VMware vSphere 5.1 群集深入解析(三)
2013-04-05 00:40
369 查看
VMware vSphere5.1Clustering DeepdiveHA.DRS.Storage DRS.Stretched Clusters Duncan Epping &Frank Denneman Translate By Tim2009 / 翻译:Tim2009 目录版权关于作者知识点前言第一部分 vSphere高可用性第一章 介绍vSphere高可用性第二章 高可用组件第三章 基本概念第四章 重新启动虚拟机第五章 增加高可用灵活性(网络冗余)第六章 访问控制第七章 虚拟机和应用监控第八章 集成第九章 汇总第二部分 vSphere分布式资源调度第一章 vSphere DRS介绍第二章 vMotion和EVC第三章 DRS动态配额第四章 资源池与控制第五章 DRS计算推荐第六章 DRS推荐向导第七章 DPM介绍第八章 DPM计算推荐第九章 DPM推荐向导第三部分 vSphere存储DRS第一章 vSphere存储DRS移介绍第二章 存储DRS算法第三章 存储I/O控制第四章 数据存储配置第五章 数据存储架构与设计第六章 对存储vMotion的影响第七章 关联性第八章 数据存储维护模式第九章 总结汇总第四部分 群集架构的扩展第一章 群集架构的扩展第二章 vSphere配置第三章 故障排错第四章 总结汇总第五章 附录 第三章 基本概念现在你已经了解了HA的相关组件,现在来讨论下HA群集的一些基本概念:
主/备代理
心跳
隔离 vs 网络分区
虚拟机状态保护
搭建过vSphere的人都知道群集内可以包括多个主机,群集能够很好的收集资源信息,资源可以被vSphere的DRS(资源动态分布功能)划分到不同的资源池中,或者用来增加HA的可靠性。
在vSphere 5.0中,涉及到HA的很多地方都有更改,例如,使用一个HA群集包括两种类型的节点,节点可以是一个主节点,一个次节点,并允许群集扩展到32台主机,这个概念是依赖于AAM,FDM已经完全改变了这个游戏规则,并删除了整个概念的主要和次要节点。(更详细的(AAM)节点机制,我们请您去查看《vSphere 4.1 HA and DRS Technical Deepdive》,在http://virtualbox.blog.51cto.com/531002/1127451这里也对vSphere 4.1的HA机制进行了描述)
另一个非常重要的设计是关于主HA节点,也就是说,每个群集最大5个主节点,这些节点是HA实现的核心,发生故障时至少有一个主节点能继续工作,否则虚拟机不可能重新启动,从体系结构来看,至少有一个驱动程序需要被重新写入HA。
在vSphere 5.0架构中介绍了主/备的HA agent,除开网络分区域,我们等下讨论,这里群集中只有一个主HA agent,其它的agent都可以作为主HA agent,主agent负责监控虚拟机的健康状况,如果虚拟机出现故障就重新启动它,备的HA agent负责转发主HA agent的信息,并重新启动主HA agent指定的虚拟机。还有另外一个关于HA agent的改动,无论作为主HA agent还是备agent,都具备虚拟机/app的监控功能,类似AAM的功能,是vpxa功能的一部分。
主agent如前所述,主agent主要负责跟踪虚拟机的状态,在适当的时候采取行动。在正常的情况下,一个群集里只有一个主agent,我们接下来也会讨论一个集群中存在多个主agent的场景,但现在我们来谈谈一个群集一个主agent的情况,主会负责声明虚拟机的配置数据文件的“所有权“。
基本设计原则
为了最大限度的在出现故障时增加虚拟机的启动机会,我们建议屏蔽群集上的不相关的数据存储,尽管共享存储可以在不同的群集中提供服务,但从管理角度来说会增加架构的复杂度。
这不是全部的职责,HA master还负责与vCenter交换状态信息,这意味着,它不仅可以接收,还可以反馈信息给vCenter,当主机出现故障,HA master会启动主机上的虚拟机,你可能马上想问,当master故障时发生了什么,或者通俗的说,哪一个主机将会成为master,是在什么时候发生的?
选举
每当agent不能在网络中与master联系上,一组HA agents就会去选举出master,当群集首次启用HA或者当群集内有已经运行的主机时,master选举由此发生:
故障
网络划分或者隔离
与vCenter Server的连接断开
当HA重新配置时
HA的选举大约需要15秒,使用UDP协议,当在选举的时候,HA不会对故障做出反应,一旦master选举出来,将检测处理选举之前和选举期间的故障,选举的过程简单但强大,
能够连接上共享数据存储的主机都可能被选中成为master,如果两个或者更多个主机连接着同样数量的共享数据存储,有最高Managed Object Id的会被选中,对于某个主机,主机的HA状态将显示在“摘要“选项卡,这包括如图7所示的作用,其中主机为master主机。
当master被选举出来,每个slave在管理网络中建立一个安全、加密、TCP协议连接到master,这个连接是基于SSL的,在这里强调一件事,当主选出时,除非重新需要选择master,否则slaves不互相通信。
图7:master agent

如前所述,Master当选时,它会尝试获取所有的数据存储,它可以直接访问或者通过代理连接上slave,它通过锁定一个现有集群的数据存储上的一个文件称为“protectedlist“,Master将尝试使用自己的权限,发现网络中的任何数据存储,它会定期重试,知道它没有该权限。
文件路径
/<root of datastore>/.vSphere-HA/<cluster-specific-directory>/protectedlist
