ubuntu hadoop安装以及配置
2013-06-04 21:08
405 查看
Hadoop的安装以及配置
一、linux下java环境的配置
1、 下载linux版本的jdk安装包,我用的就是jdk-6u43-linux-i586.bin(二进制文件)
执行Apt-get install /opt/jdk-6u43-linux-i586.bin
将文件安装在/opt/路径下

2、 Jdk开发环境的配置
执行vim /etc/profile
将下面代码加入profile文本最后面
#set javaenvironment
export JAVA_HOME=/opt/jdk1.6.0_43
exportJRE_HOME=/opt/jdk1.6.0_43/jre
exportCLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
exportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
执行source /etc/profile 使文件生效
执行java –version 查看java的版本号,如果配置成功会有一下信息出来

二、ssh免钥匙登陆的配置
先看看伪分布的ssh免钥匙的登陆
三、hadoop的安装以及配置
1、 下载hadoop文件
现在稳定版本是hadoop1.1x版本,最好是稳定版的,因为支持是功能是最多的,hadoop最好下tar包,如图

2、 添加一个hadoop账户
执行useradd hadoop 这样就在/home 目录下新建了一个账户
3、 把下载的hadoop文件放到/home/hadoop 下面
进入/home/hadoop目录
执行 tar –xvf hadoop-1.1.2-bin.tar.gz 对文件进行解压缩

4、 hadoop环境变量配置
(1)修改hadoop-env.sh文件
进入/home/hadoop/hadoop-1.1.2/conf
执行gedit hadoop-env.sh
将export JAVA_HOME=/opt/jdk1.6.0_43 加入文件当中

执行source /home/hadoop/hadoop-1.1.2/conf/hadoop-env.sh 使文件生效
(2)修改hdfs-site.xml文件
进入/home/hadoop/hadoop-1.1.2/conf目录
执行gedit hdfs-site.xml
在文档中加入<property>
<name>dfs.replication</name>
<value>1</value>
</property>

(3)修改core-site.xml文件
同上的方法修改<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
(4)修改mapred-site.xml文件
同上的方法 <property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
5、 添加hadoop命令行到linux
执行gedit /etc/profile
添加export HADOOP_HOME=/home/hadoop-1.1.2/ hadoop安装目录
执行 source /etc/profile 使文件生效
6、 使hadoop 文件系统格式化
进入 /home/hadoop/ hadoop-1.1.2/bin
执行./hadoop namenode –format 进行格式化
执行./hadoop start-all.sh 全面启动hdfs文件系统
7、 测试hadoop文件系统
执行jps看结果

使用web功能
localhost:50070hdfs 文件系统
localhost:50030hdfs mapreduce文件框架
四、测试文件传输功能
传输文件、删除文件。。。。。。。。。
上传文件

hadoop常用命令
Hdfs的命令格式
./hadoopfs –rmr /tmp
./hadoopfs –put /opt/java hdfs://localhost:9000/
启动Hadoop
· 进入HADOOP_HOME目录。
· 执行sh bin/start-all.sh
关闭Hadoop
· 进入HADOOP_HOME目录。
· 执行sh bin/stop-all.sh
1、查看指定目录下内容
hadoop dfs –ls [文件目录]
eg: hadoop dfs –ls /user/wangkai.pt
2、打开某个已存在文件
hadoop dfs –cat [file_path]
eg:hadoop dfs -cat /user/wangkai.pt/data.txt
3、将本地文件存储至hadoop
hadoop fs –put [本地地址] [hadoop目录]
hadoop fs –put /home/t/file.txt /user/t
(file.txt是文件名)
4、将本地文件夹存储至hadoop
hadoop fs –put [本地目录] [hadoop目录]
hadoop fs –put /home/t/dir_name /user/t
(dir_name是文件夹名)
5、将hadoop上某个文件down至本地已有目录下
hadoop fs -get [文件目录] [本地目录]
hadoop fs –get /user/t/ok.txt /home/t
6、删除hadoop上指定文件
hadoop fs –rm [文件地址]
hadoop fs –rm /user/t/ok.txt
7、删除hadoop上指定文件夹(包含子目录等)
hadoop fs –rm [目录地址]
hadoop fs –rmr /user/t
8、在hadoop指定目录内创建新目录
hadoop fs –mkdir /user/t
9、在hadoop指定目录下新建一个空文件
使用touchz命令:
hadoop fs -touchz /user/new.txt
10、将hadoop上某个文件重命名
使用mv命令:
hadoop fs –mv /user/test.txt /user/ok.txt (将test.txt重命名为ok.txt)
11、将hadoop指定目录下所有内容保存为一个文件,同时down至本地
hadoop dfs –getmerge /user /home/t
12、将正在运行的hadoop作业kill掉
hadoop job –kill [job-id]
五、测试mapreduce功能
目的:将/home/hadoop/ hadoop-1.1.2/bin下面的全部*.sh文件放到hdfs://localhost:9000/input文件中,并且通过mapreduce计算他里面require单词出现的频率
执行./hadoop fs –mkdir /input 在hadoop系统根目录下建input文件夹
执行./hadoop fs -put *.sh /input/

