aDev第13期#个性化推荐技术#总结(Part II:江申@百度)
2012-11-10 00:33
288 查看
[本文链接:/article/7095330.html,转载请注明出处。]
Talk2:面向广告主的推荐,江申@百度 [注:本文中很多语句都直接拷贝自作者的演讲ppt而并未加以标明,具体请对照原ppt(下载地址:http://vdisk.weibo.com/s/gNuoh)。] 作者主要讲的是百度面向广告主的推荐产品,主要指拍卖词推荐。 1. 技术目标要正确。在做产品时,我们当然会有一个目的目标,比如提升用户购买率,或者最大化公司收益等。但如何把这种目的目标数学化,也就是写成数学上可以表达的目标函数,其实非常不容易。比如豆瓣的王守琨之前也曾经说过豆瓣在做豆瓣电台时开始以用户的红心率来衡量用户满意度,后来发现红心率倒是挺高,可惜用户打完红心再也不回来了。作者简单介绍了他们在做拍卖词推荐时所使用的数学目标的演变过程: 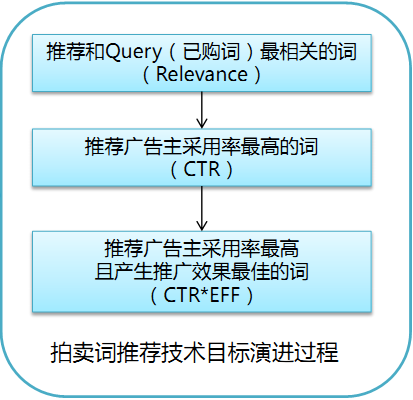
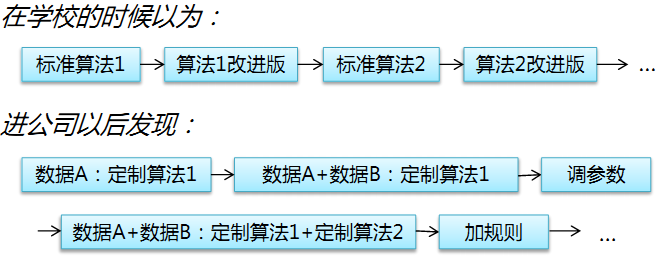
2. 在学校和在公司的算法工程师做事情有什么区别呢?由算法驱动变为数据驱动。见下面直观的图解:
3. 关于系统架构,作者认为好的架构应该可以很好地融合各种数据,并能很容易地根据对数据的理解调整算法。基于他们的数据,他们开发了基于hadoop的级联二部图框架。级联二部图是在一般二部图的基础上增加了第三种结点,下面是一个例子:
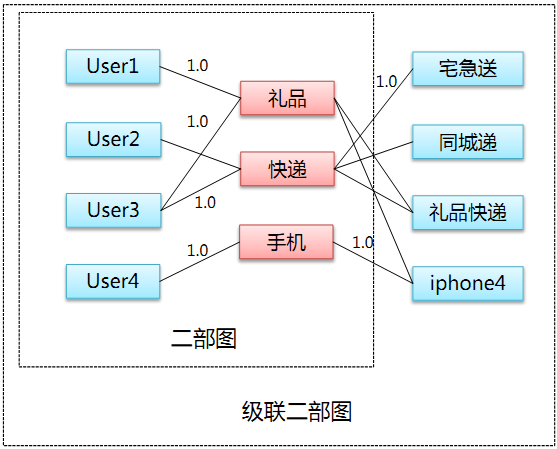
这种级联二部图可以被用来计算结点之间的相似度,以及实现knn-based推荐算法等。而且,如果你的数据中有超过3种结点,你也可以通过把数据分解为多个级联二部图后利用这个框架获得求解(详见ppt)。 4. 在拍卖词推荐中主要涉及到三种模型:相关性模型、采用率模型和推广效果模型。相关性模型被用来判断候选词与Query(及广告主)的相关性;其训练数据来自于人工标注(通过人工标注候选与Query(广告主)是否相关),大小为十万级样本*百级特征;算法使用的是Adaboost。采用率模型被用来判断候选词被采用的概率;其训练数据来自于推荐结果的展现点击日志(利用了展现但未被采用的候选的信息),大小为十亿级样本*亿级特征;算法使用的是Logistic Regression。推广效果模型被用来预估候选词为广告主带来的推广效果(组合多个广告主推广效果指标如点击数、有消费率等而形成的一个指标);其训练数据来自于广告系统的投放日志及转化跟踪数据,大小为十亿级样本*亿级特征;算法使用的是Logistic Regression。 5. 作者建议了引入用户反馈的一种很简单的方法:
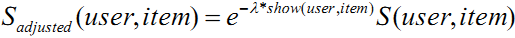
也就是按照item已经对user展示的次数指数级降低其权重,避免同一个item多次重复被展示给一个用户。其实另一种更简单暴力的方法是直接按照被展示次数升序排序,被展示0次的item总是会排在被展示1次的item的前面(比较适用于候选item很多的情形)。 6. 设计合适的推荐理由。在面向广告主的推荐中,作者给出了两条推荐理由设计原则:1) 尽可能多地告诉用户那些他们做决策时需要的信息(例如候选词的商业指标);2) 要说,但是“不能说太细”(防止作弊,破坏竞价机制等)。 7. 在做A/B测试时,要评估结果的显著性。可以做A/B/A测试,当A1与A2的关注指标在一段时间内都平稳后,比较A1(或A2)与B。

相关文章推荐
- aDev第13期#个性化推荐技术#总结(Part III, Final: 稳国柱@豆瓣)
- aDev第13期#个性化推荐技术#总结(Part I:袁全@一淘)
- aDev第13期#个性化推荐技术#总结(Part I:袁全@一淘)
- 个性化智能推荐技术研究总结
- 个性化推荐系统技术总结
- docker技术剖析--docker资源限制及应用总结 推荐
- 《推荐系统实践》读书总结--个性化推荐系统的概念和应用
- [转]个性化推荐技术的十大挑战
- 个性化推荐技术漫谈
- 基于百度API的开源自动翻译.srt文件软件的实现的几个技术细节总结附源代码
- 常见控件推荐 - 技术总结 - 道客巴巴
- 淘宝aDev技术沙龙总结:消息中间件和BigPipe
- 百度秘密研发推荐引擎技术 2011年组建百人团队
- 产品运营必修课:个性化推荐技术
- 个性化推荐技术
- KVM虚拟化网络优化技术总结 推荐
- 聊聊淘宝天猫个性化推荐技术演进史
- TEC1303.Form个性化技术总结 - 第二部分 Form个性化开发实例
- 计算机和网络技术难点总结: 推荐
- 个性化推荐技术的十大挑战