推荐系统
2013-05-16 17:20
337 查看
很好的推荐系统的样例:
1)基于对用户兴趣的预测结果,为在线报纸的读者提供新闻报道;
2)基于顾客过去的购物和/或商品搜索历史,为在线零售商的顾客推荐他们可能想要买的商品。
推荐系统可以分成两大类:
1)基于内容的系统(Content-base System)主要考察的是推荐项的性质。例如,如果一个Netflix的用户观看了许多西部牛仔片,那么系统就会将数据库中属于“西部牛仔”类的电影推荐给该用户。
2)协同过滤系统(Collaborative System)主要通过计算相似度来推荐项。与某用户A相似的用户B所喜欢的项会推荐给用户A。
1 一个推荐系统模型
1.1效用矩阵
推荐系统应用当中,存在两类元素,一类是用户(user),另一类是项(item)。用户会偏爱某些项,这偏好信息必须要从数据中梳理出来。
数据本身可以表示成一个效用矩阵(utility matrix),该矩阵的每个(用户,项)所对应的元素值代表的是当前用户对当前项的喜好程度。
喜好程度值来自一个有序集合。假设该矩阵是稀疏的,即大部分元素都未知,未知意味着我们对当前用户对当前项的喜好信息不清楚。
例1.1 效用矩阵的例子,该矩阵代表用户对电影的评级(1-5级,5最高)结果。空白表示当前用户对当前电影没有评分。

用户分别用大写字母A,B,C和D表示。

大部分(用户,电影)对应的元素是空白,意味着用户并没有对电影进行评级。实际上,该矩阵可能更稀疏,因为用户只对所有电影的极小一部分进行了评级。
推荐系统的目标就是预测效用矩阵的空白元素。我们会问,用户A是否喜欢SW2?
思路1:我们在设计推荐系统的时候可以考虑电影的属性,比如制片人,导演,明星或者它们名字之间的相似度。发现SW1和SW2之间的相似性,从而由于A不喜欢SW1,得出A不太可能喜欢SW2的结论。
思路2:如果有多得多的数据,我们会注意到,给SW1和SW2同时评级的用户倾向于给这两者相相似的评级结果。于是,认为与A给SW1差评类似,也会给SW2一个差评。
在实际应用中,不必对效用矩阵的每个空白元素进行预测。如此相反,只要找出每行中某些评级可能较高的元素即可。大部分应用中,推荐系统并不为用户提供所有项的一个排序,而是将一些用户理应评价较高的项推荐给他们。系统甚至不必寻找具有最高期望评分值的那些项,而只要找到它们的一个较大子集即可。
1.2长尾现象
推荐系统的必要性:长尾现象
实体递送系统的主要特点是缺乏资源,如货架有限,而在线商店能显示任何可用商品给顾客。
如通常情况下,书店会列出最畅销的基本书,而报社只会印刷那些他们认为大部分读者会感兴趣的文章。
物理世界和在线世界的差别被称为长尾现象,下图中纵坐标代表流行度(某个项被选择的次数),而所有项按照流行度在横坐标上排序。
物理机构只列出了图中竖线左边的最流行项,而相应的在线机构则会提供全范围的项。长尾现象要求在线机构必须对每个用户进行推荐。

1.3效用矩阵的填充
效用矩阵的数据的获取往往十分困难

,目前有两种一般的方法用于发现用户对项的评级结果。
其一:邀请用户对项评级。遗憾的是这种方法效果有限,而且通常用户不愿意提供反馈,因此最终得到的信息也会由于它们主要来自那些愿意反馈的用户而带有偏向性。

