基于用户行为的推荐系统
2013-06-09 12:43
459 查看
最近在做一个广告推荐系统,要求是根据用户的访问记录对用户进行分组并按组推送广告。其实很多网上商城都有这功能,诸如淘宝京东这些。要实现其实并不算多复杂,主要有一个几个步骤,首先是提取特征,然后是聚类,最后是分类。
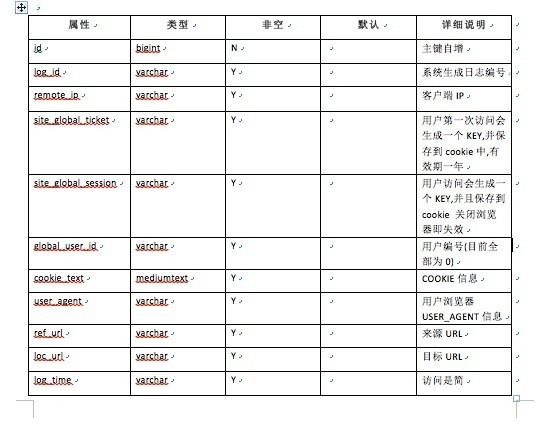
样本数据如下,这里只列出三条数据:
1,"20130424000001ceaf2aa2","121.205.153.254","a486f2d7-d480-4d0c-8b7d-17df77072e8b","83B5BBEF83E120F91563E2700F28147E","0","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727)","http://www.it168.com/","http://www.ehaier.com/subject/leader201304.html?utm_source=IT168&utm_content=ShouYe&utm_medium=TongLanErQu&utm_campaign=7565516&smt_b=C0B0A09080706059E46F00C","2013-04-24 00:00:01"
2,"20130424000001ae40bf83","114.218.90.77","792b2d50-8f0d-4273-aefd-dca08879d842","6B752535B086612B93CC08B84FE5E209","0","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)","http://www.it168.com/","http://www.ehaier.com/subject/leader201304.html?utm_source=IT168&utm_content=ShouYe&utm_medium=TongLanErQu&utm_campaign=7565516&smt_b=C0B0A09080706059E46F00C","2013-04-24 00:00:01"
3,"20130424000001a81c1ef3","60.162.151.117","64be2f61-a111-4378-8f13-e65ceb07303a","9C583F3DD38E3F49C6F09F35404D7008","0","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 534; QQDownload 661; .NET CLR 2.0.50727)","http://www.it168.com/","http://www.ehaier.com/subject/leader201304.html?utm_source=IT168&utm_content=ShouYe&utm_medium=TongLanErQu&utm_campaign=7565516&smt_b=C0B0A09080706059E46F00C","2013-04-24 00:00:01"
现在要从这种数据里面提取出用户特征,是不是需要费一番脑筋?其实这些数据中我们只需要两个字段的数据即可,一个是用户标识,一个是用户浏览的目标url。当然,这只是简单做法,利用其他字段信息说不定会有更好的效果。
总之,用户标识我们可以选择第4个字段,user_global_ticket,url就是loc_url了。但是这里显然也不能直接把url作为每个用户的特征,有些url例如访问主页的根本没有体现出用户的爱好,我们需要找到那些访问产品的url,例如查看某类手机的url就能表明该用户说不定是个数码控,所以对url进行过滤,找出仅包含product信息的url。
找到这些url之后,我们发现如果把某个商品作为特征要统计的实在是太多了,再说我们也并不需要精确到某个商品,只需要确定是那种商品即可。于是我们根据url product后面跟的标识商品的数字去数据库中查找该商品属于哪个类别,把类别作为用户的标识。
例如针对http://www.ehaier.com/product/1871.html 去数据库中查找1871商品对应的类别,查出来是2347类(数码类),就把2347作为该用户的一个特征。这可以用正则表达式外加数据库查询实现。提取类别信息后的数据如下:
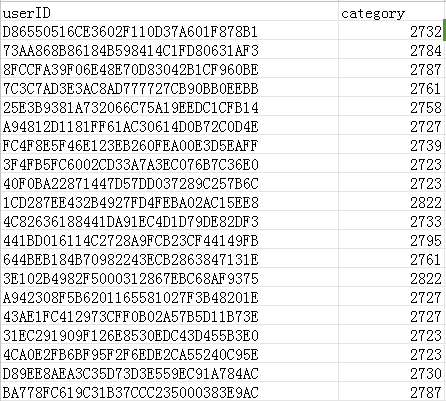
得到类别信息后对类别总数进行统计,得到一个用户类别矩阵,其中一行代表一个用户,一列代表一个类别信息,每一个位置就是用户访问该类别网址的次数,为了规格化数据,对数据进行归一化是必要的,这里采用的是余弦归一化方法,得到的数据如下。

可以矩阵中很多位置都是0,这是因为某个用户完全没有访问过该类的任何产品导致的。经过这样处理以后,特征我们就提取出来了。
package cn.pezy.lightning.clustering;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import weka.clusterers.SimpleKMeans;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Remove;
// k-means cluster
public class UserBehaviourClusterKmeans {
private Instances instances;
private String sourceFile;
private String targetFile;
private int kNumber;
private int[] assignment;
public UserBehaviourClusterKmeans(String sourceFile, String targetFile,int kNumber) {
this.sourceFile = sourceFile;
this.targetFile = targetFile;
this.kNumber = kNumber;
}
public void loadData() throws Exception {
DataSource dataSource = new DataSource(sourceFile);
instances = dataSource.getDataSet();
}
public void preprocess() throws Exception {
Remove remove = new Remove();
remove.setAttributeIndices("1");
remove.setInputFormat(instances);
instances = Filter.useFilter(instances, remove);
}
public void cluster() throws Exception {
SimpleKMeans kmeans = new SimpleKMeans();
kmeans.setPreserveInstancesOrder(true);
kmeans.setNumClusters(kNumber);
kmeans.buildClusterer(instances);
assignment = kmeans.getAssignments();
}