<cluster-specific-directory>建立
<uuid of vCenter Server>-<number part of the MoID of the cluster>-<random 8 char string>-<name of the host running vCenter Server>
master使用存放在目录中的protectedlist文件,用它来追踪HA保护的虚拟机,把它叫做目录可能有些夸张,它存放着受保护的虚拟机列表,它包含着虚拟机的CPU预留及内存开销信息,master可以访问群集上所有的虚拟机的信息,图8是一个数据存储的清单文件
图8 protectedlist

现在我们知道master锁定一个文件在数据存储上,这个文件存储着目录清单的详细信息,当主机被隔离或者发生故障时会发生什么列?如果master故障,答案很简单,锁定的文件将会过期无效,新的master将会在数据存储上锁定新的文件。
如果master被隔离,这种情况略有不同,虽然结果是类似的。
master将解除锁定,以确保选举出新的master,它能够使得HA保护的虚拟机读取到该文件,如果master在某一时刻出现故障,它将会被孤立,虚拟机的重新启动也会被延迟,只道选出新的master,在类似这样的一个场景里,准确的重新启动虚拟机比短暂的延迟更重要。
让我们假设一下master只是发生故障,接下来将会发生什么,slaves怎样知道master发生故障,vSphere 5.0使用网络的点对点心跳检测机制,如果slaves在网络中没有收到了master发出的心跳信息,slaves将会选举出新的master,新的master将读取所需信息,将会在10秒内执行虚拟机的重新启动,更多的过程我们将在第四章节讨论。
重新启动虚拟机并非master的唯一职责,它还负责slaves主机的状态监控和报告这种状态到vCenter,如果slave出现故障或者与管理网络孤立,master将决定哪些虚拟机必须要重新启动,当虚拟机重新启动,master还负责确定虚拟机的分布位置,它使用一个布局引擎,会尽量把重新启动的虚拟机均匀的分布在所有可用的主机上。
所有这方面的责任都非常重要,但没有机制来检测slave的故障,那么master也是起不到作用的,就像slave从master接收检测信号,master从slave接收检测信号,这样他们就知道彼此活着。
slavesslaves相对master责任大幅减少,slave监视正在运行的虚拟机,并把这个状态告诉master
slave还会通过心跳检测来检测master的健康状况,如果master变得不可用,slave将会发起和参与master的选举,最后,slave将会发送心跳检测给master,使得master和slave之间正常通信。所有的通信都是点对点方式,而非多播方式。
图9:slave agent

master和slave用到的文件不光是存储状态,并且可以作为一种沟通机制,我们已经看到protectedlist文件(图8),用来存储受保护的虚拟机列表,现在,我们将讨论master和slave所建立的文件,远程文件是存储在共享存储上,本地文件是直接存储在主机上。
Remote Files
每个开启的虚拟机在每个主机上存储着“poweron”文件,(图8可以看到),应该指出的是,因为master也承载着虚拟机,它同样会创建一个“poweron”文件
这个文件的命名方案如下:
host-<number>-poweron
“poweron”文件不只是用来跟踪虚拟机的电源接通状态,这个文件还被slave用来在管理网络隔离时通知maste信息,最上面一行表示0或者1,A 0表示没有隔离,A 1表示隔离,master将会告诉vCenter主机隔离的信息。
本地文件
正如前面提到的,主机的HA在配置时,主机将存储所在群集的相关信息。
图10 :本地存储信息

每个主机,包括master,都将数据存储在本地,本地存储的数据中有很重要的状态信息,也就是说,包括虚拟机到主机的兼容性矩阵、群集配置信息和主机成员名单,此信息保存在本地的每个主机上,更新的信息将由vCenter发送到每个master上,并由master发送给slaves,警告我们希望你们最好不要去碰这些文件——我们强烈建议您不要对其进行修改,我们将解释它们是如何使用的。
clusterconfig-这个文件是直接可读文件,它包括了集群的详细配置信息
vmmetadata(5.1或者更高)或compatlist(5.0)-这个不是直接可读文件,它包括HA所保护的虚拟机的兼容性信息矩阵,该清单是主机和虚拟机的兼容词典
fdm.cfg-此文件包含着配置设置的记录,例如,记录日志和系统日志的详细信息都存储在这里
hostlist-群集中的主机列表,包括主机名,IP地址,MAC地址,和心跳数据。
心跳检测
我们已经在这一章节提到过几次,这个重要的机制值得我们了解:心跳检测,心跳检测时HA用来检测master是否活着的机制,vSphere 5.0关于心跳检测的介绍,不仅没有对心跳检测有大的改动,另外还添加了心跳检测机制的介绍,首先让我们讨论下传统网络的信号检测。
网络心跳检测
在vSphere 5.0介绍中众所周知的心跳检测有了一些改变,vSphere 5.0不再使用主要和次要节点的概念,也没有数以百计的心跳组合,在vSphere 5.0中,每个slave将会发送一个心跳,master则发送心跳给每个slave,这是点对点的通信,对比vSphere 4.1或者更早期的多播都已经不再使用,这些心跳在默认情况下每秒发送一次。
当slave接收不到任何来自master的心跳,它会尝试判断master是否被隔离,我们也将会在本章讨论更详细的“状态”信息。
基本设计原则
网络检测信号是确定主机状态的关键,确保管理网络的高度灵活性,以保证正确的状态信息。
数据存储心跳