其二:根据用户的行为来推理。如用户在淘宝购买了某个产品,或者在优酷上看了某个电影,或者阅读了一篇关于苍井
空

的新闻报道,那么就有理由认为用户“喜欢”这些项。在这里评级结果只有一个值,就是1,表示用户喜欢。这种
数据下的效用矩阵会把用户未购买或者浏览产品表示为0,而不是空白。然而0这里并不是比1低一个级别,而是根本没有
评级。更一般的,如果淘宝的某个亲浏览了某宝贝,也会认为这位亲对这件宝贝感兴趣,即使没有购买。
2.基于内容的推荐
2.1项模型
项模型由一些项特征构成。有时可能需要人工录入。如
电影{电影中明星的集合(maybe用户是追星族),导演(maybe用户是导演控),年派(比如用户可能喜欢色戒那个年代
的戏),流派(喜剧,爱情等)}
电视机{屏幕尺寸,机壳颜色等}
歌曲{演唱者,作曲,流派等}
2.2文档的特征发现
有些类型的特征取值不会立即显现,如文档类和图像集。
文档推荐的场景:新闻报道很多,不可能都阅读,如何区分文档主题;互联网有大量的文档集合,推荐用户想看的网页;
把博客按照主题分类,推荐博客给感兴趣的用户。
如何从文档中找到能刻画主题的关键字呢?

去掉大概几百个停用字-->对剩余的词,计算它们在文档中的TF.IDF值-->那些具有最高TF.IDF得分的n个词作为文档的
关键特征。
何为TF.IDF?
事实上,文档中描述主题的词语往往相对罕见。但并非所有罕见词在做指示词时都同样重要。度量给定词在少数文档中
反复出现程度的形式化指标称TF.IDF(TF是词项频率,Term Frequency,IDF是逆文档频率,Inverse Document
Frequency,
TF.IDF表示词项频率乘以逆文档频率)。
假定文档集由N篇文档,fij为词项i在文档j中出现的频率,于是,词项i在文档j中的词频频率TFij定义为
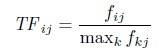
,相当于做了归一化处理,通过fij除以同一文档中出现次数最多的词项的频率。最大为1
假定词项i在文档集的ni篇文档中出现过,那么词项i的IDF定义为:

,于是乎,词项i在文档j中的得分被定义为TFij*IDFi,具有最高TF.IDF得分的那些词项通常都是
刻画文档主题的最佳词项。例如,假定文档集有2的20次方=1048 576篇文档,假定词语w在其中2的10次方= 1024篇文档
中出现,那么IDFw=log2(1048 576/ 1024)=10;考虑一篇文档j,w在该文档中出现20次,这也是文档当中出现的最多的词。
那么TFwj=1,于是w在文档j中的TF.IDF得分为10。
假定在文档k中,词语w出现1次,该文档中任一词语最多出现20次,于是TFwk=0.05,w在文档k中的TF.IDF得分为0.5。
现在文档都可以表示成词的集合。我们期望这些词可以表达文档的主题或者主要思想。
例如在一篇新闻报道中,期望具有最高TF.IDF的词包括文章中讨论的人名,所描述的事件的独特属性和事件发生地点。
如何计算两篇文档的相似度?
其一:文档词集合之间的Jaccard距离。
集合的Jaccard距离 d(x,y)=1-SIM(x,y),即1减去x,y的交集与并集的比例。
其二:将文档词集合看成向量,计算向量之间的余弦距离。
两个点的余弦距离实际上是点所代表的向量之间的夹角。在0-180度之间。
例如:x=[1,2,-1],y=[2,1,1],则内积x点乘y=1*2+2*1-1*1=3。两个向量的长度均为根号6,x与y的夹角余弦为3/(根号6*根号6)=1/2,
因此余弦距离为60度。
将具有高TF.IDF得分的词语集合想象成向量,其中每个分量对应每个可能的词。如果集合中包含某个词则对于向量分量为1,否则为0。
由于两篇文档中出现的词语集合有限,因此向量本身的高纬度对于计算来说没有太大的影响。
2.3基于Tag的项特征获取
图像数据库特征如何获取?
图像的数据通常有像素数数组构成,而这些数据无法给出任何有关他们的特征信息。
通过邀请用户采用词语或短语对图像进行标记,那么就可以从这些标记中获得有关图像特征的信息。
第一个试图标记大量数据的网站是 https://delicious.com/ 中文版是美味书签 http://meiweisq.com/
上述用于特征发现的标记过程在于,只有用户愿意不厌其烦的构造标签时上述过程才有效,并且标签的数量也要足够大以保证偶然
的错误标签不会造成太大的影响。
2.4项模型的表示
基于内容的推荐中,我们的最终目标是构建由特征-值对构成的项模型,并基于效用矩阵中的每一行构建反应用户偏好的用户模型。
对于离散值的特征集合,容易

