编辑距离、拼写检查与度量空间:一个有趣的数据结构(转)
2013-07-18 15:07
357 查看
本文转自http://www.matrix67.com/blog/archives/333,纯粹个人作知识备份之用
除了字符串匹配、查找回文串、查找重复子串等经典问题以外,日常生活中我们还会遇到其它一些怪异的字符串问题。比如,有时我们需要知道给定的两个字符串“有多像”,换句话说两个字符串的相似度是多少。1965年,俄国科学家Vladimir Levenshtein给字符串相似度做出了一个明确的定义叫做Levenshtein距离,我们通常叫它“编辑距离”。字符串A到B的编辑距离是指,只用插入、删除和替换三种操作,最少需要多少步可以把A变成B。例如,从FAME到GATE需要两步(两次替换),从GAME到ACM则需要三步(删除G和E再添加C)。Levenshtein给出了编辑距离的一般求法,就是大家都非常熟悉的经典动态规划问题。
在自然语言处理中,这个概念非常重要,例如我们可以根据这个定义开发出一套半自动的校对系统:查找出一篇文章里所有不在字典里的单词,然后对于每个单词,列出字典里与它的Levenshtein距离小于某个数n的单词,让用户选择正确的那一个。n通常取到2或者3,或者更好地,取该单词长度的1/4等等。这个想法倒不错,但算法的效率成了新的难题:查字典好办,建一个Trie树即可;但怎样才能快速在字典里找出最相近的单词呢?这个问题难就难在,Levenshtein的定义可以是单词任意位置上的操作,似乎不遍历字典是不可能完成的。现在很多软件都有拼写检查的功能,提出更正建议的速度是很快的。它们到底是怎么做的呢?1973年,Burkhard和Keller提出的BK树有效地解决了这个问题。这个数据结构强就强在,它初步解决了一个看似不可能的问题,而其原理非常简单。
首先,我们观察Levenshtein距离的性质。令d(x,y)表示字符串x到y的Levenshtein距离,那么显然:
1. d(x,y) = 0 当且仅当 x=y (Levenshtein距离为0 <==> 字符串相等)
2. d(x,y) = d(y,x) (从x变到y的最少步数就是从y变到x的最少步数)
3. d(x,y) + d(y,z) >= d(x,z) (从x变到z所需的步数不会超过x先变成y再变成z的步数)
最后这一个性质叫做三角形不等式。就好像一个三角形一样,两边之和必然大于第三边。给某个集合内的元素定义一个二元的“距离函数”,如果这个距离函数同时满足上面说的三个性质,我们就称它为“度量空间”。我们的三维空间就是一个典型的度量空间,它的距离函数就是点对的直线距离。度量空间还有很多,比如Manhattan距离,图论中的最短路,当然还有这里提到的Levenshtein距离。就好像并查集对所有等价关系都适用一样,BK树可以用于任何一个度量空间。
建树的过程有些类似于Trie。首先我们随便找一个单词作为根(比如GAME)。以后插入一个单词时首先计算单词与根的Levenshtein距离:如果这个距离值是该节点处头一次出现,建立一个新的儿子节点;否则沿着对应的边递归下去。例如,我们插入单词FAME,它与GAME的距离为1,于是新建一个儿子,连一条标号为1的边;下一次插入GAIN,算得它与GAME的距离为2,于是放在编号为2的边下。再下次我们插入GATE,它与GAME距离为1,于是沿着那条编号为1的边下去,递归地插入到FAME所在子树;GATE与FAME的距离为2,于是把GATE放在FAME节点下,边的编号为2。
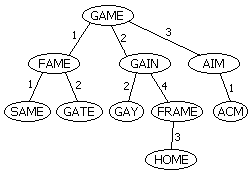
查询操作异常方便。如果我们需要返回与错误单词距离不超过n的单词,这个错误单词与树根所对应的单词距离为d,那么接下来我们只需要递归地考虑编号在d-n到d+n范围内的边所连接的子树。由于n通常很小,因此每次与某个节点进行比较时都可以排除很多子树。
