linux内核分析笔记----内核可移植性
2013-08-06 19:11
176 查看
关于linux内核的可移植性我不用多说,现在的linux操作系统,你装系统时应该很明白的知道了,很少说(至少我没见到)不兼容不能装的问题。今天就来说说这个问题:
1.字节和数据类型
能够由机器一次就完成处理的数据被称为字,字指位的数目。所以我们常听到机器是多少位的时候,就是指该机的字长。处理器通用寄存器的大小和它的字长是相同的。C语言定义的long类型总对等于机器字长。对于支持的每一种体系结构,Linux都要将<asm/types.h>中的BITS_PER_LONG定义为C long类型的长度,也就是系统的字长。不透明类型是那些通过typeder声明的类型。另外就是,我们常常需要在程序中使用长度明确的类型,内核在asm/types.h中定义了这些长度明确的类型,而该文件又被包含在文件linux/types.h中,如下表所示:
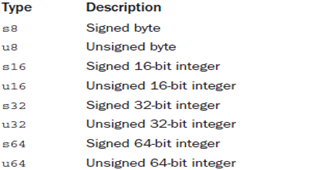
其中带符号的变量用的比较少。接下来是char型:分为有符号(-128~127)和无符号(0~255).
2.数据对齐
如果一个变量的内存地址正好是它长度的整数倍,它就被称为自然对齐的。关于字节对齐的内容还是相当繁琐的,我这里就不细讲了,后面我会有专门的专题来说这个问题。
3.字节顺序
字节顺序是指在一个字中各个字节的顺序。处理器在对字取值时既可能将最低有效位所在字节当作第一个字节(最左边的字节),也可能将其当作最后一个字节(最右边的字节)。如果最高有效位所在的字节放在最高字节位置上,其他字节依次放在低字节位置上,那么该字节顺序称作高位优先(big-endian)[存放左大右小],否则就叫做little-endian[左小又大].直接举个例子,如下:
00000000 00000000 00000100 00000011
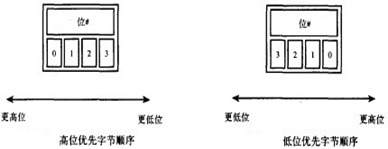
下面是上述数据在两种不同字节序的排列方式:
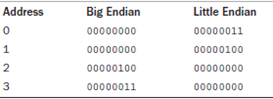
虽然不习惯,但确实是这样的,使用高位优先的体系结构把最高字节位存放在最小的内存地址上。下边的代码可以判定给定的机器字节对齐类型:
?
解析:
由于:计算机在内存中存放数据的顺序都是从低地址到高地址
大端是:高低底高 高字节在底地址,低字节在高地址
小端是:高高低低 高字节在高地址,低字节在低地址
*(char *)&x
先将x的地址(int类型)转换为char *
再取这个(char *)地址里的内容*(char *)&x,判断里面的值是否等于1.
操作对象是 整型数地址 &x
eg: 如果x的地址为 2000 2001 2002 2003 这四个单元
则 *(char *)&x 相当于地址 2000里面的内容.
x的第一字节是不是0000 0001
在linux内核支持的每一种体系结构,相应的内核都会根据机器使用的字节顺序在它的asm/byteorder.h中定义__BIG_ENDIAN或__LITTILE_ENDIAN中的一个。,这个头文件还从include/linux/byteord
er中包含了一组宏命令完成字节顺序之间的相互转换,最常用的宏命令如下:
?
4.时间
关于内核的时间问题,绝对不要假定时钟中断发生的频率,也就是每秒产生的jiffies数目。相反,应该使用HZ来正确计量时间。
5.页长度
当处理用页管理的内存时,绝对不要假设页的长度。不同的体系结构使用页的长度也是不一样的。当处理用页组织管理的内存时,通过PAGE_SIZE来使用以字节数来表示的页长度,而PAGE_SHIFT这个值定义了从最右端屏蔽多少位能够得到该地址对应的页的页号。
总之,编写可移植的代码需要考虑许多问题:字长,数据类型,对齐,字节次序,页大小,处理器排序等等。
1.字节和数据类型
能够由机器一次就完成处理的数据被称为字,字指位的数目。所以我们常听到机器是多少位的时候,就是指该机的字长。处理器通用寄存器的大小和它的字长是相同的。C语言定义的long类型总对等于机器字长。对于支持的每一种体系结构,Linux都要将<asm/types.h>中的BITS_PER_LONG定义为C long类型的长度,也就是系统的字长。不透明类型是那些通过typeder声明的类型。另外就是,我们常常需要在程序中使用长度明确的类型,内核在asm/types.h中定义了这些长度明确的类型,而该文件又被包含在文件linux/types.h中,如下表所示:
其中带符号的变量用的比较少。接下来是char型:分为有符号(-128~127)和无符号(0~255).