public void writeResult() throws Exception {
FileReader fr = null;
BufferedReader br = null;
FileWriter fw = null;
BufferedWriter bw = null;
String line = null;
int j = 0;
try {
fr = new FileReader(sourceFile);
br = new BufferedReader(fr);
fw = new FileWriter(targetFile);
bw = new BufferedWriter(fw);
line = br.readLine();
bw.write(line + ",clusterID\n");
while ((line = br.readLine()) != null) {
bw.write(line + "," + assignment[j++] + "\n");
}
} finally {
if (br != null) {
br.close();
}
if (bw != null) {
bw.close();
}
}
}
public void process() throws Exception {
loadData();
preprocess();
cluster();
writeResult();
}
}
聚类结束以后,打开生成文件,我们就能看到用户已经被划分了。一般来说聚类耗时比较长,实时性较差,应该定期进行聚类。
package cn.pezy.lightning.clustering;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import weka.classifiers.Classifier;
import weka.classifiers.bayes.NaiveBayes;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.NumericToNominal;
import weka.filters.unsupervised.attribute.Remove;
// train model
public class UserBehaviourTrain {
private Instances instances;
private String sourceFile;
private String targetModelFile;
private Classifier classifier;
public UserBehaviourTrain(String sourceFile, String targetModelFile) {
this.sourceFile = sourceFile;
this.targetModelFile = targetModelFile;
}
public void loadData() throws Exception {
DataSource source = new DataSource(sourceFile);
instances = source.getDataSet();
}
public void preprocess() throws Exception {
Remove remove = new Remove();
remove.setAttributeIndices("1");
remove.setInputFormat(instances);
instances = Filter.useFilter(instances, remove);
NumericToNominal ntn = new NumericToNominal();
ntn.setAttributeIndices("last");
ntn.setInputFormat(instances);
instances = Filter.useFilter(instances, ntn);
instances.setClassIndex(instances.numAttributes() - 1);
}
public void train() throws Exception {
classifier = new NaiveBayes();
classifier.buildClassifier(instances);
}
public void writeModel() throws FileNotFoundException, IOException {
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream(targetModelFile));
oos.writeObject(classifier);
oos.flush();
} finally {
if (oos != null) oos.close();
}
}
public void process() throws Exception {
loadData();
preprocess();
train();
writeModel();
}
}
有了这个模型以后,针对新用户,还是先根据访问记录提取特征,变成用户类别矩阵中的一行数据,然后用weka提供的分类函数进行分类,代码如下:
package cn.pezy.lightning.clustering;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import weka.classifiers.Classifier;
import weka.core.DenseInstance;
import weka.core.Instance;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.NumericToNominal;
import weka.filters.unsupervised.attribute.Remove;
// classifier new coming data
public class UserBehaviourClassifier {
private Classifier classifier;
private String modelFile;
private String trainFile;
private String templateFile;
private Instances template;
private String categoryFile;
public static ArrayList<String> category = new ArrayList<String>();
public UserBehaviourClassifier(String modelFile, String trainFile, String templateFile,
String categoryFile) throws Exception {
this.modelFile = modelFile;
this.trainFile = trainFile;
this.templateFile = templateFile;
this.categoryFile = categoryFile;
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(modelFile));