举个例子,假如我们输入一个GAIE,程序发现它不在字典中。现在,我们想返回字典中所有与GAIE距离为1的单词。我们首先将GAIE与树根进行比较,得到的距离d=1。由于Levenshtein距离满足三角形不等式,因此现在所有离GAME距离超过2的单词全部可以排除了。比如,以AIM为根的子树到GAME的距离都是3,而GAME和GAIE之间的距离是1,那么AIM及其子树到GAIE的距离至少都是2。于是,现在程序只需要沿着标号范围在1-1到1+1里的边继续走下去。我们继续计算GAIE和FAME的距离,发现它为2,于是继续沿标号在1和3之间的边前进。遍历结束后回到GAME的第二个节点,发现GAIE和GAIN距离为1,输出GAIN并继续沿编号为1或2的边递归下去(那条编号为4的边连接的子树又被排除掉了)……
实践表明,一次查询所遍历的节点不会超过所有节点的5%到8%,两次查询则一般不会17-25%,效率远远超过暴力枚举。适当进行缓存,减小Levenshtein距离常数n可以使算法效率更高。
除了字符串匹配、查找回文串、查找重复子串等经典问题以外,日常生活中我们还会遇到其它一些怪异的字符串问题。比如,有时我们需要知道给定的两个字符串“有多像”,换句话说两个字符串的相似度是多少。1965年,俄国科学家Vladimir Levenshtein给字符串相似度做出了一个明确的定义叫做Levenshtein距离,我们通常叫它“编辑距离”。字符串A到B的编辑距离是指,只用插入、删除和替换三种操作,最少需要多少步可以把A变成B。例如,从FAME到GATE需要两步(两次替换),从GAME到ACM则需要三步(删除G和E再添加C)。Levenshtein给出了编辑距离的一般求法,就是大家都非常熟悉的经典动态规划问题。
在自然语言处理中,这个概念非常重要,例如我们可以根据这个定义开发出一套半自动的校对系统:查找出一篇文章里所有不在字典里的单词,然后对于每个单词,列出字典里与它的Levenshtein距离小于某个数n的单词,让用户选择正确的那一个。n通常取到2或者3,或者更好地,取该单词长度的1/4等等。这个想法倒不错,但算法的效率成了新的难题:查字典好办,建一个Trie树即可;但怎样才能快速在字典里找出最相近的单词呢?这个问题难就难在,Levenshtein的定义可以是单词任意位置上的操作,似乎不遍历字典是不可能完成的。现在很多软件都有拼写检查的功能,提出更正建议的速度是很快的。它们到底是怎么做的呢?1973年,Burkhard和Keller提出的BK树有效地解决了这个问题。这个数据结构强就强在,它初步解决了一个看似不可能的问题,而其原理非常简单。
首先,我们观察Levenshtein距离的性质。令d(x,y)表示字符串x到y的Levenshtein距离,那么显然:
1. d(x,y) = 0 当且仅当 x=y (Levenshtein距离为0 <==> 字符串相等)
2. d(x,y) = d(y,x) (从x变到y的最少步数就是从y变到x的最少步数)
3. d(x,y) + d(y,z) >= d(x,z) (从x变到z所需的步数不会超过x先变成y再变成z的步数)
最后这一个性质叫做三角形不等式。就好像一个三角形一样,两边之和必然大于第三边。给某个集合内的元素定义一个二元的“距离函数”,如果这个距离函数同时满足上面说的三个性质,我们就称它为“度量空间”。我们的三维空间就是一个典型的度量空间,它的距离函数就是点对的直线距离。度量空间还有很多,比如Manhattan距离,图论中的最短路,当然还有这里提到的Levenshtein距离。就好像并查集对所有等价关系都适用一样,BK树可以用于任何一个度量空间。
