B树
2013-06-18 13:56
176 查看
用阶定义的B树
B树又叫平衡多路查找树。一棵m阶的B树的特性如下:树中每个结点最多含有m个孩子(m >= 2)
除根结点和叶子结点外,其它每个结点至少有ceil(m / 2)个孩子(ps:ceil(x)取x的上整数)
若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根节点为叶子结点,整棵树只有一个根结点)
所有叶子都出现在同一层
每个非终端结点中包含有n个关键字信息:(n, p0, k1, p1, k2, p2, ..., kn, pn).其中 (1)n为该结点的关键字的总个数,满足ceil(m/2) - 1 <= n <= m -1 (2)ki(i = 1, .., n)为关键字,且关键字按升序排序 (3)pi为指向子树根的结点,且指针p(i-1)指向子树中所有结点的关键字均小于ki,但都大于k(i-1)
用度定义的B树
一棵B树T是具有如下性质的有根树(根为root[T]):1)每个结点x有以下域:
n[x],当前存储在结点x中的关键字数
n[x]个关键字本身,以非降序存放,因此key1[x] <= key2[x] <= ... <= key(n[x])[x]
leaf[x],是一个布尔值,如果x是叶子的话,则它为TRUE,如果x为一个内结点,则为FALSE
2)每个内结点x还包含n[x] + 1个指向其子女的指针c1[x],c2[x],...,c(n[x] + 1)[x].叶子结点没有子女,故它们的ci域无定义
3)如果ki为存储在以ci[x]为根的子树中的关键字,则k1 <= key1[x] <= k2 <= key2[x] <= ... <= key(n[x])[x] <= k(n[x] + 1)
4)每个叶子结点具有相同的深度,即树的高度h
5)每一个结点能包含的关键字数有一个上界和下界。这些界可用一个称作B树的最小度数的固定整数t >= 2来表示
每个非根的结点必须至少有t - 1个关键字。每个非根的内结点至少有t个子女。如果树是非空的,则根结点至少包含一个关键字
每个结点可包含至多2t-1个关键字。所以一个内结点至多可有2t个子女。我们说一个结点是满的,如果它恰好有2t - 1个关键字
B树的高度
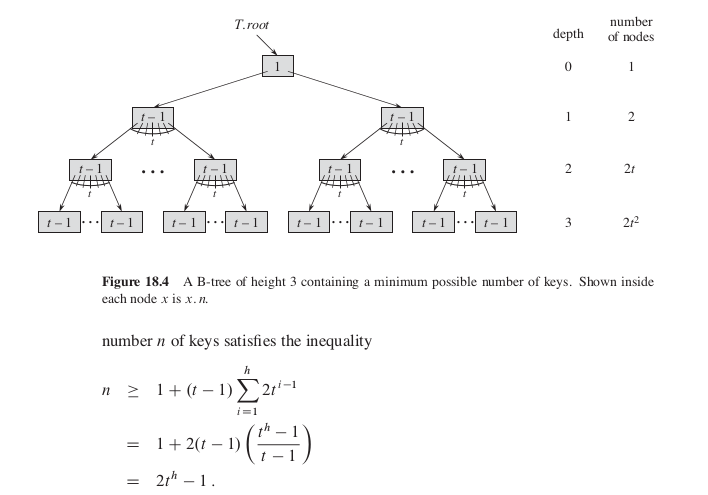
B树上的大部分操作所需的磁盘存取次数与B树的高度成正比。下面来分析B树的最坏高度情况:定理18.1 如果n >= 1, 则对任意一棵包含n个关键字、高度h、最小度数t >= 2的B树T,有:

证明:如果一棵B树的高度为h,其根结点包含至少一个关键字而其他结点包含至少t - 1个关键字。这样,在深度1至少有两个结点,在深度2至少有2t个结点,在深度3至少有2t2个结点,等等。因此,关键字的个数n满足不等式:
与红黑树相比,这里我们看道了B树的能力。虽然二者的高度都是以O(lgn)的速度增长(t是个常数),对B树来说对数的底要打很多倍。对于大多数的树操作来说,要查找的结点数在B树中要比在红黑树中少大约lgt的因子。因为在树中查找任意一个结点通常都需要一次磁盘存取,所以磁盘存取的次数大大地减少了
B树的ADT
[cpp] viewplaincopy
#define m 1024 /*B树的阶(代表每个结点至多有m棵子树)*/
// B树ADT
struct btnode
{
int keynum; /*结点中关键字个数, keynum < m*/
struct btnode *parent; /*指向父结点*/
struct btnode *ptr; /*子树指针向量:ptr[0]...ptr[keynum]*/
int *key; /*关键字向量:key[1]...key[keynum]*/
int *offset; /*key在硬盘中的存储位置:offset[1]...offset[keynum]*/
};
B树的基本操作
下面要给出B-TREE-SEARCH,B-TREE-CREATE和B-TREE-INSERT的操作,在这些过程中,采用两个约定:B树的根结点始终在主存中,因而无需对根做DISK-READ;但是,每当根结点被改变后,都需要对根结点做一次DISK-WRITE