执行./hadoop jar hadoop-examples-1.1.2.jarwordcount /input /output计算require单词数

点击part—r00000查看结果
在电脑上面计算所有*.sh文件里面required出现的次数
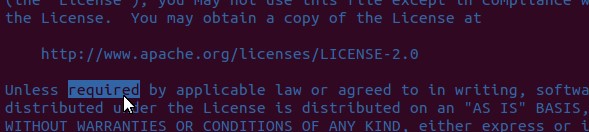
执行 grep *.sh 然后执行grep require *.sh |wc
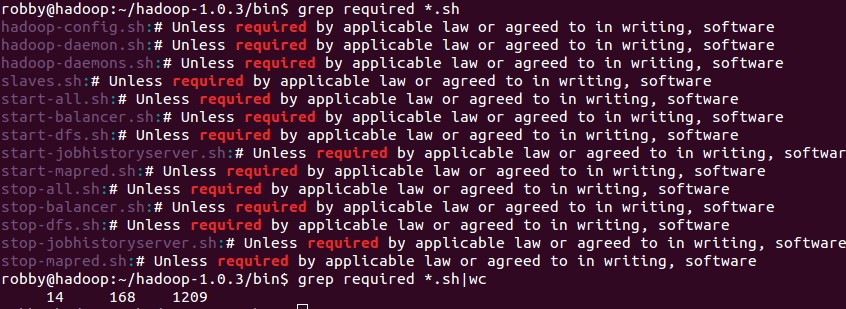
结果是14个与mapreduce结果一样
一、linux下java环境的配置
1、 下载linux版本的jdk安装包,我用的就是jdk-6u43-linux-i586.bin(二进制文件)
执行Apt-get install /opt/jdk-6u43-linux-i586.bin
将文件安装在/opt/路径下
2、 Jdk开发环境的配置
执行vim /etc/profile
将下面代码加入profile文本最后面
#set javaenvironment
export JAVA_HOME=/opt/jdk1.6.0_43
exportJRE_HOME=/opt/jdk1.6.0_43/jre
exportCLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
exportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
执行source /etc/profile 使文件生效
执行java –version 查看java的版本号,如果配置成功会有一下信息出来
二、ssh免钥匙登陆的配置
先看看伪分布的ssh免钥匙的登陆
三、hadoop的安装以及配置
1、 下载hadoop文件
现在稳定版本是hadoop1.1x版本,最好是稳定版的,因为支持是功能是最多的,hadoop最好下tar包,如图
2、 添加一个hadoop账户
执行useradd hadoop 这样就在/home 目录下新建了一个账户
3、 把下载的hadoop文件放到/home/hadoop 下面
进入/home/hadoop目录
执行 tar –xvf hadoop-1.1.2-bin.tar.gz 对文件进行解压缩
4、 hadoop环境变量配置
(1)修改hadoop-env.sh文件
进入/home/hadoop/hadoop-1.1.2/conf
执行gedit hadoop-env.sh
将export JAVA_HOME=/opt/jdk1.6.0_43 加入文件当中
执行source /home/hadoop/hadoop-1.1.2/conf/hadoop-env.sh 使文件生效
(2)修改hdfs-site.xml文件
进入/home/hadoop/hadoop-1.1.2/conf目录
执行gedit hdfs-site.xml
在文档中加入<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(3)修改core-site.xml文件
同上的方法修改<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
(4)修改mapred-site.xml文件
同上的方法 <property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
5、 添加hadoop命令行到linux
执行gedit /etc/profile
添加export HADOOP_HOME=/home/hadoop-1.1.2/ hadoop安装目录
执行 source /etc/profile 使文件生效
6、 使hadoop 文件系统格式化
进入 /home/hadoop/ hadoop-1.1.2/bin
执行./hadoop namenode –format 进行格式化
执行./hadoop start-all.sh 全面启动hdfs文件系统
7、 测试hadoop文件系统
执行jps看结果
使用web功能
localhost:50070hdfs 文件系统
localhost:50030hdfs mapreduce文件框架
四、测试文件传输功能
传输文件、删除文件。。。。。。。。。
上传文件
hadoop常用命令
Hdfs的命令格式
./hadoopfs –rmr /tmp
./hadoopfs –put /opt/java hdfs://localhost:9000/
启动Hadoop
· 进入HADOOP_HOME目录。
· 执行sh bin/start-all.sh
关闭Hadoop
· 进入HADOOP_HOME目录。
· 执行sh bin/stop-all.sh
1、查看指定目录下内容
hadoop dfs –ls [文件目录]
eg: hadoop dfs –ls /user/wangkai.pt
2、打开某个已存在文件
hadoop dfs –cat [file_path]
eg:hadoop dfs -cat /user/wangkai.pt/data.txt
3、将本地文件存储至hadoop
hadoop fs –put [本地地址] [hadoop目录]
hadoop fs –put /home/t/file.txt /user/t
(file.txt是文件名)
4、将本地文件夹存储至hadoop
hadoop fs –put [本地目录] [hadoop目录]
hadoop fs –put /home/t/dir_name /user/t
(dir_name是文件夹名)
5、将hadoop上某个文件down至本地已有目录下
hadoop fs -get [文件目录] [本地目录]
hadoop fs –get /user/t/ok.txt /home/t
6、删除hadoop上指定文件
hadoop fs –rm [文件地址]
hadoop fs –rm /user/t/ok.txt
7、删除hadoop上指定文件夹(包含子目录等)
hadoop fs –rm [目录地址]
hadoop fs –rmr /user/t
8、在hadoop指定目录内创建新目录
hadoop fs –mkdir /user/t
9、在hadoop指定目录下新建一个空文件
使用touchz命令:
hadoop fs -touchz /user/new.txt
10、将hadoop上某个文件重命名
使用mv命令:
hadoop fs –mv /user/test.txt /user/ok.txt (将test.txt重命名为ok.txt)
11、将hadoop指定目录下所有内容保存为一个文件,同时down至本地
hadoop dfs –getmerge /user /home/t
12、将正在运行的hadoop作业kill掉
hadoop job –kill [job-id]
五、测试mapreduce功能
目的:将/home/hadoop/ hadoop-1.1.2/bin下面的全部*.sh文件放到hdfs://localhost:9000/input文件中,并且通过mapreduce计算他里面require单词出现的频率
执行./hadoop fs –mkdir /input 在hadoop系统根目录下建input文件夹
执行./hadoop fs -put *.sh /input/
执行./hadoop jar hadoop-examples-1.1.2.jarwordcount /input /output计算require单词数
点击part—r00000查看结果
在电脑上面计算所有*.sh文件里面required出现的次数
执行 grep *.sh 然后执行grep require *.sh |wc
结果是14个与mapreduce结果一样

