Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
2013-09-09 10:11
579 查看
Lucene.Net中,分词是核心库之一,当然,也可以将它独立出来。目前Lucene.Net的分词库很不完善,实际应用价值不高。唯一能用在实际场合的StandardAnalyzer类,效果也不是很好。内置在Lucene.Net里的分词都被放在项目的Analysis目录下,也就是Lucene.Net.Analysis命名空间下。分词类的命名一般都是以“Analyzer”结束,比如StandardAnalyzer,StopAnalyzer,SimpleAnalyzer等。全部继承自Analyzer类。而它们一般各有一个辅助类,一般以”“Tokenizer”结尾,分词的逻辑大都在辅助类完成。
使用Lucene.Net,要很好地使用Lucene.Net,必须理解分词,甚至能自己扩展分词。如果只使用拉丁语系,那么使用内置的分词可能足够了,但是对于中文肯定是不行的。目前中文方面的分词分为单字分词,二元分词,词库匹配,语义理解这几种。StandardAnalyzer类就是按单字分,二元分就是把两个字作为一组拆分,而词库的话肯定是有一个复杂的对比过程,语义理解的就更加复杂了。这是分词的方式,而匹配的方式也分为正向和逆向两种,一般逆向要优于正向,但是写起来也要复杂一些。
1、内置分词器
本节将详细介绍Lucene.Net内置分词的效果,工作过程,及整体结构。
1.1、分词效果
1.1.1 如果得到分词效果
如果得到分词效果?有效的方式就是进行测试。这里将引入自动测试的方法,这样更加便于测试,将使用NUnit来完成。Nunit的简单实用方法见附录二。
创建一个新的项目,命名为Test。步骤如图 1.1.1.1 - 1.1.1.2
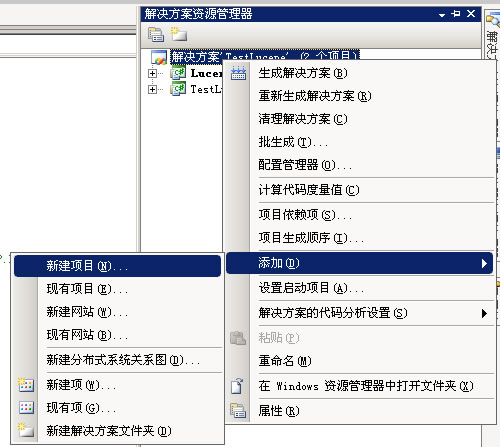
图1.1.1.1
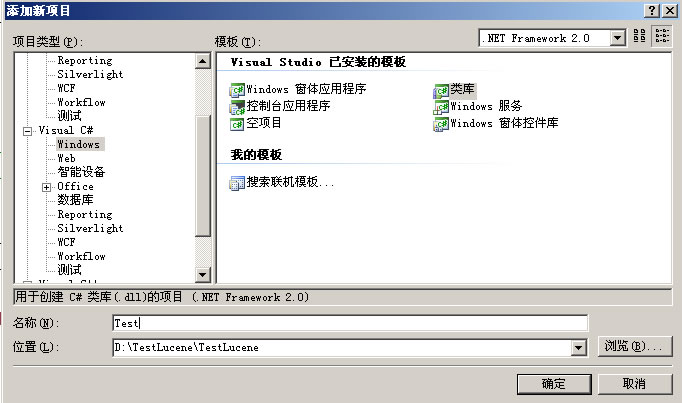
图 1.1.1.2
点确定,就加入了新项目Test,选择类库模板。再引用Nunit.framework类库。如图 1.1.1.3。
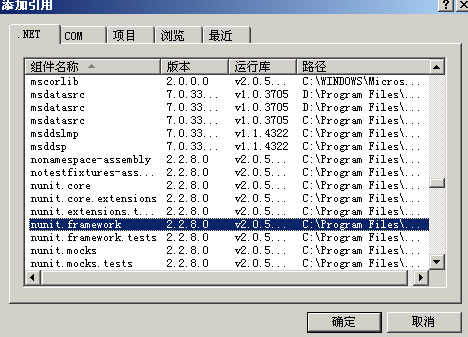
图 1.1.1.3
再按第一章节的步骤引入Lucene.Net类库。先来试试SimpleAnalyzer类的效果。在Test项目中添加SimpleAnalyzerTest,代码 1.1.1.1。
代码 1.1.1.1

1

using System;
2
using System.Collections.Generic;
3
using System.Text;
4
using NUnit.Framework;
5
using Lucene.Net.Analysis;
6
using System.IO;
7
namespace Test
8
{
9

[TestFixture]
10
public class SimpleAnalyzerTest
11

{
12
[Test]
13
public void ReusableTokenStreamTest()
14
{
15
string testwords = "我是中国人,I can speak chinese!";
16
17
SimpleAnalyzer simple = new SimpleAnalyzer();
18
TokenStream ts = simple.ReusableTokenStream("", new StringReader(testwords));
19
Token token;
20
while ((token = ts.Next()) != null)
21
{
22
Console.WriteLine(token.TermText());
23