:如电影的一个特征是其中的影星集合,假设对于每个明星都有一个元素,一单某个明星在电影
中出现则对应元素设为1,否则为0。同样,对于导演和流派特征
对于数值型特征,不太容易

:如电影的平均评分值作为一个特征,而该平均值是一个实数。将每个可能的平均值作为一个元素
木有意义。数值特征可以在项表示向量中通过单个分量来表示,这些分量中存放的是特征的真实值。
其实,应该对非布尔型元素进行恰当的放缩变换,从而使得它们即不完全主导计算过程也不完全无关。
例2.2假定电影的唯一特征,包括明星集合和平均评级得分。考虑两部分别包含5个明星的电影,其中两个明星同时出现在两部电影中。
另外一个电影的平均评分是3,另一个是4。两个向量看起来如下:

但是理论上还有无穷多个额外元素,对这两个向量都表示为0,其中每个元素代表两部电影中的明星之外的一个可能明星,但是who care?
上述两个向量的夹角余弦为

如果a取1,也就是直接取平均评分的真实值,那么上述结果是0.816。
如果a取2,那么余弦值为0.940。此时比a取1时更接近。
如果a取1/2,余弦值为0.619,即两个向量看上去很不同。
我们无法确定到底哪一个a取值是对的,但是,数值特征放缩因子的取值会影响最后关于项相似度的决定。
2.5用户模型
不仅要为项建立向量表示,也需要将用户的偏好表示成同一空间下的向量。
效用矩阵的每个非空元素可以代表用户购买过该项(表示为1)或者类似关系,也可以是表示用户对项的评分或者喜好程度的一个数值。
1)基于对用户兴趣的预测结果,为在线报纸的读者提供新闻报道;
2)基于顾客过去的购物和/或商品搜索历史,为在线零售商的顾客推荐他们可能想要买的商品。
推荐系统可以分成两大类:
1)基于内容的系统(Content-base System)主要考察的是推荐项的性质。例如,如果一个Netflix的用户观看了许多西部牛仔片,那么系统就会将数据库中属于“西部牛仔”类的电影推荐给该用户。
2)协同过滤系统(Collaborative System)主要通过计算相似度来推荐项。与某用户A相似的用户B所喜欢的项会推荐给用户A。
1 一个推荐系统模型
1.1效用矩阵
推荐系统应用当中,存在两类元素,一类是用户(user),另一类是项(item)。用户会偏爱某些项,这偏好信息必须要从数据中梳理出来。
数据本身可以表示成一个效用矩阵(utility matrix),该矩阵的每个(用户,项)所对应的元素值代表的是当前用户对当前项的喜好程度。
喜好程度值来自一个有序集合。假设该矩阵是稀疏的,即大部分元素都未知,未知意味着我们对当前用户对当前项的喜好信息不清楚。
例1.1 效用矩阵的例子,该矩阵代表用户对电影的评级(1-5级,5最高)结果。空白表示当前用户对当前电影没有评分。
用户分别用大写字母A,B,C和D表示。
大部分(用户,电影)对应的元素是空白,意味着用户并没有对电影进行评级。实际上,该矩阵可能更稀疏,因为用户只对所有电影的极小一部分进行了评级。
推荐系统的目标就是预测效用矩阵的空白元素。我们会问,用户A是否喜欢SW2?
思路1:我们在设计推荐系统的时候可以考虑电影的属性,比如制片人,导演,明星或者它们名字之间的相似度。发现SW1和SW2之间的相似性,从而由于A不喜欢SW1,得出A不太可能喜欢SW2的结论。
思路2:如果有多得多的数据,我们会注意到,给SW1和SW2同时评级的用户倾向于给这两者相相似的评级结果。于是,认为与A给SW1差评类似,也会给SW2一个差评。
在实际应用中,不必对效用矩阵的每个空白元素进行预测。如此相反,只要找出每行中某些评级可能较高的元素即可。大部分应用中,推荐系统并不为用户提供所有项的一个排序,而是将一些用户理应评价较高的项推荐给他们。系统甚至不必寻找具有最高期望评分值的那些项,而只要找到它们的一个较大子集即可。
1.2长尾现象
推荐系统的必要性:长尾现象
实体递送系统的主要特点是缺乏资源,如货架有限,而在线商店能显示任何可用商品给顾客。
如通常情况下,书店会列出最畅销的基本书,而报社只会印刷那些他们认为大部分读者会感兴趣的文章。
物理世界和在线世界的差别被称为长尾现象,下图中纵坐标代表流行度(某个项被选择的次数),而所有项按照流行度在横坐标上排序。
物理机构只列出了图中竖线左边的最流行项,而相应的在线机构则会提供全范围的项。长尾现象要求在线机构必须对每个用户进行推荐。
1.3效用矩阵的填充
效用矩阵的数据的获取往往十分困难
,目前有两种一般的方法用于发现用户对项的评级结果。
其一:邀请用户对项评级。遗憾的是这种方法效果有限,而且通常用户不愿意提供反馈,因此最终得到的信息也会由于它们主要来自那些愿意反馈的用户而带有偏向性。
其二:根据用户的行为来推理。如用户在淘宝购买了某个产品,或者在优酷上看了某个电影,或者阅读了一篇关于苍井
空
的新闻报道,那么就有理由认为用户“喜欢”这些项。在这里评级结果只有一个值,就是1,表示用户喜欢。这种
数据下的效用矩阵会把用户未购买或者浏览产品表示为0,而不是空白。然而0这里并不是比1低一个级别,而是根本没有
评级。更一般的,如果淘宝的某个亲浏览了某宝贝,也会认为这位亲对这件宝贝感兴趣,即使没有购买。
2.基于内容的推荐
2.1项模型
项模型由一些项特征构成。有时可能需要人工录入。如
电影{电影中明星的集合(maybe用户是追星族),导演(maybe用户是导演控),年派(比如用户可能喜欢色戒那个年代
