指令流水线
2013-06-05 15:25
239 查看
最近在看反汇编与逆向的书,有关一些编译优化的知识得到了增长,查阅相关资料,摘录下来。
原出处:http://zh.wikipedia.org/wiki/%E6%8C%87%E4%BB%A4%E6%B5%81%E6%B0%B4%E7%BA%BF
指令流水线(英语:Instruction pipeline)是为了让计算机和其它数字电子设备能够加速指令的通过速度(单位时间内被运行的指令数量)而设计的技术。
流水线是假设程序运行时有一连串的指令要被运行(垂直座标i是指令集,水平座标表时间t)。绝大多数当代的CPU都是利用时钟频率驱动。
而CPU是由内部的逻辑门与触发器组成。当受到时钟频率触发时,触发器得到新的数值,并且逻辑门需要一段时间来解析出新的数值,而当受到下一个时钟频率触发时触发器又得到新的数值,以此类推。而借由逻辑门分散成很多小区块,再让触发器链接这些小区块组,使逻辑门输出正确数值的时间延迟得以减少,这样一来就可以减少指令运行所需要的周期。
举例来说,典型的RISC流水线被分解成五个阶段,每个阶段之间使用触发器链接。
读取指令
指令解码与读取暂存器
运行
存储器访问
写回暂存器

危害:当一名程序员(或者组合者/编译者)编写组合代码(或者汇编码)时,他们会假定每个指令是循序运行的。而这个假设会使流水线无效。当此现象发生后程序会表现的不正常,而此现象就是危害。不过目前有提供几种技术来解决这些危害像是转发与延迟等。
未流水线的架构产生的效率低,因为有些CPU的模块在其他模块运行时是闲置的。流水线虽并不会完全消除CPU的闲置时间,但是能够让这些模块并发运作而大幅提升程序运行的效率。
管线在处理器的内部被组织成层级,各个层级的管线能半独立地单独运作。每一个层级都被管理并且链接到一条“链“,因而每个层级的输出被送到其它层级直至任务完成。处理器的这种组织方式能使总体的处理时间显著缩短。
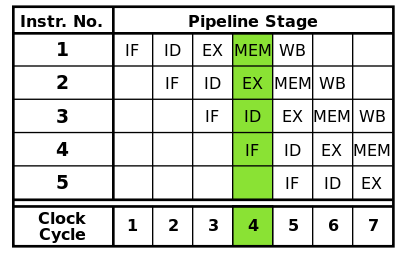
但并不是所有的指令都是独立的。在一条简单的流水线中,完成一个指令可能需要5层。(如图:RISC机器的五层流水线示意图) 要在最佳性能下运算,当第一个指令被运行时,这个流水线需要运行随后4条独立的指令。如果随后4条指令依赖于第一条指令的输出,流水线控制逻辑必须插入延迟时钟频率周期到流水线内,直到依赖被解除。而转发技术能显著减少延时。凭借多个层,虽然流水线在理论上能提高性能,优胜于无流水线的内核(假设时钟频率也因应层的数量按比例增加),但事实上,许多脚本设计中并不会考虑到理想的运行。
并非在所有情况下流水线技术都起作用。可能有一些缺点。如果一条指令流水线能够在每一个时钟频率周期(clock
cycle)接纳一条新的指令,被称为完整流水线(fully pipelined)。因流水线中的指令需要延迟处理而要等待数个时钟频率周期,被称为非完整流水线。
流水线的优点
减少了处理器执行指令所需要的时钟频率周期,在通常情况下增加了指令的输入频率(issue-rate)。
一些集成电路(combinational circuits),例如加法器(adders)或者乘法器(multipliers),通过添加更多的环路(circuitry)使其工作得更快。如果以流水线替代,能相对地减少环路。
没有流水线的优点
非流水线的处理器每次(at a time)只运行一个指令。防止分支延时(事实上,每个分支都会产生延时)和串行指令被并行运行产生的问题。设计比较简单和较低生产成本。
在运行相同的指令时,非流水线处理器的指令传输延迟时间(The
instruction latency)比流水线处理器明显较短。这是因为流水线的处理器必须在数据路径(data path)中添加额外触发器(flip-flops)。
非流水线处理器有固定指令位宽(a stable instruction bandwidth)。流水线处理器的性能更难以预测,并且不同的程序之间的变化(vary)可能更大。


一般的四层流水线架构;不同的颜色格表示不同的指令
右图是一般有4层流水线的示意图:
