lucene-索引文件格式
2013-05-30 10:35
232 查看
转载:http://blog.163.com/sukerl@126/blog/static/112027649200911148459201/
3.1 索引文件结构
Lucene使用文件扩展名标识不同的索引文件,文件名标识不同版本或者代(generation)的索引片段(segment)。如.fnm文件存储域Fields名称及其属性,.fdt存储文档各项域数据,.fdx存储文档在fdt中的偏移位置即其索引文件,.frq存储文档中term位置数据,.tii文件存储term字典,.tis文件存储term频率数据,.prx存储term接近度数据,.nrm存储调节因子数据,另外segments_X文件存储当前最新索引片段的信息,其中X为其最新修改版本,segments.gen存储当前版本即X值,这些文件的详细介绍上节已说过了。
下面的图描述了一个典型的lucene索引文件列表:
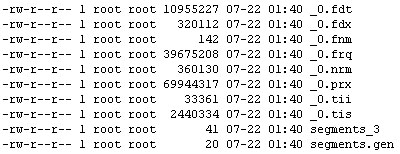
如果将它们的关系划成图则如下所示:
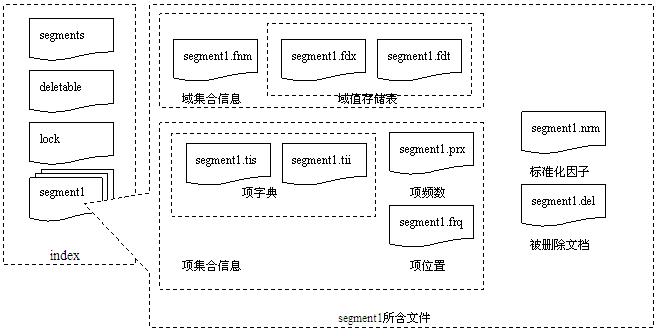
这些文件中存储数据的详细结构是怎样的呢,下面几个小节逐一介绍它们,熟悉它们的结构非常有助于优化Lucene的查询和索引效率和存储空间等。
3.2 每个Index包含的单个文件
下面几节介绍的文件存在于每个索引index中,并且只有一份。
3.2.1 Segments文件
索引中活动(active)的Segments被存储在segment
info文件中,segments_N,在索引中可能会包含一个或多个segments_N文件。然而,最大一代的那个文件(the
one with largest generation)是活动的片断文件(这时更旧的segments_N文件依然存在(are
present)是因为它们暂时(temporarily)还不能被删除,或者,一个writer正在处理提交请求(in
the process of committing),或者一个用户定义的(custom)IndexDeletionPolicy正被使用)。这个文件按照名称列举每一个片断(lists
each segment by name),详细描述分离的标准(seperate norm)和要删除的文件(deletion
files),并且还包含了每一个片断的大小。
对2.1版本来说,还有一个文件segments.gen。这个文件包含了该索引中当前生成的代(current
generation)(segments_N中的_N)。这个文件仅用于一个后退处理(fallback)以防止(in
case)当前代(current generation)不能被准确地(accurately)通过单独地目录文件列举(by
directory listing alone)来确定(determened)(由于某些NFS客户端因为基于时间的目录(time-based
directory)的缓存终止(cache expiration)而引起)。这个文件简单地包含了一个int32的版本头(version
header)(SegmentInfos.FORMAT_LOCKLESS=-2),遵照代的记录(followed
by the generation recorded)规则,对int64来说会写两次(write
twice)。
3.2.2 Lock文件
写锁(write lock)文件名为“write.lock”,它缺省存储在索引目录中。如果锁目录(lock
directory)与索引目录不一致,写锁将被命名为“XXXX-write.lock”,其中“XXXX”是一个唯一的前缀(unique
prefix),来源于(derived from)索引目录的全路径(full
path)。当这个写锁出现时,一个writer当前正在修改索引(添加或者清除文档)。这个写锁确保在一个时刻只有一个writer修改索引。
需要注意的是在2.1版本之前(prior
to),Lucene还使用一个commit
lock,这个锁在2.1版本里被删除了。
3.2.3 Deletable文件
在Lucene 2.1版本之前,有一个“deletable”文件,包含了那些需要被删除文档的详细资料。在2.1版本后,一个writer会动态地(dynamically)计算哪些文件需要删除,因此,没有文件被写入文件系统。
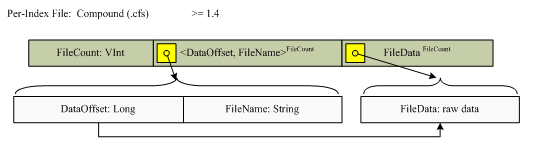
3.2.4 Compound文件(.cfs)