相关文章推荐
- Ubuntu与Centos的Hadoop安装以及编译运行MapReduce,Hadoop集群安装配置教程
- ubuntu环境下eclipse的安装以及hadoop插件的配置
- Ubuntu上为eclipse安装hadoop插件以及在eclipse运行Hadoop程序
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
- ubuntu 安装 nginx以及apache安装配置
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
- Ubuntu Server 12.04安装桌面环境以及配置VNC
- hadoop在ubuntu下的伪分布式安装配置
- 在ubuntu系统下安装jdk与tomcat以及环境变量的配置
- pytorch-0.2成功调用GPU:ubuntu16.04,Nvidia驱动安装以及最新cuda9.0与cudnnV7.0配置
- Ubuntu下伪分布式模式Hadoop的安装及配置
- 【转】ubuntu下安装eclipse以及配置python编译环境
- Ubuntu 12.04 安装Java JDK 以及配置过程
- Ubuntu配置hadoop单机+伪分布式环境+eclipse--安装hadoop(一)
- UBuntu 14.04下安装tftp服务器以及相关配置
- [置顶] 安装Idea(集成scala)以及在windows上配置spark(hadoop依赖)本地开发环境
- ubuntu14.04下配置Java环境以及安装最新版本的eclipse
- Ubuntu系统安装+Hadoop伪分布式环境搭建+eclipse环境配置
- Hadoop安装教程_单机/伪分布式配置_Ubuntu 14.04/Hadoop 2.4.1