读取指令(Fetch)
指令解码(Decode)
运行指令(Execute)
写回运行结果(Write-back)
上方的大灰色格是一连串未运行的指令;下方的大灰色格则是已运行完成的指令;中间的大白色格则是流水线。
运行顺序如以下列表所示:
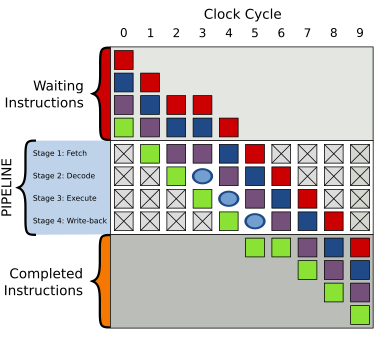
一个气泡在编号为3的时钟频率周期中,指令运行被延迟
主条目:气泡 (电脑运算)
指令运行中产生一个“打嗝”(hiccup),在流水线中生成一个没有实效的气泡。
如右图,在编号为2的时钟频率周期中,紫色指令的读取被延迟,并且在编号为3的时钟频率周期中解码层也产生了一个气泡。所有在紫色指令之后的指令都被延迟运行,而在其之前已经运行了的指令则不受影响。
由于气泡使指令运行延迟了一个时钟频率周期,完成全部4条指令的运行共需要8个时钟频率周期。
而气泡处对指令的读取、解码、运行与写回都没有实质影响。这可以使用nop代码来完成。
一个典型的加法指令可能会写成像
A 位置与 B 位置的数值相加后放到 C 位置。在流水线处理器内,流水线控制器会将这个指令分拆成一连串微指令:
R1, R2 和 R3是CPU内的暂存器(register是CPU里面能够快速访问的暂存存储器)。主存储器内标注为A位置和B位置之存储单元中的数值被加载(或称
复制)到暂存器 R1 和 R2 中,然后送到加法器中相加,结果输出到暂存器 R3 中,R3 中的数值再被存储到主存储器内标注为C位置的存储单元。
而且在非流水线的例子,开始驱动加法动作到完成的时间是不变的。
在这个示例中的流水线分为3层:加载,运行,存储。每一步被称为流水线层(或称流水线阶段)(pipeline stages)。
在非流水线处理器中,同一时间只允许一个层运作,所以必须等待指令运行完毕才能开始运行下一条指令。在流水线处理器中,所有的层能在同一时间处理不同的指令。当一条指令在运行层,另外一条指令在解码层,第三条指令在读取层。
流水线没有减少运行指令所花费的时间; 它增加了在同一时间被处理的指令数量,并且减少了完成指令之间的延迟。随着处理器中流水线层的数量增加,能在同一时间被处理的指令数量也相应增加,也减少了指令等待处理所产生的延迟。现在生产的微处理器至少有2层流水线。[来源请求](Atmel
AVR 与 PIC 单片机 都有2层流水线)Intel Pentium 4 处理器有20层流水线。
以下表格具体列出3层流水线理论:
以汇编语言表示将会被运行的指令列表:
代码的运行循序如下:
第1周期
从主存储器中读取LOAD指令。
第2周期
LOAD 指令被运行,同时从主存储器中读取 MOVE 指令。
第3周期
LOAD 指令在存储层(Store stage),LOAD 指令的运行结果 #40 (the number 40) 将被存储到暂存器A。同时,MOVE 指令被运行。MOVE 指令必须等待 LOAD 指令运行完毕才能将 暂存器A 中的内容移动到 暂存器B 中。
第4周期
STORE 指令被加载,同时 MOVE 指令运行完毕,并且 ADD 指令被运行。
注意! 有时候,一个指令会依赖于其他指令的运行结构(例如以上的 MOVE 指令)。当一个指令因为操作数而需引用一个特定的位置,读取(作为输入)或者写入(作为输入),运行那些指令的循序不同于程序原本的运行循序能导致危害(hazards)。现时有机种技术用于预防危害,或者绕过(working around)它们。
很多处理器的流水线深度到5层、7层、10层,甚至31层(像是Intel Pentium