从Lucene 1.4版本开始,compound文件格式成为缺省信息。这是一个简单的容器(container)来服务所有下一章节(next
section)描述的文件(除了.del文件),格式如下:
结构如下图所示:
3.1 索引文件结构
Lucene使用文件扩展名标识不同的索引文件,文件名标识不同版本或者代(generation)的索引片段(segment)。如.fnm文件存储域Fields名称及其属性,.fdt存储文档各项域数据,.fdx存储文档在fdt中的偏移位置即其索引文件,.frq存储文档中term位置数据,.tii文件存储term字典,.tis文件存储term频率数据,.prx存储term接近度数据,.nrm存储调节因子数据,另外segments_X文件存储当前最新索引片段的信息,其中X为其最新修改版本,segments.gen存储当前版本即X值,这些文件的详细介绍上节已说过了。
下面的图描述了一个典型的lucene索引文件列表:
如果将它们的关系划成图则如下所示:
这些文件中存储数据的详细结构是怎样的呢,下面几个小节逐一介绍它们,熟悉它们的结构非常有助于优化Lucene的查询和索引效率和存储空间等。
3.2 每个Index包含的单个文件
下面几节介绍的文件存在于每个索引index中,并且只有一份。
3.2.1 Segments文件
索引中活动(active)的Segments被存储在segment
info文件中,segments_N,在索引中可能会包含一个或多个segments_N文件。然而,最大一代的那个文件(the
one with largest generation)是活动的片断文件(这时更旧的segments_N文件依然存在(are
present)是因为它们暂时(temporarily)还不能被删除,或者,一个writer正在处理提交请求(in
the process of committing),或者一个用户定义的(custom)IndexDeletionPolicy正被使用)。这个文件按照名称列举每一个片断(lists
each segment by name),详细描述分离的标准(seperate norm)和要删除的文件(deletion
files),并且还包含了每一个片断的大小。
对2.1版本来说,还有一个文件segments.gen。这个文件包含了该索引中当前生成的代(current
generation)(segments_N中的_N)。这个文件仅用于一个后退处理(fallback)以防止(in
case)当前代(current generation)不能被准确地(accurately)通过单独地目录文件列举(by
directory listing alone)来确定(determened)(由于某些NFS客户端因为基于时间的目录(time-based
directory)的缓存终止(cache expiration)而引起)。这个文件简单地包含了一个int32的版本头(version
header)(SegmentInfos.FORMAT_LOCKLESS=-2),遵照代的记录(followed
by the generation recorded)规则,对int64来说会写两次(write
twice)。
| 版本 | 包含的项 | 数目 | 类型 | 描述 |
| 2.1之前版本 | Format | 1 | Int32 | 在Lucene1.4中为-1,而在Lucene 2.1中为-3(SegmentsInfos.FORMAT_SINGLE_NORM_FILE) |
| Version | 1 | Int64 | 统计在删除和添加文档时,索引被更改了多少次。 | |
| NameCounter | 1 | Int32 | 用于为新的片断文件生成新的名字。 | |
| SegCount | 1 | Int32 | 片断的数目 | |
| SegName | SegCount | String | 片断的名字,用于所有构成片断索引的文件的文件名前缀。 | |
| SegSize | SegCount | Int32 | 包含在片断索引中的文档的数目。 | |
| 2.1及之后版本 | Format | 1 | Int32 | 在Lucene 2.1和Lucene 2.2中为-3(SegmentsInfos.FORMAT_SINGLE_NORM_FILE) |
| Version | 1 | Int64 | 同上 | |
| NameCounter | 1 | Int32 | 同上 | |
| SegCount | 1 | Int32 | 同上 | |
| SegName | SegCount | String | 同上 | |