classifier = (Classifier) ois.readObject();
ois.close();
initial();
}
public void getTemplateFile() throws IOException {
FileReader fr = null;
BufferedReader br = null;
FileWriter fw = null;
BufferedWriter bw = null;
String line = null;
int count = 0;
try {
fr = new FileReader(trainFile);
br = new BufferedReader(fr);
fw = new FileWriter(templateFile);
bw = new BufferedWriter(fw);
while ((line = br.readLine()) != null) {
bw.write(line + "\n");
if (count++ > 2) break;
}
} finally {
if (br != null) {
br.close();
}
if (bw != null) {
bw.close();
}
}
}
public void initial() throws Exception {
getTemplateFile();
DataSource source = new DataSource(templateFile);
template = source.getDataSet();
Remove remove = new Remove();
remove.setAttributeIndices("1");
remove.setInputFormat(template);
template = Filter.useFilter(template, remove);
NumericToNominal ntn = new NumericToNominal();
ntn.setAttributeIndices("last");
ntn.setInputFormat(template);
template = Filter.useFilter(template, ntn);
template.setClassIndex(template.numAttributes() - 1);
// get category
readCategory(categoryFile);
}
public int classify(Map<String, Integer> urlMap) throws Exception {
// value only attribute
ArrayList<Double> value = new ArrayList<Double>();
value = Preprocess(urlMap);
Instance instance = new DenseInstance(value.size());
for (int i = 0; i < value.size(); i++) {
instance.setValue(i, value.get(i));
}
instance.setDataset(template);
return (int) classifier.classifyInstance(instance);
}
public void readCategory(String file) throws IOException {
FileReader fr = new FileReader(file);
BufferedReader br = new BufferedReader(fr);
for (String s : br.readLine().split(",")) {
category.add(s);
}
br.close();
fr.close();
}
public static ArrayList<Double> Preprocess(Map<String, Integer> urlMap) {
ArrayList<Double> result = new ArrayList<Double>();
for (String s : category) {
if (urlMap.get(s) == null) {
result.add(0.0);
} else {
result.add((double) urlMap.get(s));
}
}
ArrayList<Double> answer = cosin(result);
return answer;
}
public static ArrayList<Double> cosin(ArrayList<Double> data) {
double sum = 0;
for (Double d : data) {
sum += d * d;
}
sum = Math.sqrt(sum);
ArrayList<Double> answer = new ArrayList<Double>();
for (Double d : data) {
answer.add(d / sum);
}
return answer;
}
public static void main(String[] args) throws Exception {
String filePath = "./";
UserBehaviourClassifier classifier =
new UserBehaviourClassifier(filePath + "trainResult.model", filePath + "Kmeans.csv",
filePath + "template.csv", filePath + "category.csv");
// new coming data
Map<String, Integer> urlmap = new HashMap<String, Integer>();
// just for test,put data here
urlmap.put("5398", 1);
long startTime = System.currentTimeMillis();
classifier.classify(urlmap);
long stopTime = System.currentTimeMillis();
System.out.println(classifier.classify(urlmap));
System.out.println("cost time= " + (stopTime - startTime));
}
}
通过上面几步操作,我们就能够在基于原有数据的情况下,对新用户进行广告推荐了,当然,划分成不同类别的用户需要去判断该推荐哪种广告,这个应该是电商关心的事情,我们码农是做不到这一点的。
1、特征提取
先来说说特征提取,这应该是最重要的一步,很多人虽然知道一大堆算法可以用,但是具体应用时发现给你的数据完全不是一眼就能看出特征的。这里的提供的数据是用户的访问日志,格式如下:样本数据如下,这里只列出三条数据:
1,"20130424000001ceaf2aa2","121.205.153.254","a486f2d7-d480-4d0c-8b7d-17df77072e8b","83B5BBEF83E120F91563E2700F28147E","0","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727)","http://www.it168.com/","http://www.ehaier.com/subject/leader201304.html?utm_source=IT168&utm_content=ShouYe&utm_medium=TongLanErQu&utm_campaign=7565516&smt_b=C0B0A09080706059E46F00C","2013-04-24 00:00:01"
2,"20130424000001ae40bf83","114.218.90.77","792b2d50-8f0d-4273-aefd-dca08879d842","6B752535B086612B93CC08B84FE5E209","0","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)","http://www.it168.com/","http://www.ehaier.com/subject/leader201304.html?utm_source=IT168&utm_content=ShouYe&utm_medium=TongLanErQu&utm_campaign=7565516&smt_b=C0B0A09080706059E46F00C","2013-04-24 00:00:01"
3,"20130424000001a81c1ef3","60.162.151.117","64be2f61-a111-4378-8f13-e65ceb07303a","9C583F3DD38E3F49C6F09F35404D7008","0","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 534; QQDownload 661; .NET CLR 2.0.50727)","http://www.it168.com/","http://www.ehaier.com/subject/leader201304.html?utm_source=IT168&utm_content=ShouYe&utm_medium=TongLanErQu&utm_campaign=7565516&smt_b=C0B0A09080706059E46F00C","2013-04-24 00:00:01"
现在要从这种数据里面提取出用户特征,是不是需要费一番脑筋?其实这些数据中我们只需要两个字段的数据即可,一个是用户标识,一个是用户浏览的目标url。当然,这只是简单做法,利用其他字段信息说不定会有更好的效果。
总之,用户标识我们可以选择第4个字段,user_global_ticket,url就是loc_url了。但是这里显然也不能直接把url作为每个用户的特征,有些url例如访问主页的根本没有体现出用户的爱好,我们需要找到那些访问产品的url,例如查看某类手机的url就能表明该用户说不定是个数码控,所以对url进行过滤,找出仅包含product信息的url。
找到这些url之后,我们发现如果把某个商品作为特征要统计的实在是太多了,再说我们也并不需要精确到某个商品,只需要确定是那种商品即可。于是我们根据url product后面跟的标识商品的数字去数据库中查找该商品属于哪个类别,把类别作为用户的标识。
例如针对http://www.ehaier.com/product/1871.html 去数据库中查找1871商品对应的类别,查出来是2347类(数码类),就把2347作为该用户的一个特征。这可以用正则表达式外加数据库查询实现。提取类别信息后的数据如下:
得到类别信息后对类别总数进行统计,得到一个用户类别矩阵,其中一行代表一个用户,一列代表一个类别信息,每一个位置就是用户访问该类别网址的次数,为了规格化数据,对数据进行归一化是必要的,这里采用的是余弦归一化方法,得到的数据如下。
可以矩阵中很多位置都是0,这是因为某个用户完全没有访问过该类的任何产品导致的。经过这样处理以后,特征我们就提取出来了。
2、聚类
在聚类的时候我们可以用weka提供的库(貌似只支持java),只需要提供输入输出和设定一些参数即可,很是方便,下面是对数据进行kmeans聚类的代码:package cn.pezy.lightning.clustering;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import weka.clusterers.SimpleKMeans;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Remove;
// k-means cluster
public class UserBehaviourClusterKmeans {
private Instances instances;
private String sourceFile;
private String targetFile;
private int kNumber;
private int[] assignment;
public UserBehaviourClusterKmeans(String sourceFile, String targetFile,int kNumber) {
this.sourceFile = sourceFile;
this.targetFile = targetFile;
this.kNumber = kNumber;
}
public void loadData() throws Exception {
DataSource dataSource = new DataSource(sourceFile);
instances = dataSource.getDataSet();
}
public void preprocess() throws Exception {
Remove remove = new Remove();
remove.setAttributeIndices("1");
remove.setInputFormat(instances);
instances = Filter.useFilter(instances, remove);
}
public void cluster() throws Exception {
SimpleKMeans kmeans = new SimpleKMeans();
kmeans.setPreserveInstancesOrder(true);
kmeans.setNumClusters(kNumber);
kmeans.buildClusterer(instances);
assignment = kmeans.getAssignments();
}
public void writeResult() throws Exception {
FileReader fr = null;
BufferedReader br = null;
FileWriter fw = null;
BufferedWriter bw = null;
String line = null;
int j = 0;
try {
fr = new FileReader(sourceFile);
br = new BufferedReader(fr);
fw = new FileWriter(targetFile);
bw = new BufferedWriter(fw);
line = br.readLine();
bw.write(line + ",clusterID\n");