在vSphere 5.0之前,大家都知道,管理网络被隔离,虚拟机会一直尝试重新启动,但虚拟机实际仍然在主机上正常启动,这样给主机带来了不必要的压力。而数据存储心跳的引入,可以缓解这个压力,以增加HA的弹性,防止不必要的重新启动尝试。
数据存储检测信号使主更加正确地判断管理网络主机不可达的状态。新的数据存储心跳机制不仅仅在master和slaver网络断开的情况下使用,数据存储心跳机制无论在主机故障还是网络分区/隔离的情况下生效。通过“poweron”文件,隔离将被确认,正如前面所说,当主机被隔离的时候我们需要更新主机信息,如果没有“poweron”文件,就没有办法去验证隔离主机,所以这一点要清楚!在这两个文件的检测结果的基础上,master会采取适当的行动,如果master确定一台主机出现故障(无数据存储心跳),master将会重新启动故障主机上的虚拟机,如果master确定slave被隔离或者分区,它只会采取合适的行动,master开始出发隔离相应,重新启动断电/关闭的虚拟机,我们会在第4章中更详细的讨论这个。
默认情况下,HA会选择2个数据存储心跳——这个选出的的数据存储在所有的主机上有效,或者在尽可能多的主机上有效,虽然我们可能需要预先配置(das.heartbeatDsPerHost)来允许连接更多的数据存储,但我们建议默认配置应该满足大多数的情况,除了第四部分会讲到的扩展群集环境。
在选择存储过程中,推荐VMFS优先级高于NFS,并尽量选择不同的LUN或者NFS服务器进行数据备份,如果必要,你还可以自己选择心跳数据存储。然而,我们建议让vCenter来处理这项“包袱”,也就是说让vCenter使用选择算法来选择所有主机的心跳的数据存储,当然,不是所有的主机都可以被vCenter选择为心跳数据存储,只有那些vCenter可以识别的。在主机地理位置分散的情况下,建议手动选择心跳数据存储,以确保每一个站点至少有个本地站点的心跳数据存储,这种情况会在这本书的第四部分详细介绍。
基本设计原则
在城域集群/地理位置分散的群集,我们建议您设定的最小数量的心跳数据存储要到4个。建议为每个站点手动选择本地心跳数据存储。
图11:选择心跳数据存储
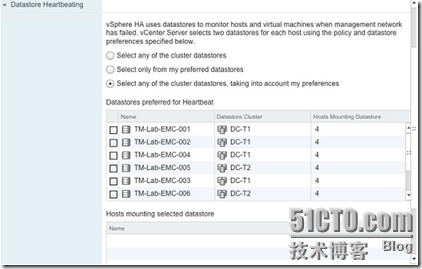
现在的问题就产生了,准确的说,这么多的数据存储,哪一个是用来检测此心跳信号列?让我们来回答,当数据存储第一次用于数据存储心跳时,我们这个时候看下图12,vSphere的Monitor监控中选项卡中显示了群集的广泛信息。例如心跳选项就显示了正使用那些心跳数据存储。
图12 确认心跳数据存储

心跳机制是怎样工作的了?在基于块的存储环境中HA利用现有的VMFS文件系统机制,该机制使用了所谓的“心跳区域”被更新,只要打开该文件。在VMFS数据存储,HA会简单地检查是否已更新的心跳地区。为了更新数据存储心跳区域,主机需要卷上至少有一个打开的文件。 HA确保有至少有一个文件打开此卷上创建一个文件,专门用于数据存储检测信号。换句话说,每一个主机文件被创建在所指定的检测信号数据存储,如在图13中示出。这个文件的的命名方案如下:
host-<number>-hb
图13 心跳文件

在NFS数据存储,每个主机将写每5秒一次心跳文件,确保该主机将能够检查主机的状态。master将只是通过验证检查时间戳的文件的改变。
要认识到,在一个聚合的网络环境的情况下,数据存储检测信号的有效性将取决于对故障的类型。例如,网卡故障可能会影响网络和数据存储检测信号。 无论出于何种原因,如果数据存储或NFS共享变得不可用,或从集群中删除,HA会检测到这一点,检测机制会选择一个新的数据存储或NFS共享。
基本设计原则
数据存储心跳增加了HA的弹性,但是不是最终目的,在网络环境中,由于使用数据存储检测心跳信号,一个网卡的故障可能会导致网络和存储都不可用。
隔离和分区对比
我们已经简要的谈到过它,现在我们来仔细看这个问题,在vSphere 5.0的HA中,一个新的群集节点可以被称为存在分区,怎样准确的说是一台主机是分区而不是隔离?在此之前我们会解释,管理员会观察master报告的状态信息以及特征信息
首先,从管理员的角度来看,两个主机被认为划分了区域,如果他们可以操作,但是管理网络不可达,此外,一台主机是隔离的,不能被HA管理网络上的检测包发现,IP地址被隔离也不能ping通。也有可能这这一时间多台主机被分离,这就是我们所说的主机被分开,但它们之间的管理网络可以通信,网络分区可能会设计到两个以上的分区,但通常这种情况很少。
现在,从FDM的角度考虑,当任何一个FDM不能再网络中联系上master,它们会选举出新的master,所以,当网络的分区存在,选举将会发生,这样当主机发生故障或者网络被隔离时,才会对受影响的虚拟机采取适当的行动,图14西南是了隔离和分区会出现的可能方式。
图14 隔离对比分区
如果群集分区为多个子网,每个分区都选举出自己的master,意思是如果你有4个网络分区,你就有4个master,如果网络划分区分正确,4个分区都能起到接管群集的作用,应该指出的是master可以要求负责不同分区的虚拟机,如果发生这种情况,虚拟机出现故障,master将通过数据存储心跳接收到相关信息。
在HA架构中,无论主机是否分区,master都要报告相关情况,所以,在上面的例子中,host ESXi-01上的master将要报告ESXi03和ESXi04的分区,同时host04上的master也将要报告ESXi01和ESXi02的分区,当分区发生,vCenter将依照准则报告给其中一个master。
一个master无法通过管理网络与主机通信,它会报告该主机被分区或者隔离,主机通过数据存储管道到该主机的数据存储心跳,master不能单独区别这两种孤立和隔离状态,只有主机主动告诉master它被隔离。
这里就留下一个问题,当出现故障,master怎样区分主机是被分区还是隔离?