建树的过程有些类似于Trie。首先我们随便找一个单词作为根(比如GAME)。以后插入一个单词时首先计算单词与根的Levenshtein距离:如果这个距离值是该节点处头一次出现,建立一个新的儿子节点;否则沿着对应的边递归下去。例如,我们插入单词FAME,它与GAME的距离为1,于是新建一个儿子,连一条标号为1的边;下一次插入GAIN,算得它与GAME的距离为2,于是放在编号为2的边下。再下次我们插入GATE,它与GAME距离为1,于是沿着那条编号为1的边下去,递归地插入到FAME所在子树;GATE与FAME的距离为2,于是把GATE放在FAME节点下,边的编号为2。
查询操作异常方便。如果我们需要返回与错误单词距离不超过n的单词,这个错误单词与树根所对应的单词距离为d,那么接下来我们只需要递归地考虑编号在d-n到d+n范围内的边所连接的子树。由于n通常很小,因此每次与某个节点进行比较时都可以排除很多子树。
举个例子,假如我们输入一个GAIE,程序发现它不在字典中。现在,我们想返回字典中所有与GAIE距离为1的单词。我们首先将GAIE与树根进行比较,得到的距离d=1。由于Levenshtein距离满足三角形不等式,因此现在所有离GAME距离超过2的单词全部可以排除了。比如,以AIM为根的子树到GAME的距离都是3,而GAME和GAIE之间的距离是1,那么AIM及其子树到GAIE的距离至少都是2。于是,现在程序只需要沿着标号范围在1-1到1+1里的边继续走下去。我们继续计算GAIE和FAME的距离,发现它为2,于是继续沿标号在1和3之间的边前进。遍历结束后回到GAME的第二个节点,发现GAIE和GAIN距离为1,输出GAIN并继续沿编号为1或2的边递归下去(那条编号为4的边连接的子树又被排除掉了)……
实践表明,一次查询所遍历的节点不会超过所有节点的5%到8%,两次查询则一般不会17-25%,效率远远超过暴力枚举。适当进行缓存,减小Levenshtein距离常数n可以使算法效率更高。

相关文章推荐
- 编辑距离、拼写检查与度量空间:一个有趣的数据结构BK Tree
- 编辑距离、拼写检查与度量空间:一个有趣的数据结构
- 编辑距离、拼写检查与度量空间:一个有趣的数据结构 BK-Tree
- 编辑距离、拼写检查与度量空间:一个有趣的数据结构
- 编辑距离、拼写检查与度量空间:一个有趣的数据结构
- 编辑距离、拼写检查与度量空间:BK-Tree
- 如何写一个拼写检查器-by Peter Norvig
- 数据结构链表习题2.27,假设以两个元素依值递增有序排列的线性表A和B分别表示两个集合,现要求另辟空间构成一个顺序链表
- 微软等数据结构+算法面试100题(6)--写一个函数,检查字符是否是整数,如果是,返回其整数值
- 有一亿个数,输入一个数,找出与它编辑距离在3以内的数,比如输入6(0110),找出0010等数,数是32位的。
- 记录一次MVC 3.0错误 HTTP 404您正在查找的资源(或者它的一个依赖项)可能已被移除,或其名称已更改,或暂时不可用。请检查以下 URL 并确保其拼写正确。
- 51nod oj 1183 编辑距离 【求一个字符串到另一个字符串的最小操作次数【类似LCS】】
- [LeetCode] One Edit Distance 一个编辑距离
- 《数据结构》2.10设计一个算法,删除顺序表中值为item的元素,要求算法的时间复杂度是O(n),空间复杂度是O(1)
- 用python 写了一个求空间俩点之间的距离的脚本
- inc,dec,getMin,getMax均为O(1)——一个有趣的数据结构
- 错误提示之(MVC3.0):HTTP 404。您正在查找的资源(或者它的一个依赖项)可能已被移除,或其名称已更改,或暂时不可用。请检查以下 URL 并确保其拼写正确 MVC误设起始页
- 请实现一个算法,在不使用额外数据结构和储存空间的情况下,翻转一个给定的字符串(可以使用单个过程变量)
- 无法找到资源。 说明: HTTP 404。您正在查找的资源(或者它的一个依赖项)可能已被移除,或其名称已更改,或暂时不可用。请检查以下 URL 并确保其拼写正确。
- 怎样写一个拼写检查器 Peter Norvig 翻译: Eric You XU