hadoop集群维护遇到的一些问题【持续更新】
2013-05-24 09:33
483 查看
1、向hadoop集群提交一些比较大的任务,集群负载很快就飚起来了,有的达到120多。
分析一下,应该是任务起的线程太多了。用jstack看一下,发现每个child的gc线程太多了:

达到了18个,一个child的gc线程就要开这么多,难怪负载会飙升。
修改提交作业的客户端配置 mapred-site.xml :

将child的gc方式设置成串行gc或者将并行gc的线程数设置的少一些。
ParallelGCThreads的默认算法:
ParallelGCThreads= cupNum < 8 ? cupNum : 3+(cupNum * 5) / 8
2、使用fairshare调度器,当在hadoop的监控页面中查看某个队列的作业时,不小心 将web地址的队列名去掉,如:
http://jobtracker:50030/jobqueue_details.jsp?queueName=a 将queueName=a改成
queueName=空 或者没有 的队列,jobtracker 会报下面的错误:
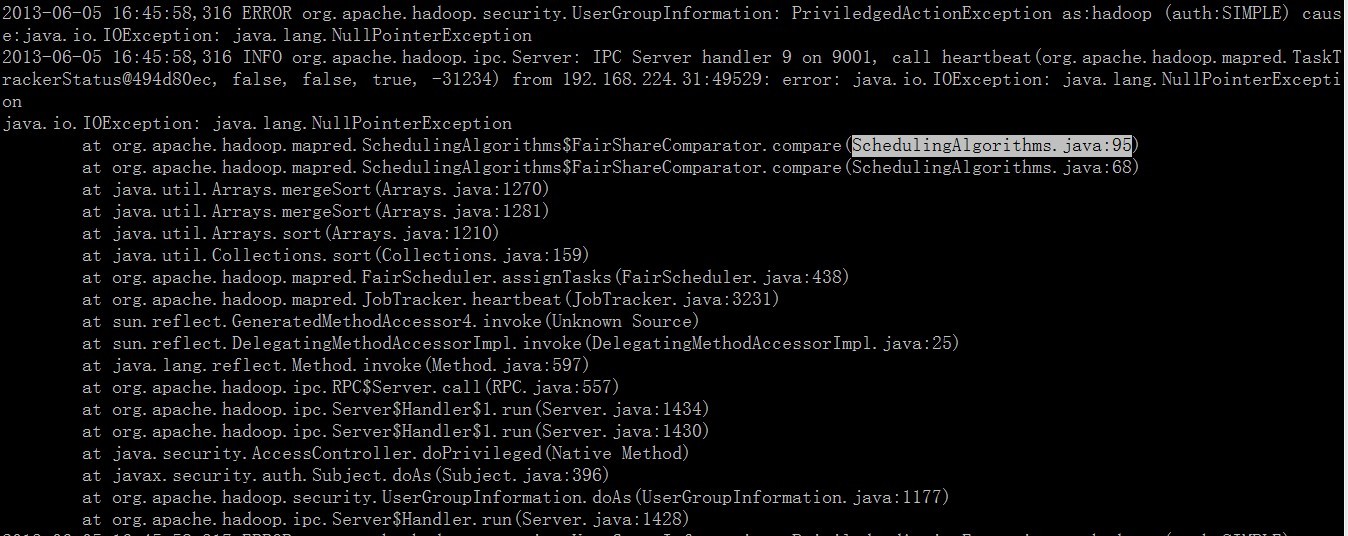
这是官方的一个bug
https://issues.apache.org/jira/browse/MAPREDUCE-3674
分析一下,应该是任务起的线程太多了。用jstack看一下,发现每个child的gc线程太多了:
达到了18个,一个child的gc线程就要开这么多,难怪负载会飙升。
修改提交作业的客户端配置 mapred-site.xml :
将child的gc方式设置成串行gc或者将并行gc的线程数设置的少一些。
ParallelGCThreads的默认算法:
ParallelGCThreads= cupNum < 8 ? cupNum : 3+(cupNum * 5) / 8
2、使用fairshare调度器,当在hadoop的监控页面中查看某个队列的作业时,不小心 将web地址的队列名去掉,如:
http://jobtracker:50030/jobqueue_details.jsp?queueName=a 将queueName=a改成
queueName=空 或者没有 的队列,jobtracker 会报下面的错误:
这是官方的一个bug
https://issues.apache.org/jira/browse/MAPREDUCE-3674

相关文章推荐
- caffe训练中遇到的一些问题(持续更新......)
- 基于docker搭建hadoop集群环境中遇到的一些问题
- cocos2d-x遇到的一些小问题总结-持续更新
- fedora23 中遇到的一些问题 (持续更新)
- docker遇到的一些小问题(持续更新ing)
- 关于一些平常JAVA知识及遇到问题的积累(持续更新)
- cas 部署过程中遇到的一些问题(持续更新)
- (持续更新)日积月累——iOS开发过程中遇到的一些小问题
- Hadoop运维中遇到的问题(持续更新中......)
- 【集群管理】可能遇到的问题及解决方法(持续更新中......)
- 【持续更新】刷题时遇到的一些问题
- 前端小技巧(持续更新,一些遇到问题的解决方案)
- selenium遇到的一些问题,持续更新
- JNI开发遇到的一些问题记录(持续记录更新)
- Kaldi运行过程中遇到的一些问题(持续更新...)
- Android开发jni遇到的一些问题,持续更新
- hadoop2.7.3分布式集群问题汇总(持续更新)
- sublime 使用中一些遇到问题解决方法和技巧汇总(持续更新)
- 安卓开发遇到的一些问题(持续更新)
- 记录oracle11g使用过程中遇到的一些问题,会持续更新。