当master停止从slave接收网络心跳,它会检查主机在接下来15S的活跃度,在宣布主机出现故障之前,如果主机已经出现故障或没有检测到活动状态,主机将进行验证,首先,主机是否仍然进行数据存储心跳,其次,master会ping管理网络的主机IP地址,如果两项都否定,那么宣布主机出现故障,这并不意味着主机PSOD’ed,它可能是网络不可用,包括存储网络,从管理员的角度来看主机隔离了,但不是从HA的角度,正如你所想到的,但是,也有各种其它“组合”的可能,下表就描述了这些组合的状态信息。
表2 主机状态
HA会基于主机的各种状态触发行动,当主机标记为故障,将发起重新启动虚拟机的操作,当主机被标记为隔离,master会被重新选举。正如前面所提到的,当重新启动时这是相对vSphere 5.0之前版本的很大的一个改变,无论虚拟机或者主机的状态,一件事要记住,隔离响应是指,当隔离主机知道有个master,虚拟机将被关闭或者断电时,或者当隔离主机失去访问数据存储的虚拟机,它就有了虚拟机的所有权。
例如,如果一个主机上运行两台虚拟机,这两个虚拟机在不同的数据存储上,当主机被隔离后,主机将验证它是否可以访问这两台虚拟机的数据存储,如果可以,主机将验证master是否拥有这些数据存储,如果master不拥有这些数据存储,隔离响应将不被触发,将不会采取重新启动,如果主机不能访问数据存储,例如,在所有路径都断开的情况下,HA会触发隔离响应,以确保“原始”的虚拟机断电并安全的重启,这样做就可以避免“脑裂”splite-brain
重申的是,对比之前所有版本中的HA,这是一个很重大的变化,当master检测到主机故障或者被隔离,群集中其它的主机将仅仅收到重新启动虚拟机的需求,并且触发隔离响应,如果对隔离响应还不是很理解,不用担心,我们将在第四章深入讨论。
虚拟机保护
vSphere 5.0中虚拟机的保护方式已发生了重大的改变,在vSphere5.0版本之前,虚拟机保护使用VPXA同时通过VPXA的模块vmap通知AAM,在vSphere5.0中,虚拟机保护有好几层,但基本上是vCenter来负责,我们解释这个比较简单,但我们希望这块能够扩展更详细,以保证vCenter在保护虚拟机时,每个人都能够理解虚拟机对vCenter的依赖,我们想强调,这只适合保护虚拟机;虚拟机的重启什么都不需要vCenter。
当虚拟机的状态发生改变,vCenter将指挥master启用或者关闭对虚拟机的HA保护,不管怎样,只是当master承若过的磁盘状态发生改变时才保护。原因是这样的,当然,master故障会导致已存在内存的状态信息损坏,正如前面所指出的,这种状态存储在数据存储的“protectedlist”文件中。
当虚拟机的电源状态改变时,master将会告诉vCenter,这样用户就可以看见虚拟机的状态改变,也为其它程序如监控工具提供信息。
要澄清的是,我们保护虚拟机的工作流(图15)是通过vCenter来创建的。
图15 虚拟机保护流程

但是什么叫“解除保护”?当一个虚拟机的电源关闭,它将会从protectedlist中移除,我们在图16中证明了该工作流程。
图16 虚拟机接触保护工作流
本文出自 “virtualbox” 博客,请务必保留此出处http://virtualbox.blog.51cto.com/531002/1171256
主/备代理
心跳
隔离 vs 网络分区
虚拟机状态保护
搭建过vSphere的人都知道群集内可以包括多个主机,群集能够很好的收集资源信息,资源可以被vSphere的DRS(资源动态分布功能)划分到不同的资源池中,或者用来增加HA的可靠性。
在vSphere 5.0中,涉及到HA的很多地方都有更改,例如,使用一个HA群集包括两种类型的节点,节点可以是一个主节点,一个次节点,并允许群集扩展到32台主机,这个概念是依赖于AAM,FDM已经完全改变了这个游戏规则,并删除了整个概念的主要和次要节点。(更详细的(AAM)节点机制,我们请您去查看《vSphere 4.1 HA and DRS Technical Deepdive》,在http://virtualbox.blog.51cto.com/531002/1127451这里也对vSphere 4.1的HA机制进行了描述)
另一个非常重要的设计是关于主HA节点,也就是说,每个群集最大5个主节点,这些节点是HA实现的核心,发生故障时至少有一个主节点能继续工作,否则虚拟机不可能重新启动,从体系结构来看,至少有一个驱动程序需要被重新写入HA。
在vSphere 5.0架构中介绍了主/备的HA agent,除开网络分区域,我们等下讨论,这里群集中只有一个主HA agent,其它的agent都可以作为主HA agent,主agent负责监控虚拟机的健康状况,如果虚拟机出现故障就重新启动它,备的HA agent负责转发主HA agent的信息,并重新启动主HA agent指定的虚拟机。还有另外一个关于HA agent的改动,无论作为主HA agent还是备agent,都具备虚拟机/app的监控功能,类似AAM的功能,是vpxa功能的一部分。
主agent如前所述,主agent主要负责跟踪虚拟机的状态,在适当的时候采取行动。在正常的情况下,一个群集里只有一个主agent,我们接下来也会讨论一个集群中存在多个主agent的场景,但现在我们来谈谈一个群集一个主agent的情况,主会负责声明虚拟机的配置数据文件的“所有权“。
基本设计原则
为了最大限度的在出现故障时增加虚拟机的启动机会,我们建议屏蔽群集上的不相关的数据存储,尽管共享存储可以在不同的群集中提供服务,但从管理角度来说会增加架构的复杂度。
这不是全部的职责,HA master还负责与vCenter交换状态信息,这意味着,它不仅可以接收,还可以反馈信息给vCenter,当主机出现故障,HA master会启动主机上的虚拟机,你可能马上想问,当master故障时发生了什么,或者通俗的说,哪一个主机将会成为master,是在什么时候发生的?
