特征选择和特征学习中的过完备
2013-08-14 19:39
155 查看
ScSPM的论文中提到了码书的过完备(over-complete)。一开始没有太在意过完备有什么问题,今天想了想把这个概念弄明白了。
特征学习的过程中,假设学习的码书D的大小为M。每个码字的维数为N。每个原始特征Yi的维数也为N。假设原始特征投影到码书上以后的特征向量是Xi(M维的矢量),那么用D和Xi对Yi重建的过程就是:Yi=D*Xi。
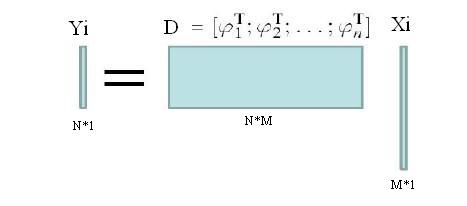
coding的过程就变成了已知Yi和D,求Xi的过程了。显然这是一个非齐次方程组求解的问题,方程组有解的条件是rank(D)≤M,其中取等号时方程组有唯一解。过完备的定义是M>>N,所以此时rank(D)≤N<<M,此时方程组有无穷多解。(你可能会问,这和最小化平方误差为目标函数不一样啊!其实求个导,就变成这个方程组了。)这就是过完备造成的问题了。怎么办呢?办法就是对Xi做约束------稀疏的约束,这样Xi就有唯一解了。这就是需要加约束的原因。而为什么是稀疏的约束,这在我前两博客(这里和这里)中稍微介绍过,这里就不再废话。
特征选择的过程,也是一样的。假设此时有n个样本,每个样本有个measurement(这个measurement可以是regression中的output,也可以是classification中的label)。每个样本的特征是p维的,n个样本的特征组成n*p的矩阵A。目标是对这p维特征做一个选择,选择的系数用x记录。此时将如下图所示:
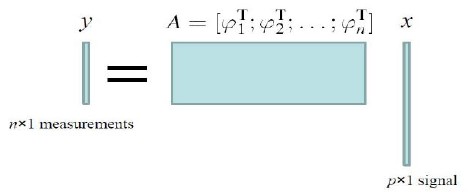
这与第一个图是等价的,特征选择过程中的over-complete是指p>>n,不加约束的情况下x将有无穷多组解,所以和特征学习一样,加系数的约束。xi为0表示相应的特征不被选择。(而xi<0,等价于取一个|xi|,而将相应的特征的值取负号。)
如果measurement不是一维的咋办?比如multi-label的问题。我猜测把x的列维数也扩展成相应大小,然后根据label之间的correlation加低秩等约束吧。
-------------------
作者:jiang1st2010
转载请注明原文地址:http://blog.csdn.net/jwh_bupt/article/details/9969841
特征学习的过程中,假设学习的码书D的大小为M。每个码字的维数为N。每个原始特征Yi的维数也为N。假设原始特征投影到码书上以后的特征向量是Xi(M维的矢量),那么用D和Xi对Yi重建的过程就是:Yi=D*Xi。
coding的过程就变成了已知Yi和D,求Xi的过程了。显然这是一个非齐次方程组求解的问题,方程组有解的条件是rank(D)≤M,其中取等号时方程组有唯一解。过完备的定义是M>>N,所以此时rank(D)≤N<<M,此时方程组有无穷多解。(你可能会问,这和最小化平方误差为目标函数不一样啊!其实求个导,就变成这个方程组了。)这就是过完备造成的问题了。怎么办呢?办法就是对Xi做约束------稀疏的约束,这样Xi就有唯一解了。这就是需要加约束的原因。而为什么是稀疏的约束,这在我前两博客(这里和这里)中稍微介绍过,这里就不再废话。
特征选择的过程,也是一样的。假设此时有n个样本,每个样本有个measurement(这个measurement可以是regression中的output,也可以是classification中的label)。每个样本的特征是p维的,n个样本的特征组成n*p的矩阵A。目标是对这p维特征做一个选择,选择的系数用x记录。此时将如下图所示:
这与第一个图是等价的,特征选择过程中的over-complete是指p>>n,不加约束的情况下x将有无穷多组解,所以和特征学习一样,加系数的约束。xi为0表示相应的特征不被选择。(而xi<0,等价于取一个|xi|,而将相应的特征的值取负号。)
如果measurement不是一维的咋办?比如multi-label的问题。我猜测把x的列维数也扩展成相应大小,然后根据label之间的correlation加低秩等约束吧。
-------------------
作者:jiang1st2010
转载请注明原文地址:http://blog.csdn.net/jwh_bupt/article/details/9969841

相关文章推荐
- 特征选择和特征学习中的过完备
- 【Scikit-Learn 中文文档】特征选择 - 监督学习 - 用户指南 | ApacheCN
- sklearn学习-SVM例程总结2(特征选择——单因素方差分析(方差分析anova ))
- 决策树学习的特征选择
- 特征选择与特征学习
- 【Scikit-Learn 中文文档】特征选择 - 监督学习 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】特征选择 - 监督学习 - 用户指南 | ApacheCN
- 周志华 《机器学习》之 第十一章(特征选择与稀疏学习)概念总结
- 机器学习:特征选择之 Filter :Relief方法
- 基于局部学习的特征选择:Local-Learning-Based Feature Selecti
- 机器学习之特征选择
- 【Scikit-Learn 中文文档】特征选择 - 监督学习 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】特征选择 - 监督学习 - 用户指南 | ApacheCN
- 特征选择与稀疏学习
- 机器学习中,有哪些特征选择的工程方法?
- 机器学习笔记(十一)特征选择和稀疏学习
- 【Scikit-Learn 中文文档】特征选择 - 监督学习 - 用户指南 | ApacheCN
- Scikit-learn 学习笔记--(1)特征选择
- 特征选择和特征抽取(学习小结)
- 【Scikit-Learn 中文文档】特征选择 - 监督学习 - 用户指南 | ApacheCN