的戏),流派(喜剧,爱情等)}
电视机{屏幕尺寸,机壳颜色等}
歌曲{演唱者,作曲,流派等}
2.2文档的特征发现
有些类型的特征取值不会立即显现,如文档类和图像集。
文档推荐的场景:新闻报道很多,不可能都阅读,如何区分文档主题;互联网有大量的文档集合,推荐用户想看的网页;
把博客按照主题分类,推荐博客给感兴趣的用户。
如何从文档中找到能刻画主题的关键字呢?
去掉大概几百个停用字-->对剩余的词,计算它们在文档中的TF.IDF值-->那些具有最高TF.IDF得分的n个词作为文档的
关键特征。
何为TF.IDF?
事实上,文档中描述主题的词语往往相对罕见。但并非所有罕见词在做指示词时都同样重要。度量给定词在少数文档中
反复出现程度的形式化指标称TF.IDF(TF是词项频率,Term Frequency,IDF是逆文档频率,Inverse Document
Frequency,
TF.IDF表示词项频率乘以逆文档频率)。
假定文档集由N篇文档,fij为词项i在文档j中出现的频率,于是,词项i在文档j中的词频频率TFij定义为
,相当于做了归一化处理,通过fij除以同一文档中出现次数最多的词项的频率。最大为1
假定词项i在文档集的ni篇文档中出现过,那么词项i的IDF定义为:
,于是乎,词项i在文档j中的得分被定义为TFij*IDFi,具有最高TF.IDF得分的那些词项通常都是
刻画文档主题的最佳词项。例如,假定文档集有2的20次方=1048 576篇文档,假定词语w在其中2的10次方= 1024篇文档
中出现,那么IDFw=log2(1048 576/ 1024)=10;考虑一篇文档j,w在该文档中出现20次,这也是文档当中出现的最多的词。
那么TFwj=1,于是w在文档j中的TF.IDF得分为10。
假定在文档k中,词语w出现1次,该文档中任一词语最多出现20次,于是TFwk=0.05,w在文档k中的TF.IDF得分为0.5。
现在文档都可以表示成词的集合。我们期望这些词可以表达文档的主题或者主要思想。
例如在一篇新闻报道中,期望具有最高TF.IDF的词包括文章中讨论的人名,所描述的事件的独特属性和事件发生地点。
如何计算两篇文档的相似度?
其一:文档词集合之间的Jaccard距离。
集合的Jaccard距离 d(x,y)=1-SIM(x,y),即1减去x,y的交集与并集的比例。
其二:将文档词集合看成向量,计算向量之间的余弦距离。
两个点的余弦距离实际上是点所代表的向量之间的夹角。在0-180度之间。
例如:x=[1,2,-1],y=[2,1,1],则内积x点乘y=1*2+2*1-1*1=3。两个向量的长度均为根号6,x与y的夹角余弦为3/(根号6*根号6)=1/2,
因此余弦距离为60度。
将具有高TF.IDF得分的词语集合想象成向量,其中每个分量对应每个可能的词。如果集合中包含某个词则对于向量分量为1,否则为0。
由于两篇文档中出现的词语集合有限,因此向量本身的高纬度对于计算来说没有太大的影响。
2.3基于Tag的项特征获取
图像数据库特征如何获取?
图像的数据通常有像素数数组构成,而这些数据无法给出任何有关他们的特征信息。
通过邀请用户采用词语或短语对图像进行标记,那么就可以从这些标记中获得有关图像特征的信息。
第一个试图标记大量数据的网站是 https://delicious.com/ 中文版是美味书签 http://meiweisq.com/
上述用于特征发现的标记过程在于,只有用户愿意不厌其烦的构造标签时上述过程才有效,并且标签的数量也要足够大以保证偶然
的错误标签不会造成太大的影响。
2.4项模型的表示
基于内容的推荐中,我们的最终目标是构建由特征-值对构成的项模型,并基于效用矩阵中的每一行构建反应用户偏好的用户模型。
对于离散值的特征集合,容易
:如电影的一个特征是其中的影星集合,假设对于每个明星都有一个元素,一单某个明星在电影
中出现则对应元素设为1,否则为0。同样,对于导演和流派特征
对于数值型特征,不太容易
:如电影的平均评分值作为一个特征,而该平均值是一个实数。将每个可能的平均值作为一个元素
木有意义。数值特征可以在项表示向量中通过单个分量来表示,这些分量中存放的是特征的真实值。
其实,应该对非布尔型元素进行恰当的放缩变换,从而使得它们即不完全主导计算过程也不完全无关。
例2.2假定电影的唯一特征,包括明星集合和平均评级得分。考虑两部分别包含5个明星的电影,其中两个明星同时出现在两部电影中。
另外一个电影的平均评分是3,另一个是4。两个向量看起来如下:
但是理论上还有无穷多个额外元素,对这两个向量都表示为0,其中每个元素代表两部电影中的明星之外的一个可能明星,但是who care?
上述两个向量的夹角余弦为
如果a取1,也就是直接取平均评分的真实值,那么上述结果是0.816。
如果a取2,那么余弦值为0.940。此时比a取1时更接近。
如果a取1/2,余弦值为0.619,即两个向量看上去很不同。
我们无法确定到底哪一个a取值是对的,但是,数值特征放缩因子的取值会影响最后关于项相似度的决定。
2.5用户模型
不仅要为项建立向量表示,也需要将用户的偏好表示成同一空间下的向量。
效用矩阵的每个非空元素可以代表用户购买过该项(表示为1)或者类似关系,也可以是表示用户对项的评分或者喜好程度的一个数值。