}
24
ts.Close();
25
}
26
}
27

}
28
运行结果:
我是中国人
i
can
speak
chinese
查看这个结果,基本可以确定,SimpleAnalyzer分词就是以空格或符号为断点,把句子分析出来。对于英文大写还会执行一个转换到小写的操作。
1.1.2 内置分词的分词效果
按照1.1.1节介绍的方式,就可以分析分析效果了。不过这样写出来的测试代码过于麻烦,改造一下。
(1)、在Test项目中新建Analysis目录;
(2)、在Analysis下建立TestData类,代码1.1.2.1;
代码1.1.2.1
1
using System;
2
using System.Collections.Generic;
3
using System.Text;
4
5
namespace Test.Analysis
6
{
7
public class TestData
8
{
9
public static string TestWords = "我是中国人,I can speak chinese!";
10
}
11
}
12
(3)、建立TestFactory类,代码1.1.2.2
代码1.1.2.2

Code
(4)、建立AllAnalysisTest类,代码1.1.2.3
代码1.1.2.3
1
using System;
2
using System.Collections.Generic;
3
using System.Text;
4
using NUnit.Framework;
5
using Lucene.Net.Analysis;
6
using Lucene.Net.Analysis.Standard;
7
namespace Test.Analysis
8
{
9
[TestFixture]
10
public class AllAnalysisTest
11
{
12
[Test]
13
public void TestMethod()
14
{
15
List<Analyzer> analysis = new List<Analyzer>() {
16
new KeywordAnalyzer(),
17
new SimpleAnalyzer(),
18
new StandardAnalyzer(),
19
new StopAnalyzer(),
20
new WhitespaceAnalyzer() };
21
22
for (int i = 0; i < analysis.Count; i++)
23
{
24
Console.WriteLine(analysis[i].ToString() + "结果:");
25
Console.WriteLine("--------------------------------");
26
TestFactory.TestFunc(analysis[i]);
27
Console.WriteLine("--------------------------------");
28
}
29
}
30
}
31
}
32
(5)、运行。
对于TestWords = "我是中国人,I can speak chinese!";测试结果:
Lucene.Net.Analysis.KeywordAnalyzer结果:
--------------------------------
我是中国人,I can speak chinese!
--------------------------------
Lucene.Net.Analysis.SimpleAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.Standard.StandardAnalyzer结果:
--------------------------------
我
是
中
国
人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.StopAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.WhitespaceAnalyzer结果:
--------------------------------
我是中国人,I
can
speak
chinese!
--------------------------------
换一句话试试:更改TestData类TestWords字段值为“我是中国人,I'can speak chinese,hello world,沪江小Q!”。测试结果:
Lucene.Net.Analysis.KeywordAnalyzer结果:
--------------------------------
我是中国人,I'can speak chinese,hello world,沪江小Q!
--------------------------------
Lucene.Net.Analysis.SimpleAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
hello
world
沪江小q
--------------------------------
Lucene.Net.Analysis.Standard.StandardAnalyzer结果:
--------------------------------
我
是
中
国
人
i'can
speak
chinese
沪
江
小
q
--------------------------------
Lucene.Net.Analysis.StopAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
hello
world
沪江小q
--------------------------------
Lucene.Net.Analysis.WhitespaceAnalyzer结果:
--------------------------------
我是中国人,I'can
speak
chinese,hello
world,沪江小Q!
--------------------------------
对于这几种分词效果基本可以看出来了。
KeywordAnalyzer分词,没有任何变化;
SimpleAnalyzer对中文效果太差;
StandardAnalyzer对中文单字拆分;
StopAnalyzer和SimpleAnalyzer差不多;
WhitespaceAnalyzer只按空格划分。
当然,这只是个粗略的结果。
使用Lucene.Net,要很好地使用Lucene.Net,必须理解分词,甚至能自己扩展分词。如果只使用拉丁语系,那么使用内置的分词可能足够了,但是对于中文肯定是不行的。目前中文方面的分词分为单字分词,二元分词,词库匹配,语义理解这几种。StandardAnalyzer类就是按单字分,二元分就是把两个字作为一组拆分,而词库的话肯定是有一个复杂的对比过程,语义理解的就更加复杂了。这是分词的方式,而匹配的方式也分为正向和逆向两种,一般逆向要优于正向,但是写起来也要复杂一些。
1、内置分词器
本节将详细介绍Lucene.Net内置分词的效果,工作过程,及整体结构。
1.1、分词效果
1.1.1 如果得到分词效果
如果得到分词效果?有效的方式就是进行测试。这里将引入自动测试的方法,这样更加便于测试,将使用NUnit来完成。Nunit的简单实用方法见附录二。
创建一个新的项目,命名为Test。步骤如图 1.1.1.1 - 1.1.1.2
图1.1.1.1
图 1.1.1.2
点确定,就加入了新项目Test,选择类库模板。再引用Nunit.framework类库。如图 1.1.1.3。
图 1.1.1.3
再按第一章节的步骤引入Lucene.Net类库。先来试试SimpleAnalyzer类的效果。在Test项目中添加SimpleAnalyzerTest,代码 1.1.1.1。
代码 1.1.1.1
1
using System;
2
using System.Collections.Generic;
3
using System.Text;
4
using NUnit.Framework;
5
using Lucene.Net.Analysis;
6
using System.IO;
7
namespace Test
8
{
9
[TestFixture]
10
public class SimpleAnalyzerTest
11
{
12
[Test]
13
public void ReusableTokenStreamTest()
14
{
15
string testwords = "我是中国人,I can speak chinese!";