4 Prescott)。Xelerator X10q甚至有多于1000层的流水线深度[1]。当程序出现分支将不利于过深流水线,整条流水线将会无效化。为了减轻此状况,分支预测就变的重要。如果分支预测错误,也能够借由自行退出预测来避免加速恶化效率。在某些运用上,像是超级电脑运算,为了能够将超长流水线的运算优势凸显出来,会特地将程序写的极少分支化来避免预测失败,而且深度的流水线主要是为了能降低每个时钟频率运行的指令量而设计。当程序经常出现分支,把分支重新排序(像是将更为需要的指令提早放入流水线中)而将明显的降低损失的速度以避免将分支“冲垮”。像是gcov程序能够使用一种覆盖率检查的技术检查特定分支的运行频率,但是这种检查法经常是优化的最后手段。处理能力高的流水线会因为很多分支的程序而降低效率,这是因为处理器不知道下一个要读取的指令是什么,而需要等待完成分支指令而让流水线清空。处理完分支之后,下一个指令就要经过所有流水线,直到整个指令集的结果出现,而处理器才会再继续运行。而在极端的状况下,流水线处理器的性能理论上可能会与未流水线处理器一致,甚至是每层流水线都在待命状态,而且指令经常在流水线之中跑来跑去时的性能比较差一些。
由于指令流水线,处理器读取机器码时并不会立即运行。因为如此,在很接近的地方运行更新机器码的动作就可能无法作用,因为这些机器码已经进入预读输入队列内。指令高速缓存又会让此现象更加恶化。不过这只会在能够自我变更的程序出现此现象。
原出处:http://zh.wikipedia.org/wiki/%E6%8C%87%E4%BB%A4%E6%B5%81%E6%B0%B4%E7%BA%BF
指令流水线(英语:Instruction pipeline)是为了让计算机和其它数字电子设备能够加速指令的通过速度(单位时间内被运行的指令数量)而设计的技术。
流水线是假设程序运行时有一连串的指令要被运行(垂直座标i是指令集,水平座标表时间t)。绝大多数当代的CPU都是利用时钟频率驱动。
而CPU是由内部的逻辑门与触发器组成。当受到时钟频率触发时,触发器得到新的数值,并且逻辑门需要一段时间来解析出新的数值,而当受到下一个时钟频率触发时触发器又得到新的数值,以此类推。而借由逻辑门分散成很多小区块,再让触发器链接这些小区块组,使逻辑门输出正确数值的时间延迟得以减少,这样一来就可以减少指令运行所需要的周期。
举例来说,典型的RISC流水线被分解成五个阶段,每个阶段之间使用触发器链接。
读取指令
指令解码与读取暂存器
运行
存储器访问
写回暂存器
危害:当一名程序员(或者组合者/编译者)编写组合代码(或者汇编码)时,他们会假定每个指令是循序运行的。而这个假设会使流水线无效。当此现象发生后程序会表现的不正常,而此现象就是危害。不过目前有提供几种技术来解决这些危害像是转发与延迟等。
未流水线的架构产生的效率低,因为有些CPU的模块在其他模块运行时是闲置的。流水线虽并不会完全消除CPU的闲置时间,但是能够让这些模块并发运作而大幅提升程序运行的效率。
管线在处理器的内部被组织成层级,各个层级的管线能半独立地单独运作。每一个层级都被管理并且链接到一条“链“,因而每个层级的输出被送到其它层级直至任务完成。处理器的这种组织方式能使总体的处理时间显著缩短。
但并不是所有的指令都是独立的。在一条简单的流水线中,完成一个指令可能需要5层。(如图:RISC机器的五层流水线示意图) 要在最佳性能下运算,当第一个指令被运行时,这个流水线需要运行随后4条独立的指令。如果随后4条指令依赖于第一条指令的输出,流水线控制逻辑必须插入延迟时钟频率周期到流水线内,直到依赖被解除。而转发技术能显著减少延时。凭借多个层,虽然流水线在理论上能提高性能,优胜于无流水线的内核(假设时钟频率也因应层的数量按比例增加),但事实上,许多脚本设计中并不会考虑到理想的运行。
优缺点 [编辑]
并非在所有情况下流水线技术都起作用。可能有一些缺点。如果一条指令流水线能够在每一个时钟频率周期(clockcycle)接纳一条新的指令,被称为完整流水线(fully pipelined)。因流水线中的指令需要延迟处理而要等待数个时钟频率周期,被称为非完整流水线。
流水线的优点
减少了处理器执行指令所需要的时钟频率周期,在通常情况下增加了指令的输入频率(issue-rate)。
一些集成电路(combinational circuits),例如加法器(adders)或者乘法器(multipliers),通过添加更多的环路(circuitry)使其工作得更快。如果以流水线替代,能相对地减少环路。
没有流水线的优点
非流水线的处理器每次(at a time)只运行一个指令。防止分支延时(事实上,每个分支都会产生延时)和串行指令被并行运行产生的问题。设计比较简单和较低生产成本。
