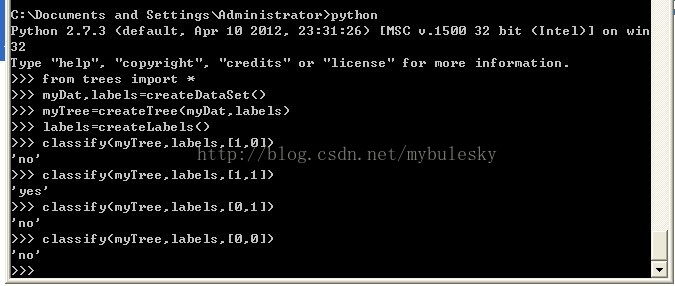
、
def calcShannonEnt(dataSet): //计算你传给我的数据集的熵 输入参数: 数据集合
numEntries=len(dataSet)
labelCounts={}
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt=0.0
for key in labelCounts:
prob=float(labelCounts[key])/numEntries
shannonEnt-=prob*log(prob,2)
return shannonEnt
def createDataSet(): //创建数据集
dataSet=[[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
labels=['no surfacing','flippers']
return dataSet,labels
def createLabels(): //创建特征属性集合
labels=['no surfacing','flippers']
return labels
def splitDataSet(dataSet,axis,value): //将原特征集按照第axis属性 划分成子属性集 输入参数: 数据集合 特征属性下标axis 第axis属性特征值
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet): //选择最后的特征划分子属性集,该函数需要调用 splitDataSet函数 输入参数: 数据集合
numFeatures=len(dataSet[0])-1
baseEntropy=calcShannonEnt(dataSet)
bestInfoGain=0.0;bestFeature=-1
for i in range(numFeatures):
featList=[example[i] for example in dataSet]
uniqueVals=set(featList)
newEntropy=0.0
for value in uniqueVals:
subDataSet=splitDataSet(dataSet,i,value)
prob=len(subDataSet)/float(len(dataSet))
newEntropy+=prob*calcShannonEnt(subDataSet)
infoGain=baseEntropy-newEntropy
if infoGain>bestInfoGain:
bestInfoGain=infoGain
bestFeature=i
return bestFeature
分析公式:
def majorityCnt(classList): //对于决策树构造到最后了,子数据集还包含好多类型,我们就用这个多数表决器函数,认为子数据集中类型较多的为最终的类型
classCount={} 输入参数: 子数据集的类型集合列表
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCOunt[vote]+=1
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels): //该函数构造决策树 输入参数: 数据集合 特征属性集合
classList=[example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
for value in uniqueVals:
subLabels=labels[:]
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
def getNumLeafs(myTree): //获得构造好的决策树叶子节点个数 输入参数:决策树
numLeafs=0
firstStr=myTree.keys()[0]
secondDict=myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs+=getNumLeafs(secondDict[key])
else: numLeafs+=1
return numLeafs
def getTreeDepth(myTree): //获得构造好的决策树深度 输入参数:决策树
maxDepth=0
firstStr=myTree.keys()[0]
secondDict=myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth=1+getNumLeafs(secondDict[key])
else: thisDepth=1
if thisDepth>maxDepth: maxDepth=thisDepth
return maxDepth
def classify(inputTree,featLabels,testVec): //使用决策树,对我们样本按照构造的对决策树进行分类 返回类型 输入参数:决策树 特征属性集合 测试样本
firstStr=inputTree.keys()[0]
secondDict=inputTree[firstStr]
featIndex=featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex]==key:
if type(secondDict[key]).__name__=='dict':
classLabel=classify(secondDict[key],featLabels,testVec)
else: classLabel=secondDict[key]
return classLabel
结果:
、

相关文章推荐
- Python的异常处理
- python中类的设计问题(一些高级问题探讨,函数重载,伪私有,工厂模式,类方法等)
- 确定当前Python环境中的site-packages目录位置
- Python mysqldb模块
- 设置IP的python程序
- python idle 清屏问题的解决
- Python学习之路二开发工具eclipse(Eclipse3.X)插件的详细配置
- Python学习之路一 开发环境的配置
- python双划线类型
- [python] spider 01
- Python中使用中文
- python中PyQwt的使用 画图(一)
- python sqlite3插入测试
- ubuntu13.04 python版本切换
- Python压缩Sqlite3数据库
- python打开pdf(python的os模块)
- python写文件
- 新浪微博Python登陆
- python 开源软件整理
- Python正则表达式指南