16
17
SimpleAnalyzer simple = new SimpleAnalyzer();
18
TokenStream ts = simple.ReusableTokenStream("", new StringReader(testwords));
19
Token token;
20
while ((token = ts.Next()) != null)
21
{
22
Console.WriteLine(token.TermText());
23
}
24
ts.Close();
25
}
26
}
27
}
28
运行结果:
我是中国人
i
can
speak
chinese
查看这个结果,基本可以确定,SimpleAnalyzer分词就是以空格或符号为断点,把句子分析出来。对于英文大写还会执行一个转换到小写的操作。
1.1.2 内置分词的分词效果
按照1.1.1节介绍的方式,就可以分析分析效果了。不过这样写出来的测试代码过于麻烦,改造一下。
(1)、在Test项目中新建Analysis目录;
(2)、在Analysis下建立TestData类,代码1.1.2.1;
代码1.1.2.1
1
using System;
2
using System.Collections.Generic;
3
using System.Text;
4
5
namespace Test.Analysis
6
{
7
public class TestData
8
{
9
public static string TestWords = "我是中国人,I can speak chinese!";
10
}
11
}
12
(3)、建立TestFactory类,代码1.1.2.2
代码1.1.2.2
Code
(4)、建立AllAnalysisTest类,代码1.1.2.3
代码1.1.2.3
1
using System;
2
using System.Collections.Generic;
3
using System.Text;
4
using NUnit.Framework;
5
using Lucene.Net.Analysis;
6
using Lucene.Net.Analysis.Standard;
7
namespace Test.Analysis
8
{
9
[TestFixture]
10
public class AllAnalysisTest
11
{
12
[Test]
13
public void TestMethod()
14
{
15
List<Analyzer> analysis = new List<Analyzer>() {
16
new KeywordAnalyzer(),
17
new SimpleAnalyzer(),
18
new StandardAnalyzer(),
19
new StopAnalyzer(),
20
new WhitespaceAnalyzer() };
21
22
for (int i = 0; i < analysis.Count; i++)
23
{
24
Console.WriteLine(analysis[i].ToString() + "结果:");
25
Console.WriteLine("--------------------------------");
26
TestFactory.TestFunc(analysis[i]);
27
Console.WriteLine("--------------------------------");
28
}
29
}
30
}
31
}
32
(5)、运行。
对于TestWords = "我是中国人,I can speak chinese!";测试结果:
Lucene.Net.Analysis.KeywordAnalyzer结果:
--------------------------------
我是中国人,I can speak chinese!
--------------------------------
Lucene.Net.Analysis.SimpleAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.Standard.StandardAnalyzer结果:
--------------------------------
我
是
中
国
人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.StopAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.WhitespaceAnalyzer结果:
--------------------------------
我是中国人,I
can
speak
chinese!
--------------------------------
换一句话试试:更改TestData类TestWords字段值为“我是中国人,I'can speak chinese,hello world,沪江小Q!”。测试结果:
Lucene.Net.Analysis.KeywordAnalyzer结果:
--------------------------------
我是中国人,I'can speak chinese,hello world,沪江小Q!
--------------------------------
Lucene.Net.Analysis.SimpleAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
hello
world
沪江小q
--------------------------------
Lucene.Net.Analysis.Standard.StandardAnalyzer结果:
--------------------------------
我
是
中
国
人
i'can
speak
chinese
沪
江
小
q
--------------------------------
Lucene.Net.Analysis.StopAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
hello
world
沪江小q
--------------------------------
Lucene.Net.Analysis.WhitespaceAnalyzer结果:
--------------------------------
我是中国人,I'can
speak
chinese,hello
world,沪江小Q!
--------------------------------
对于这几种分词效果基本可以看出来了。
KeywordAnalyzer分词,没有任何变化;
SimpleAnalyzer对中文效果太差;
StandardAnalyzer对中文单字拆分;
StopAnalyzer和SimpleAnalyzer差不多;
WhitespaceAnalyzer只按空格划分。
当然,这只是个粗略的结果。

相关文章推荐
- Lucene.Net 2.3.1开发介绍 —— 二、分词(六)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(四)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(六)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(六)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(五)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(四)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(六)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(四)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(五)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(二)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(二)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
- Lucene.Net 2.3.1开发介绍 —— 二、分词(五)