在运行相同的指令时,非流水线处理器的指令传输延迟时间(The
instruction latency)比流水线处理器明显较短。这是因为流水线的处理器必须在数据路径(data path)中添加额外触发器(flip-flops)。
非流水线处理器有固定指令位宽(a stable instruction bandwidth)。流水线处理器的性能更难以预测,并且不同的程序之间的变化(vary)可能更大。
示例 [编辑]
一般的流水线 [编辑]

一般的四层流水线架构;不同的颜色格表示不同的指令
右图是一般有4层流水线的示意图:
读取指令(Fetch)
指令解码(Decode)
运行指令(Execute)
写回运行结果(Write-back)
上方的大灰色格是一连串未运行的指令;下方的大灰色格则是已运行完成的指令;中间的大白色格则是流水线。
运行顺序如以下列表所示:
| 时序 | 运行情况 |
|---|---|
| 0 | 四条指令等待运行 |
| 1 | 从主存储器(memory)中读取绿色指令 |
| 2 | 绿色指令被解码 从主存储器中读取紫色指令 |
| 3 | 绿色指令被运行(事实上运算已经开始(performed)) 紫色指令被解码 从主存储器中读取蓝色指令 |
| 4 | 绿色指令的运算结果被写回到寄存器(register)或者主存储器 紫色指令被运行 蓝色指令被解码 从主存储器中读取红色指令 |
| 5 | 绿色指令被运行完毕 紫色指令的运算结果被写回到寄存器或者主存储器 蓝色指令被运行 红色指令被解码 |
| 6 | 紫色指令被运行完毕 蓝色指令的运算结果被写回到寄存器或者主存储器 红色指令被运行 |
| 7 | 蓝色指令被运行完毕 红色指令的运算结果被写回到寄存器或者主存储器 |
| 8 | 红色指令被运行完毕 |
| 9 | 所有指令皆运行完毕 |
汽泡 [编辑]

一个气泡在编号为3的时钟频率周期中,指令运行被延迟
主条目:气泡 (电脑运算)
指令运行中产生一个“打嗝”(hiccup),在流水线中生成一个没有实效的气泡。
如右图,在编号为2的时钟频率周期中,紫色指令的读取被延迟,并且在编号为3的时钟频率周期中解码层也产生了一个气泡。所有在紫色指令之后的指令都被延迟运行,而在其之前已经运行了的指令则不受影响。
由于气泡使指令运行延迟了一个时钟频率周期,完成全部4条指令的运行共需要8个时钟频率周期。
而气泡处对指令的读取、解码、运行与写回都没有实质影响。这可以使用nop代码来完成。
示例一 [编辑]
一个典型的加法指令可能会写成像ADD A, B, C,而中央处理器(CPU)会将主存储器(Memory)内
A 位置与 B 位置的数值相加后放到 C 位置。在流水线处理器内,流水线控制器会将这个指令分拆成一连串微指令:
LOAD A, R1 LOAD B, R2 ADD R1, R2, R3 STORE R3, C LOAD next instruction
R1, R2 和 R3是CPU内的暂存器(register是CPU里面能够快速访问的暂存存储器)。主存储器内标注为A位置和B位置之存储单元中的数值被加载(或称
复制)到暂存器 R1 和 R2 中,然后送到加法器中相加,结果输出到暂存器 R3 中,R3 中的数值再被存储到主存储器内标注为C位置的存储单元。
而且在非流水线的例子,开始驱动加法动作到完成的时间是不变的。
在这个示例中的流水线分为3层:加载,运行,存储。每一步被称为流水线层(或称流水线阶段)(pipeline stages)。
在非流水线处理器中,同一时间只允许一个层运作,所以必须等待指令运行完毕才能开始运行下一条指令。在流水线处理器中,所有的层能在同一时间处理不同的指令。当一条指令在运行层,另外一条指令在解码层,第三条指令在读取层。
流水线没有减少运行指令所花费的时间; 它增加了在同一时间被处理的指令数量,并且减少了完成指令之间的延迟。随着处理器中流水线层的数量增加,能在同一时间被处理的指令数量也相应增加,也减少了指令等待处理所产生的延迟。现在生产的微处理器至少有2层流水线。[来源请求](Atmel