while ((line = br.readLine()) != null) {
bw.write(line + "," + assignment[j++] + "\n");
}
} finally {
if (br != null) {
br.close();
}
if (bw != null) {
bw.close();
}
}
}
public void process() throws Exception {
loadData();
preprocess();
cluster();
writeResult();
}
}
聚类结束以后,打开生成文件,我们就能看到用户已经被划分了。一般来说聚类耗时比较长,实时性较差,应该定期进行聚类。
3、分类
有了用户聚类结果,我们就可以针对新来用户进行分类。首先需要根据聚类结果学习得到一个模型,这里采用最简单的贝叶斯模型,训练模型代码如下:package cn.pezy.lightning.clustering;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import weka.classifiers.Classifier;
import weka.classifiers.bayes.NaiveBayes;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.NumericToNominal;
import weka.filters.unsupervised.attribute.Remove;
// train model
public class UserBehaviourTrain {
private Instances instances;
private String sourceFile;
private String targetModelFile;
private Classifier classifier;
public UserBehaviourTrain(String sourceFile, String targetModelFile) {
this.sourceFile = sourceFile;
this.targetModelFile = targetModelFile;
}
public void loadData() throws Exception {
DataSource source = new DataSource(sourceFile);
instances = source.getDataSet();
}
public void preprocess() throws Exception {
Remove remove = new Remove();
remove.setAttributeIndices("1");
remove.setInputFormat(instances);
instances = Filter.useFilter(instances, remove);
NumericToNominal ntn = new NumericToNominal();
ntn.setAttributeIndices("last");
ntn.setInputFormat(instances);
instances = Filter.useFilter(instances, ntn);
instances.setClassIndex(instances.numAttributes() - 1);
}
public void train() throws Exception {
classifier = new NaiveBayes();
classifier.buildClassifier(instances);
}
public void writeModel() throws FileNotFoundException, IOException {
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream(targetModelFile));
oos.writeObject(classifier);
oos.flush();
} finally {
if (oos != null) oos.close();
}
}
public void process() throws Exception {
loadData();
preprocess();
train();
writeModel();
}
}
有了这个模型以后,针对新用户,还是先根据访问记录提取特征,变成用户类别矩阵中的一行数据,然后用weka提供的分类函数进行分类,代码如下:
package cn.pezy.lightning.clustering;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import weka.classifiers.Classifier;
import weka.core.DenseInstance;
import weka.core.Instance;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.NumericToNominal;
import weka.filters.unsupervised.attribute.Remove;
// classifier new coming data
public class UserBehaviourClassifier {
private Classifier classifier;
private String modelFile;
private String trainFile;
private String templateFile;
private Instances template;
private String categoryFile;
public static ArrayList<String> category = new ArrayList<String>();
public UserBehaviourClassifier(String modelFile, String trainFile, String templateFile,
String categoryFile) throws Exception {
this.modelFile = modelFile;
this.trainFile = trainFile;
this.templateFile = templateFile;
this.categoryFile = categoryFile;
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(modelFile));
classifier = (Classifier) ois.readObject();
ois.close();
initial();
}
public void getTemplateFile() throws IOException {
FileReader fr = null;
BufferedReader br = null;
FileWriter fw = null;
BufferedWriter bw = null;
String line = null;
int count = 0;
try {
fr = new FileReader(trainFile);