相关文章推荐
- 斯坦福大学(吴恩达) 机器学习课后习题详解 第九周 推荐系统
- 推荐系统 - 2 - 离线指标和其他指标
- 斯坦福大学(吴恩达) 机器学习课后习题详解 第九周 编程题 异常检测与推荐系统
- 推荐系统(三) —— 利用用户行为数据 —— 隐语义模型
- 一个Spark推荐系统引擎的实现
- 推荐系统中的矩阵分解
- Hadoop (HDFS)分布式文件系统基本操作 推荐
- 推荐系统之UserCF2:用户对商品的感兴趣程度
- 推荐款免费的cms系统 MemHT Portal
- 虚拟机系统的磁盘扩容妙招及案例 推荐
- 推荐系统——协同过滤学习
- 一页纸说清楚“什么是推荐系统”
- 推荐系统中常用算法 以及优点缺点对比
- 基于Mahout的电影推荐系统
- 《推荐系统》基于标签的用户推荐系统
- IBM XIV--存储系统架构的又一次革命? 推荐
- 强烈推荐国内首款大型免费e-Learning教学培训管理系统-ZLMS,集成实时视频课堂功能
- 《推荐系统实践》阅读笔记五 推荐系统的构成和评价标准
- 文章推荐系统(二)
- 实用推荐:12款Linux系统恢复工具