AVR 与 PIC 单片机 都有2层流水线)Intel Pentium 4 处理器有20层流水线。
示例二 [编辑]
以下表格具体列出3层流水线理论:| 流水线层(Stage) | 说明(Description) |
|---|---|
| 读取(Load) | 从主存储器中读取指令 |
| 运行(Execute) | 运行指令 |
| 存储(Store) | 将运行结果存储到主存储器和/或者暂存器 |
LOAD #40, A ; 讀取 40 載入 A 內 MOVE A, B ; 將 A 內的數據複製到 B 內 ADD #20, B ; 將 B 內的數據與 20 相加 STORE B, 0x300 ; 將 B 內的數據儲存到地址為 0x300 的存儲器單元
代码的运行循序如下:
| 读取 | 运行 | 存储 |
|---|---|---|
| LOAD |
| 读取 | 运行 | 存储 |
|---|---|---|
| MOVE | LOAD |
| 读取 | 运行 | 存储 |
|---|---|---|
| ADD | MOVE | LOAD |
| 读取 | 运行 | 存储 |
|---|---|---|
| STORE | ADD | MOVE |
注意! 有时候,一个指令会依赖于其他指令的运行结构(例如以上的 MOVE 指令)。当一个指令因为操作数而需引用一个特定的位置,读取(作为输入)或者写入(作为输入),运行那些指令的循序不同于程序原本的运行循序能导致危害(hazards)。现时有机种技术用于预防危害,或者绕过(working around)它们。
复杂化 [编辑]
很多处理器的流水线深度到5层、7层、10层,甚至31层(像是Intel Pentium4 Prescott)。Xelerator X10q甚至有多于1000层的流水线深度[1]。当程序出现分支将不利于过深流水线,整条流水线将会无效化。为了减轻此状况,分支预测就变的重要。如果分支预测错误,也能够借由自行退出预测来避免加速恶化效率。在某些运用上,像是超级电脑运算,为了能够将超长流水线的运算优势凸显出来,会特地将程序写的极少分支化来避免预测失败,而且深度的流水线主要是为了能降低每个时钟频率运行的指令量而设计。当程序经常出现分支,把分支重新排序(像是将更为需要的指令提早放入流水线中)而将明显的降低损失的速度以避免将分支“冲垮”。像是gcov程序能够使用一种覆盖率检查的技术检查特定分支的运行频率,但是这种检查法经常是优化的最后手段。处理能力高的流水线会因为很多分支的程序而降低效率,这是因为处理器不知道下一个要读取的指令是什么,而需要等待完成分支指令而让流水线清空。处理完分支之后,下一个指令就要经过所有流水线,直到整个指令集的结果出现,而处理器才会再继续运行。而在极端的状况下,流水线处理器的性能理论上可能会与未流水线处理器一致,甚至是每层流水线都在待命状态,而且指令经常在流水线之中跑来跑去时的性能比较差一些。
由于指令流水线,处理器读取机器码时并不会立即运行。因为如此,在很接近的地方运行更新机器码的动作就可能无法作用,因为这些机器码已经进入预读输入队列内。指令高速缓存又会让此现象更加恶化。不过这只会在能够自我变更的程序出现此现象。

相关文章推荐
- CPU指令的流水线执行
- 指令流水线总结
- 指令流水线归纳总结
- 如何计算k段流水线执行n条指令的执行时间
- 超标量、超级流水线、超长指令字、向量机
- CPU指令的流水线执行
- 指令流水线归纳总结
- CPU技术——指令重叠、超标量、流水线
- 超标量、超级流水线、超长指令字、向量机 SIMD
- 关于超标量、超级流水线、超长指令字、向量机(习题)
- 图形流水线之旅 part2 GPU存储架构和指令处理器
- 指令流水线的计算
- 指令流水线
- 【计算机系统】指令流水线
- RISC和CICS指令流水线的区别
- 指令流水线的吞吐率
- ARM处理器的三级流水线和ARM指令及寻址方式
- 指令流水线的吞吐率
- 指令流水线
- 优化分支代码——避免跳转指令堵塞流水线