任何被当作参数的结点被传递之前,要先对它们做一次DISK-READ
搜索B树
搜索B树与搜索二叉查找树类似,只是在每个结点 所做的不是个二叉或者“两路”分支决定,而是根据该结点的子女数所做的多路分支决定。更准确的说,在每个内结点x处,要做(n[x] + 1)路的分支决定。[cpp] view
plaincopy
/**
* 从树根指针为root的B树上查找关键字k对应记录的存储位置
*/
int btree_search(struct btnode *root, int k)
{
int i; // 待比较的关键字序号
struct btnode *p = root;
while (p != NULL) {
i = 1;
while (i < p->keynum && k > p->key[i]) {
i ++;
}
if (k == p->key[i]) {
return p->offset[i];
} else {
p = p->ptr[i - 1];
}
}
return -1; // 查找失败返回-1
}
如下图所示,即是一棵B树,一棵关键字为英语中辅音字母的B树,现在要从树中查找字母R(包含n[x]个关键字的内结点x,x有n[x] + 1个子女(也就是说,一个内结点x若含有n[x]个关键字,那么x将含有n[x] + 1个子女)。所有的叶子结点都处于相同的深度,颜色稍浅的结点为查找字母R时需要检查的结点):
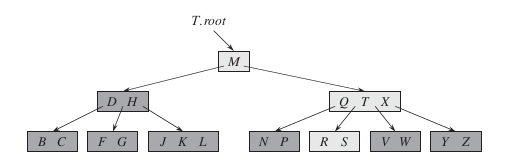
下面,我们来模拟一下查找R的过程:
根据根结点找到根磁盘块1,将其中的信息导入到内存 [磁盘IO操作1次]
此时内存中有一个辅音字母M和两个存储其他磁盘页面地址的数据。根据算法我们发现,R > M,因此我们找到了第二个指针,里面的key包含了Q、T、X
根据第二个指针,我们定位到包含QTX的磁盘块,并将其信息导入到内存 [磁盘IO操作2次(累加计数)]
此时内存中有三个辅音字母Q、T、X和其他四个存储其他磁盘页面地址的数据。根据算法我们发现:Q < R < T,因此我们找到包含第二个指针
根据第二个指针,我们定位到包含R、S的磁盘块,并将其中的信息导入到内存 [磁盘IO操作3次]
此时内存中包含了R、S,根据算法我们查到了该内存块,并返回R的磁盘地址
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作则是影响整个B树查找效率的决定因素。
创建一棵空的B树
为了构造一个B树T,先用init_btree来创建一个空的根结点,再调用insert_btree来加入新的关键字[cpp] view
plaincopy
/**
* 初始化B树,树根指针置空
*/
inline void init_btree(struct btnode *root)
{
root = NULL;
}
向B树插入关键字
B树插入是指到一个已知的叶结点上,因为不能把关键字插到一个满的叶结点上,故引入一个操作,将一个满的结点y(有2t-1个关键字)按其中间关键字key[y]分裂成两个各含t-1个关键字的结点,中间关键字提升到y的双亲结点,如果y的双亲也是满的,则自底向上传播分裂如同二叉查找树,插入时,需要从根部沿着树下降到叶子,当沿着树往下查找新关键字所属位置时,就分裂遇到的每一个满结点,这样就能保证,要分裂一个满结点y时,就能确保它的双亲不是满的
B树中的结点分裂
满结点y按其中间关键字S进行分裂,S则被提升到y的双亲结点x中。y中大于中间关键字的那些关键字都置于新结点z中,它成为x的一个新孩子。
在B树中插入关键码key的思路
对高度为h的m阶树,新节点一般是插在第h层。通过检索可以确定关键码应插入的结点位置。然后分两种情况讨论:若该结点中关键码个数小于m-1,则直接插入即可
若该结点中关键码个数等于m-1,则将引起结点的分裂。以中间关键码为界将结点一分为二,产生一个新结点,并把关键中间码插入到父结点(h-1)层中
重复上述工作,最坏情况一直分裂到根结点,建立一个新的根结点,整个B树增加一层

相关文章推荐