选举
每当agent不能在网络中与master联系上,一组HA agents就会去选举出master,当群集首次启用HA或者当群集内有已经运行的主机时,master选举由此发生:
故障
网络划分或者隔离
与vCenter Server的连接断开
当HA重新配置时
HA的选举大约需要15秒,使用UDP协议,当在选举的时候,HA不会对故障做出反应,一旦master选举出来,将检测处理选举之前和选举期间的故障,选举的过程简单但强大,
能够连接上共享数据存储的主机都可能被选中成为master,如果两个或者更多个主机连接着同样数量的共享数据存储,有最高Managed Object Id的会被选中,对于某个主机,主机的HA状态将显示在“摘要“选项卡,这包括如图7所示的作用,其中主机为master主机。
当master被选举出来,每个slave在管理网络中建立一个安全、加密、TCP协议连接到master,这个连接是基于SSL的,在这里强调一件事,当主选出时,除非重新需要选择master,否则slaves不互相通信。
图7:master agent

如前所述,Master当选时,它会尝试获取所有的数据存储,它可以直接访问或者通过代理连接上slave,它通过锁定一个现有集群的数据存储上的一个文件称为“protectedlist“,Master将尝试使用自己的权限,发现网络中的任何数据存储,它会定期重试,知道它没有该权限。
文件路径
/<root of datastore>/.vSphere-HA/<cluster-specific-directory>/protectedlist
<cluster-specific-directory>建立
<uuid of vCenter Server>-<number part of the MoID of the cluster>-<random 8 char string>-<name of the host running vCenter Server>
master使用存放在目录中的protectedlist文件,用它来追踪HA保护的虚拟机,把它叫做目录可能有些夸张,它存放着受保护的虚拟机列表,它包含着虚拟机的CPU预留及内存开销信息,master可以访问群集上所有的虚拟机的信息,图8是一个数据存储的清单文件
图8 protectedlist
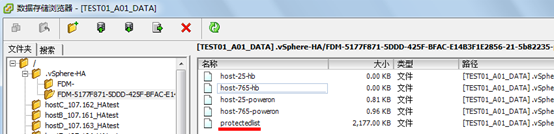
现在我们知道master锁定一个文件在数据存储上,这个文件存储着目录清单的详细信息,当主机被隔离或者发生故障时会发生什么列?如果master故障,答案很简单,锁定的文件将会过期无效,新的master将会在数据存储上锁定新的文件。
如果master被隔离,这种情况略有不同,虽然结果是类似的。
master将解除锁定,以确保选举出新的master,它能够使得HA保护的虚拟机读取到该文件,如果master在某一时刻出现故障,它将会被孤立,虚拟机的重新启动也会被延迟,只道选出新的master,在类似这样的一个场景里,准确的重新启动虚拟机比短暂的延迟更重要。
让我们假设一下master只是发生故障,接下来将会发生什么,slaves怎样知道master发生故障,vSphere 5.0使用网络的点对点心跳检测机制,如果slaves在网络中没有收到了master发出的心跳信息,slaves将会选举出新的master,新的master将读取所需信息,将会在10秒内执行虚拟机的重新启动,更多的过程我们将在第四章节讨论。
重新启动虚拟机并非master的唯一职责,它还负责slaves主机的状态监控和报告这种状态到vCenter,如果slave出现故障或者与管理网络孤立,master将决定哪些虚拟机必须要重新启动,当虚拟机重新启动,master还负责确定虚拟机的分布位置,它使用一个布局引擎,会尽量把重新启动的虚拟机均匀的分布在所有可用的主机上。
所有这方面的责任都非常重要,但没有机制来检测slave的故障,那么master也是起不到作用的,就像slave从master接收检测信号,master从slave接收检测信号,这样他们就知道彼此活着。
slavesslaves相对master责任大幅减少,slave监视正在运行的虚拟机,并把这个状态告诉master
slave还会通过心跳检测来检测master的健康状况,如果master变得不可用,slave将会发起和参与master的选举,最后,slave将会发送心跳检测给master,使得master和slave之间正常通信。所有的通信都是点对点方式,而非多播方式。
图9:slave agent

master和slave用到的文件不光是存储状态,并且可以作为一种沟通机制,我们已经看到protectedlist文件(图8),用来存储受保护的虚拟机列表,现在,我们将讨论master和slave所建立的文件,远程文件是存储在共享存储上,本地文件是直接存储在主机上。