| SegSize | SegCount | Int32 | 同上 | |
| DelGen | SegCount | Int64 | 为分离的删除文件的代的数目(generation count of the separate deletes file),如果值为-1,表示没有分离的删除文件。如果值为0,表示这是一个2.1版本之前的片断,这时你必须检查文件是否存在_X.del这样的文件。任意大于0的值,表示有分离的删除文件,文件名为_X_N.del。 | |
| HasSingleNormFile | SegCount | Int8 | 该值如果为1,表示Norm域(field)被写为一个单一连接的文件(single joined file)中(扩展名为.nrm),如果值为0,表示每一个field的norms被存储为分离的.fN文件中,参考下面的“标准化因素(Normalization Factors)” | |
| NumField | SegCount | Int32 | 表示NormGen数组的大小,如果为-1表示没有NormGen被存储。 | |
| NormGen | SegCount * NumField | Int64 | 记录分离的标准文件(separate norm file)的代(generation),如果值为-1,表示没有normGens被存储,并且当片断文件是2.1之前版本生成的时,它们全部被假设为0(assumed to be 0)。而当片断文件是2.1及更高版本生成的时,它们全部被假设为-1。这时这个代(generation)的意义与上面DelGen的意义一样。 | |
| IsCompoundFile | SegCount | Int8 | 记录是否该片断文件被写为一个复合的文件,如果值为-1表示它不是一个复合文件(compound file),如果为1则为一个复合文件。另外如果值为0,表示我们需要检查文件系统是否存在_X.cfs。 | |
| 2.3 | Format | 1 | Int32 | 在Lucene 2.3中为-4 (SegmentInfos.FORMAT_SHARED_DOC_STORE) |
| Version | 1 | Int64 | 同上 | |
| NameCounter | 1 | Int32 | 同上 | |
| SegCount | 1 | Int32 | 同上 | |
| SegName | SegCount | String | 同上 | |
| SegSize | SegCount | Int32 | 同上 | |
| DelGen | SegCount | Int64 | 同上 | |
| DocStoreOffset | 1 | Int32 | 如果值为-1则该segment有自己的存储文档的fields数据和term vectors的文件,并且DocStoreSegment, DocStoreIsCompoundFile不会存储。在这种情况下,存储fields数据(*.fdt和*.fdx文件)以及term vectors数据(*.tvf和*.tvd和*.tvx文件)的所有文件将存储在该segment下。另外,DocStoreSegment将存储那些拥有共享的文档存储文件的segment。DocStoreIsCompoundFile值为1如果segment存储为compound文件格式(如.cfx文件),并且DocStoreOffset值为那些共享文档存储文件中起始的文档编号,即该segment的文档开始的位置。在这种情况下,该segment不会存储自己的文档数据文件,而是与别的segment共享一个单一的数据文件集。 | |
| [DocStoreSegment] | 1 | String | 如上 | |
| [DocStoreIsCompoundFile] | 1 | Int8 | 如上 | |
| HasSingleNormFile | SegCount | Int8 | 同上 | |
| NumField | SegCount | Int32 | 同上 | |
| NormGen | SegCount * NumField | Int64 | 同上 | |
| IsCompoundFile | SegCount | Int8 | 同上 | |
| 2.4及以上 | Format | 1 | Int32 | 在Lucene 2.4中为-7 (SegmentInfos.FORMAT_HAS_PROX) |
| Version | 1 | Int64 | 同上 | |
| NameCounter | 1 | Int32 | 同上 | |