2.数据对齐
如果一个变量的内存地址正好是它长度的整数倍,它就被称为自然对齐的。关于字节对齐的内容还是相当繁琐的,我这里就不细讲了,后面我会有专门的专题来说这个问题。
3.字节顺序
字节顺序是指在一个字中各个字节的顺序。处理器在对字取值时既可能将最低有效位所在字节当作第一个字节(最左边的字节),也可能将其当作最后一个字节(最右边的字节)。如果最高有效位所在的字节放在最高字节位置上,其他字节依次放在低字节位置上,那么该字节顺序称作高位优先(big-endian)[存放左大右小],否则就叫做little-endian[左小又大].直接举个例子,如下:
00000000 00000000 00000100 00000011
下面是上述数据在两种不同字节序的排列方式:
虽然不习惯,但确实是这样的,使用高位优先的体系结构把最高字节位存放在最小的内存地址上。下边的代码可以判定给定的机器字节对齐类型:
?
由于:计算机在内存中存放数据的顺序都是从低地址到高地址
大端是:高低底高 高字节在底地址,低字节在高地址
小端是:高高低低 高字节在高地址,低字节在低地址
*(char *)&x
先将x的地址(int类型)转换为char *
再取这个(char *)地址里的内容*(char *)&x,判断里面的值是否等于1.
操作对象是 整型数地址 &x
eg: 如果x的地址为 2000 2001 2002 2003 这四个单元
则 *(char *)&x 相当于地址 2000里面的内容.
x的第一字节是不是0000 0001
在linux内核支持的每一种体系结构,相应的内核都会根据机器使用的字节顺序在它的asm/byteorder.h中定义__BIG_ENDIAN或__LITTILE_ENDIAN中的一个。,这个头文件还从include/linux/byteord
er中包含了一组宏命令完成字节顺序之间的相互转换,最常用的宏命令如下:
?
关于内核的时间问题,绝对不要假定时钟中断发生的频率,也就是每秒产生的jiffies数目。相反,应该使用HZ来正确计量时间。
5.页长度
当处理用页管理的内存时,绝对不要假设页的长度。不同的体系结构使用页的长度也是不一样的。当处理用页组织管理的内存时,通过PAGE_SIZE来使用以字节数来表示的页长度,而PAGE_SHIFT这个值定义了从最右端屏蔽多少位能够得到该地址对应的页的页号。
总之,编写可移植的代码需要考虑许多问题:字长,数据类型,对齐,字节次序,页大小,处理器排序等等。

相关文章推荐
- linux内核分析笔记----内核可移植性
- linux内核分析笔记----内核可移植性
- Linux内核分析笔记 与Linux内核开发理论
- linux内核分析学习笔记:用gdb跟踪linux内核启动过程
- Linux内核分析第六周学习笔记——分析Linux内核创建一个新进程的过程
- linux内核分析笔记----内核同步
- Linux内核分析——第七周学习笔记20135308
- Linux内核分析,通过mykernel实验分析内核如何工作--第二周
- 卷一 内核源代码分析 第一章 linux内核对cortex A9多核处理器的支持 1.2 Percpu内存管理 图书试读版-请勿转载
- Linux内核分析第三周学习博客——跟踪分析Linux内核的启动过程
- 自己写bootloader笔记6---boot.c分析(u-boot向内核传递参数及跳转到内核)
- Linux内核分析:跟踪分析Linux内核的启动过程
- Linux内核分析 笔记四 系统调用的三个层次 ——by王玥
- linux内核移植-内核调试工具KGBD、DDD、GDB移植笔记
- Linux内核源码分析--内核启动之(3)Image内核启动(C语言部分)(Linux-3.0 ARMv7) 【转】
- 《linux 内核完全剖析》 signal.c 代码分析笔记
- 内核笔记2-Linux内核进程控制
- Linux内核源码分析--内核启动命令行的传递过程(Linux-3.0 ARMv7)
- Linux内核笔记 - 内核编译错误及解决方法记录
- linux内核分析笔记----上半部与下半部(上)