Remote Files
每个开启的虚拟机在每个主机上存储着“poweron”文件,(图8可以看到),应该指出的是,因为master也承载着虚拟机,它同样会创建一个“poweron”文件
这个文件的命名方案如下:
host-<number>-poweron
“poweron”文件不只是用来跟踪虚拟机的电源接通状态,这个文件还被slave用来在管理网络隔离时通知maste信息,最上面一行表示0或者1,A 0表示没有隔离,A 1表示隔离,master将会告诉vCenter主机隔离的信息。
本地文件
正如前面提到的,主机的HA在配置时,主机将存储所在群集的相关信息。
图10 :本地存储信息
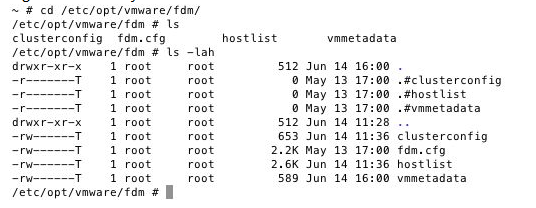
每个主机,包括master,都将数据存储在本地,本地存储的数据中有很重要的状态信息,也就是说,包括虚拟机到主机的兼容性矩阵、群集配置信息和主机成员名单,此信息保存在本地的每个主机上,更新的信息将由vCenter发送到每个master上,并由master发送给slaves,警告我们希望你们最好不要去碰这些文件——我们强烈建议您不要对其进行修改,我们将解释它们是如何使用的。
clusterconfig-这个文件是直接可读文件,它包括了集群的详细配置信息
vmmetadata(5.1或者更高)或compatlist(5.0)-这个不是直接可读文件,它包括HA所保护的虚拟机的兼容性信息矩阵,该清单是主机和虚拟机的兼容词典
fdm.cfg-此文件包含着配置设置的记录,例如,记录日志和系统日志的详细信息都存储在这里
hostlist-群集中的主机列表,包括主机名,IP地址,MAC地址,和心跳数据。
心跳检测
我们已经在这一章节提到过几次,这个重要的机制值得我们了解:心跳检测,心跳检测时HA用来检测master是否活着的机制,vSphere 5.0关于心跳检测的介绍,不仅没有对心跳检测有大的改动,另外还添加了心跳检测机制的介绍,首先让我们讨论下传统网络的信号检测。
网络心跳检测
在vSphere 5.0介绍中众所周知的心跳检测有了一些改变,vSphere 5.0不再使用主要和次要节点的概念,也没有数以百计的心跳组合,在vSphere 5.0中,每个slave将会发送一个心跳,master则发送心跳给每个slave,这是点对点的通信,对比vSphere 4.1或者更早期的多播都已经不再使用,这些心跳在默认情况下每秒发送一次。
当slave接收不到任何来自master的心跳,它会尝试判断master是否被隔离,我们也将会在本章讨论更详细的“状态”信息。
基本设计原则
网络检测信号是确定主机状态的关键,确保管理网络的高度灵活性,以保证正确的状态信息。
数据存储心跳
在vSphere 5.0之前,大家都知道,管理网络被隔离,虚拟机会一直尝试重新启动,但虚拟机实际仍然在主机上正常启动,这样给主机带来了不必要的压力。而数据存储心跳的引入,可以缓解这个压力,以增加HA的弹性,防止不必要的重新启动尝试。
数据存储检测信号使主更加正确地判断管理网络主机不可达的状态。新的数据存储心跳机制不仅仅在master和slaver网络断开的情况下使用,数据存储心跳机制无论在主机故障还是网络分区/隔离的情况下生效。通过“poweron”文件,隔离将被确认,正如前面所说,当主机被隔离的时候我们需要更新主机信息,如果没有“poweron”文件,就没有办法去验证隔离主机,所以这一点要清楚!在这两个文件的检测结果的基础上,master会采取适当的行动,如果master确定一台主机出现故障(无数据存储心跳),master将会重新启动故障主机上的虚拟机,如果master确定slave被隔离或者分区,它只会采取合适的行动,master开始出发隔离相应,重新启动断电/关闭的虚拟机,我们会在第4章中更详细的讨论这个。
默认情况下,HA会选择2个数据存储心跳——这个选出的的数据存储在所有的主机上有效,或者在尽可能多的主机上有效,虽然我们可能需要预先配置(das.heartbeatDsPerHost)来允许连接更多的数据存储,但我们建议默认配置应该满足大多数的情况,除了第四部分会讲到的扩展群集环境。
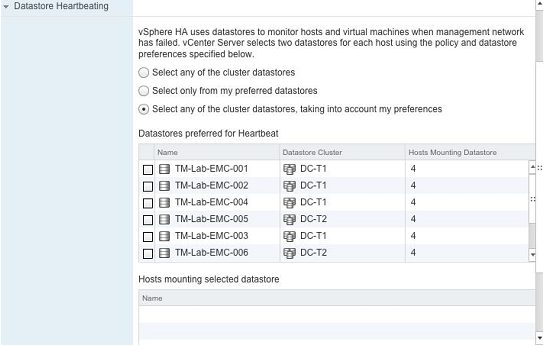
在选择存储过程中,推荐VMFS优先级高于NFS,并尽量选择不同的LUN或者NFS服务器进行数据备份,如果必要,你还可以自己选择心跳数据存储。然而,我们建议让vCenter来处理这项“包袱”,也就是说让vCenter使用选择算法来选择所有主机的心跳的数据存储,当然,不是所有的主机都可以被vCenter选择为心跳数据存储,只有那些vCenter可以识别的。在主机地理位置分散的情况下,建议手动选择心跳数据存储,以确保每一个站点至少有个本地站点的心跳数据存储,这种情况会在这本书的第四部分详细介绍。