| SegCount | 1 | Int32 | 同上 | |
| SegName | SegCount | String | 同上 | |
| SegSize | SegCount | Int32 | 同上 | |
| DelGen | SegCount | Int64 | 同上 | |
| DocStoreOffset | 1 | Int32 | 同上 | |
| [DocStoreSegment] | 1 | String | 同上 | |
| [DocStoreIsCompoundFile] | 1 | Int8 | 同上 | |
| HasSingleNormFile | SegCount | Int8 | 同上 | |
| NumField | SegCount | Int32 | 同上 | |
| NormGen | SegCount * NumField | Int64 | 同上 | |
| IsCompoundFile | SegCount | Int8 | 同上 | |
| DeletionCount | SegCount | Int32 | 记录该segment中删除的文档数目 | |
| HasProx | SegCount | Int8 | 值为1表示该segment中至少一个fields的omitTf设置为false,否则为0 | |
| Checksum | 1 | Int64 | 存储segments_N文件中直到checksum的所有字节的CRC32 checksum数据,用来校验打开的索引文件的完整性(integrity)。 |
写锁(write lock)文件名为“write.lock”,它缺省存储在索引目录中。如果锁目录(lock
directory)与索引目录不一致,写锁将被命名为“XXXX-write.lock”,其中“XXXX”是一个唯一的前缀(unique
prefix),来源于(derived from)索引目录的全路径(full
path)。当这个写锁出现时,一个writer当前正在修改索引(添加或者清除文档)。这个写锁确保在一个时刻只有一个writer修改索引。
需要注意的是在2.1版本之前(prior
to),Lucene还使用一个commit
lock,这个锁在2.1版本里被删除了。
3.2.3 Deletable文件
在Lucene 2.1版本之前,有一个“deletable”文件,包含了那些需要被删除文档的详细资料。在2.1版本后,一个writer会动态地(dynamically)计算哪些文件需要删除,因此,没有文件被写入文件系统。
3.2.4 Compound文件(.cfs)
从Lucene 1.4版本开始,compound文件格式成为缺省信息。这是一个简单的容器(container)来服务所有下一章节(next
section)描述的文件(除了.del文件),格式如下:
| 版本 | 包含的项 | 数目 | 类型 | 描述 |
| 1.4之后版本 | FileCount | 1 | VInt | |
| DataOffset | FileCount | Long | ||
| FileName | FileCount | String | ||
| FileData | FileCount | raw | Raw文件数据是上面命名的所有单个的文件数据(the individual named above)。 |

相关文章推荐
- lucene 索引文件格式
- Lucene学习总结之三:Lucene的索引文件格式(1)
- lucene4.5源码分析系列:lucene默认索引的文件格式-总述
- Lucene学习总结之三:Lucene的索引文件格式(2)
- Lucene学习总结之三:Lucene的索引文件格式(2)
- Lucene学习总结之三:Lucene的索引文件格式(3)
- Lucene初探之索引文件格式
- Lucene学习之四:Lucene的索引文件格式(1)
- lucene产生的索引文件格式详解
- Lucene学习总结之三:Lucene的索引文件格式(2)
- Lucene学习总结(二) lucene索引文件格式
- Lucene学习总结之三:Lucene的索引文件格式(3)
- lucene索引文件格式介绍
- Lucene学习总结之三:Lucene的索引文件格式(1)
- Lucene学习总结之三:Lucene的索引文件格式(1)
- Lucene学习总结之三:Lucene的索引文件格式(1)
- Lucene的索引文件格式
- Lucene文件格式和索引过程分析
- lucene索引文件格式
- Lucene学习之四:Lucene的索引文件格式(2)