br = new BufferedReader(fr);
fw = new FileWriter(templateFile);
bw = new BufferedWriter(fw);
while ((line = br.readLine()) != null) {
bw.write(line + "\n");
if (count++ > 2) break;
}
} finally {
if (br != null) {
br.close();
}
if (bw != null) {
bw.close();
}
}
}
public void initial() throws Exception {
getTemplateFile();
DataSource source = new DataSource(templateFile);
template = source.getDataSet();
Remove remove = new Remove();
remove.setAttributeIndices("1");
remove.setInputFormat(template);
template = Filter.useFilter(template, remove);
NumericToNominal ntn = new NumericToNominal();
ntn.setAttributeIndices("last");
ntn.setInputFormat(template);
template = Filter.useFilter(template, ntn);
template.setClassIndex(template.numAttributes() - 1);
// get category
readCategory(categoryFile);
}
public int classify(Map<String, Integer> urlMap) throws Exception {
// value only attribute
ArrayList<Double> value = new ArrayList<Double>();
value = Preprocess(urlMap);
Instance instance = new DenseInstance(value.size());
for (int i = 0; i < value.size(); i++) {
instance.setValue(i, value.get(i));
}
instance.setDataset(template);
return (int) classifier.classifyInstance(instance);
}
public void readCategory(String file) throws IOException {
FileReader fr = new FileReader(file);
BufferedReader br = new BufferedReader(fr);
for (String s : br.readLine().split(",")) {
category.add(s);
}
br.close();
fr.close();
}
public static ArrayList<Double> Preprocess(Map<String, Integer> urlMap) {
ArrayList<Double> result = new ArrayList<Double>();
for (String s : category) {
if (urlMap.get(s) == null) {
result.add(0.0);
} else {
result.add((double) urlMap.get(s));
}
}
ArrayList<Double> answer = cosin(result);
return answer;
}
public static ArrayList<Double> cosin(ArrayList<Double> data) {
double sum = 0;
for (Double d : data) {
sum += d * d;
}
sum = Math.sqrt(sum);
ArrayList<Double> answer = new ArrayList<Double>();
for (Double d : data) {
answer.add(d / sum);
}
return answer;
}
public static void main(String[] args) throws Exception {
String filePath = "./";
UserBehaviourClassifier classifier =
new UserBehaviourClassifier(filePath + "trainResult.model", filePath + "Kmeans.csv",
filePath + "template.csv", filePath + "category.csv");
// new coming data
Map<String, Integer> urlmap = new HashMap<String, Integer>();
// just for test,put data here
urlmap.put("5398", 1);
long startTime = System.currentTimeMillis();
classifier.classify(urlmap);
long stopTime = System.currentTimeMillis();
System.out.println(classifier.classify(urlmap));
System.out.println("cost time= " + (stopTime - startTime));
}
}
通过上面几步操作,我们就能够在基于原有数据的情况下,对新用户进行广告推荐了,当然,划分成不同类别的用户需要去判断该推荐哪种广告,这个应该是电商关心的事情,我们码农是做不到这一点的。

相关文章推荐
- 推荐系统(二) —— 利用用户行为数据 —— 基于领域的算法
- 一个简单的基于用户的推荐系统+缓存机制
- 推荐系统之基于用户的协调过滤
- 实战智能推荐系统(6)-- 用户行为分析
- 实战智能推荐系统(6)-- 用户行为分析
- 实战智能推荐系统(7)-- 基于用户的协同过滤算法
- 推荐系统-通过数据挖掘算法协同过滤讨论基于内容和用户的区别
- R语言实战实现基于用户的简单的推荐系统(数量较少)
- 推荐系统--基于用户的协同过滤算法
- 推荐系统实践---第二章:利用用户行为数据
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
- 推荐系统-利用用户行为数据判断用户间或商品间相似性、分类和个性化推荐
- 最近邻居推荐系统原理和基于用户的评分预测推荐
- 实战智能推荐系统(6)-- 用户行为分析
- 实战智能推荐系统(6)-- 用户行为分析
- 实战智能推荐系统(7)-- 基于用户的协同过滤算法
- 《推荐系统》基于标签的用户推荐系统
- 原创:自定义三叉树(二)--基于搜索推荐系统根据用户搜索频率(热搜)排序
- 基于近邻用户协同过滤算法的音乐推荐系统
- 实战智能推荐系统(6)-- 用户行为分析