基本设计原则
在城域集群/地理位置分散的群集,我们建议您设定的最小数量的心跳数据存储要到4个。建议为每个站点手动选择本地心跳数据存储。
图11:选择心跳数据存储
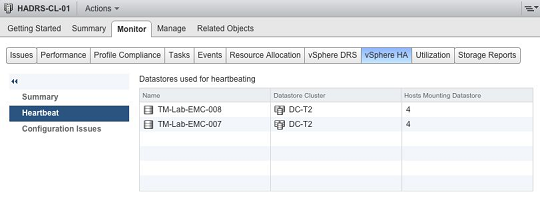
现在的问题就产生了,准确的说,这么多的数据存储,哪一个是用来检测此心跳信号列?让我们来回答,当数据存储第一次用于数据存储心跳时,我们这个时候看下图12,vSphere的Monitor监控中选项卡中显示了群集的广泛信息。例如心跳选项就显示了正使用那些心跳数据存储。
图12 确认心跳数据存储
心跳机制是怎样工作的了?在基于块的存储环境中HA利用现有的VMFS文件系统机制,该机制使用了所谓的“心跳区域”被更新,只要打开该文件。在VMFS数据存储,HA会简单地检查是否已更新的心跳地区。为了更新数据存储心跳区域,主机需要卷上至少有一个打开的文件。 HA确保有至少有一个文件打开此卷上创建一个文件,专门用于数据存储检测信号。换句话说,每一个主机文件被创建在所指定的检测信号数据存储,如在图13中示出。这个文件的的命名方案如下:
host-<number>-hb
图13 心跳文件

在NFS数据存储,每个主机将写每5秒一次心跳文件,确保该主机将能够检查主机的状态。master将只是通过验证检查时间戳的文件的改变。
要认识到,在一个聚合的网络环境的情况下,数据存储检测信号的有效性将取决于对故障的类型。例如,网卡故障可能会影响网络和数据存储检测信号。 无论出于何种原因,如果数据存储或NFS共享变得不可用,或从集群中删除,HA会检测到这一点,检测机制会选择一个新的数据存储或NFS共享。
基本设计原则
数据存储心跳增加了HA的弹性,但是不是最终目的,在网络环境中,由于使用数据存储检测心跳信号,一个网卡的故障可能会导致网络和存储都不可用。
隔离和分区对比
我们已经简要的谈到过它,现在我们来仔细看这个问题,在vSphere 5.0的HA中,一个新的群集节点可以被称为存在分区,怎样准确的说是一台主机是分区而不是隔离?在此之前我们会解释,管理员会观察master报告的状态信息以及特征信息
首先,从管理员的角度来看,两个主机被认为划分了区域,如果他们可以操作,但是管理网络不可达,此外,一台主机是隔离的,不能被HA管理网络上的检测包发现,IP地址被隔离也不能ping通。也有可能这这一时间多台主机被分离,这就是我们所说的主机被分开,但它们之间的管理网络可以通信,网络分区可能会设计到两个以上的分区,但通常这种情况很少。
现在,从FDM的角度考虑,当任何一个FDM不能再网络中联系上master,它们会选举出新的master,所以,当网络的分区存在,选举将会发生,这样当主机发生故障或者网络被隔离时,才会对受影响的虚拟机采取适当的行动,图14西南是了隔离和分区会出现的可能方式。
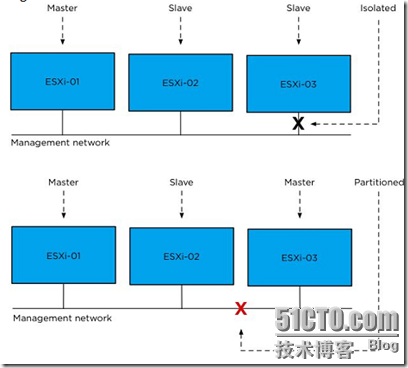
图14 隔离对比分区
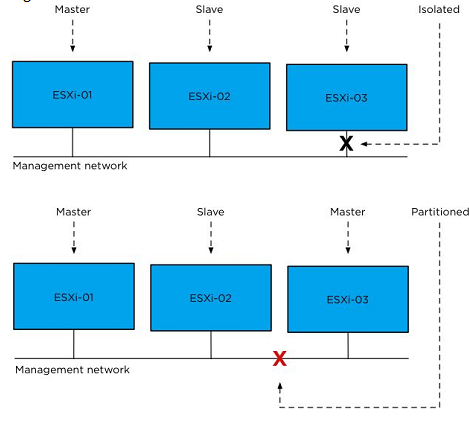
如果群集分区为多个子网,每个分区都选举出自己的master,意思是如果你有4个网络分区,你就有4个master,如果网络划分区分正确,4个分区都能起到接管群集的作用,应该指出的是master可以要求负责不同分区的虚拟机,如果发生这种情况,虚拟机出现故障,master将通过数据存储心跳接收到相关信息。
在HA架构中,无论主机是否分区,master都要报告相关情况,所以,在上面的例子中,host ESXi-01上的master将要报告ESXi03和ESXi04的分区,同时host04上的master也将要报告ESXi01和ESXi02的分区,当分区发生,vCenter将依照准则报告给其中一个master。
一个master无法通过管理网络与主机通信,它会报告该主机被分区或者隔离,主机通过数据存储管道到该主机的数据存储心跳,master不能单独区别这两种孤立和隔离状态,只有主机主动告诉master它被隔离。
这里就留下一个问题,当出现故障,master怎样区分主机是被分区还是隔离?
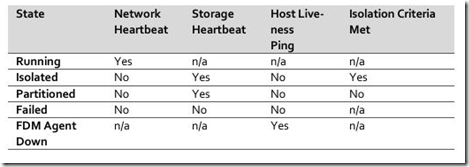
当master停止从slave接收网络心跳,它会检查主机在接下来15S的活跃度,在宣布主机出现故障之前,如果主机已经出现故障或没有检测到活动状态,主机将进行验证,首先,主机是否仍然进行数据存储心跳,其次,master会ping管理网络的主机IP地址,如果两项都否定,那么宣布主机出现故障,这并不意味着主机PSOD’ed,它可能是网络不可用,包括存储网络,从管理员的角度来看主机隔离了,但不是从HA的角度,正如你所想到的,但是,也有各种其它“组合”的可能,下表就描述了这些组合的状态信息。
表2 主机状态

HA会基于主机的各种状态触发行动,当主机标记为故障,将发起重新启动虚拟机的操作,当主机被标记为隔离,master会被重新选举。正如前面所提到的,当重新启动时这是相对vSphere 5.0之前版本的很大的一个改变,无论虚拟机或者主机的状态,一件事要记住,隔离响应是指,当隔离主机知道有个master,虚拟机将被关闭或者断电时,或者当隔离主机失去访问数据存储的虚拟机,它就有了虚拟机的所有权。
例如,如果一个主机上运行两台虚拟机,这两个虚拟机在不同的数据存储上,当主机被隔离后,主机将验证它是否可以访问这两台虚拟机的数据存储,如果可以,主机将验证master是否拥有这些数据存储,如果master不拥有这些数据存储,隔离响应将不被触发,将不会采取重新启动,如果主机不能访问数据存储,例如,在所有路径都断开的情况下,HA会触发隔离响应,以确保“原始”的虚拟机断电并安全的重启,这样做就可以避免“脑裂”splite-brain
重申的是,对比之前所有版本中的HA,这是一个很重大的变化,当master检测到主机故障或者被隔离,群集中其它的主机将仅仅收到重新启动虚拟机的需求,并且触发隔离响应,如果对隔离响应还不是很理解,不用担心,我们将在第四章深入讨论。
虚拟机保护
vSphere 5.0中虚拟机的保护方式已发生了重大的改变,在vSphere5.0版本之前,虚拟机保护使用VPXA同时通过VPXA的模块vmap通知AAM,在vSphere5.0中,虚拟机保护有好几层,但基本上是vCenter来负责,我们解释这个比较简单,但我们希望这块能够扩展更详细,以保证vCenter在保护虚拟机时,每个人都能够理解虚拟机对vCenter的依赖,我们想强调,这只适合保护虚拟机;虚拟机的重启什么都不需要vCenter。
当虚拟机的状态发生改变,vCenter将指挥master启用或者关闭对虚拟机的HA保护,不管怎样,只是当master承若过的磁盘状态发生改变时才保护。原因是这样的,当然,master故障会导致已存在内存的状态信息损坏,正如前面所指出的,这种状态存储在数据存储的“protectedlist”文件中。
当虚拟机的电源状态改变时,master将会告诉vCenter,这样用户就可以看见虚拟机的状态改变,也为其它程序如监控工具提供信息。
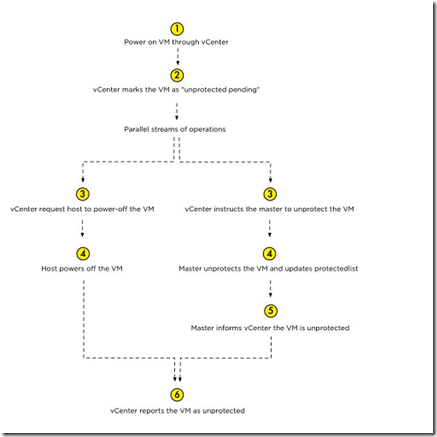
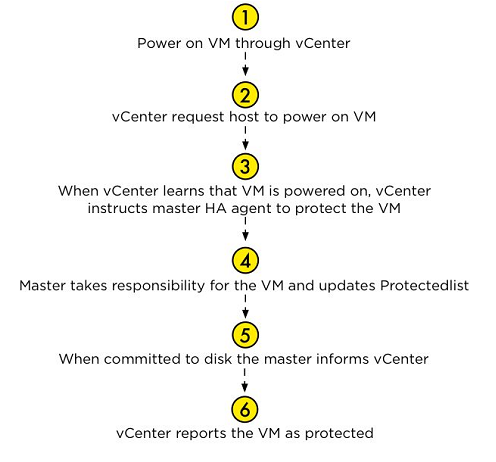
要澄清的是,我们保护虚拟机的工作流(图15)是通过vCenter来创建的。
图15 虚拟机保护流程
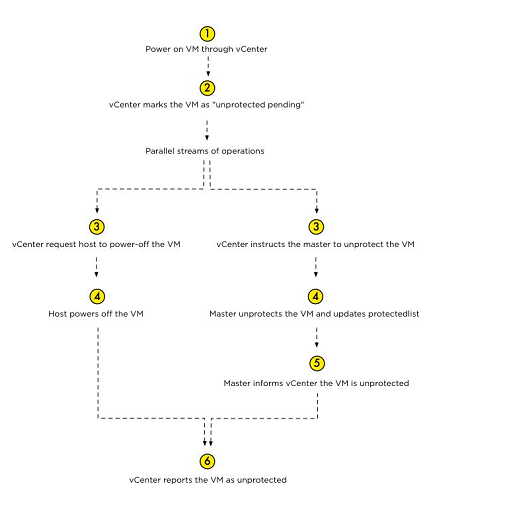
但是什么叫“解除保护”?当一个虚拟机的电源关闭,它将会从protectedlist中移除,我们在图16中证明了该工作流程。
图16 虚拟机接触保护工作流
本文出自 “virtualbox” 博客,请务必保留此出处http://virtualbox.blog.51cto.com/531002/1171256

相关文章推荐
- VMware vSphere 5.1 群集深入解析(七)
- VMware vSphere 5.1 群集深入解析(十一)-vMotion和EVC
- VMware vSphere 5.1 群集深入解析(二十四)- 对存储vMotion的影响
- VMware vSphere 5.1 群集深入解析(二十五)- 关联性
- VMware vSphere 5.1 群集深入解析(二十)- 存储DRS算法
- VMware vSphere 5.1 群集深入解析(二十六)- 数据存储维护模式&汇总
- VMware vSphere 5.1 群集深入解析(十三)
- VMware vSphere 5.1 群集深入解析(十五)-DRS推荐向导
- VMware vSphere 5.1 群集深入解析(二十三)- 数据存储架构与设计
- VMware vSphere 5.1 群集深入解析(十六)-DPM介绍
- VMware vSphere 5.1 群集深入解析(二十一)- 存储I/O控制(SIOC)
- VMware vSphere 5.1 群集深入解析(四)
- VMware vSphere 5.1 群集深入解析(十)
- VMware vSphere 5.1 群集深入解析(一)
- VMware vSphere 5.1 群集深入解析(二)
- VMware vSphere 5.1 群集深入解析(八)
- VMware vSphere 5.1 群集深入解析(二十九)-故障排错
- VMware vSphere 5.1 群集深入解析(十二)- DRS动态配额
- VMware vSphere 5.1 群集深入解析(十七)-DPM计算推荐
- VMware vSphere 5.1 群集深入解析(十八)-DPM推荐向导&汇总