汇编语言笔记07-更灵活的定位内存地址的方法
2012-10-20 17:31
453 查看
转载必须注明出处,违者必究。http://www.cnblogs.com/dennisOne
小知识点1:and和or指令
and指令
mov al, 01100011B
and al, 00111011B
or指令
mov al, 01100011B
or al, 00111011B
and和or指令的功能(比如大小写转化,将后面的知识点)
and:复位
or: 置位
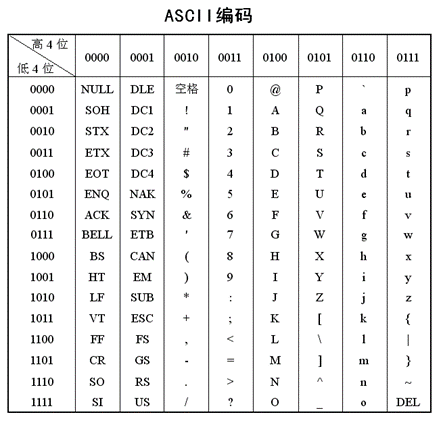
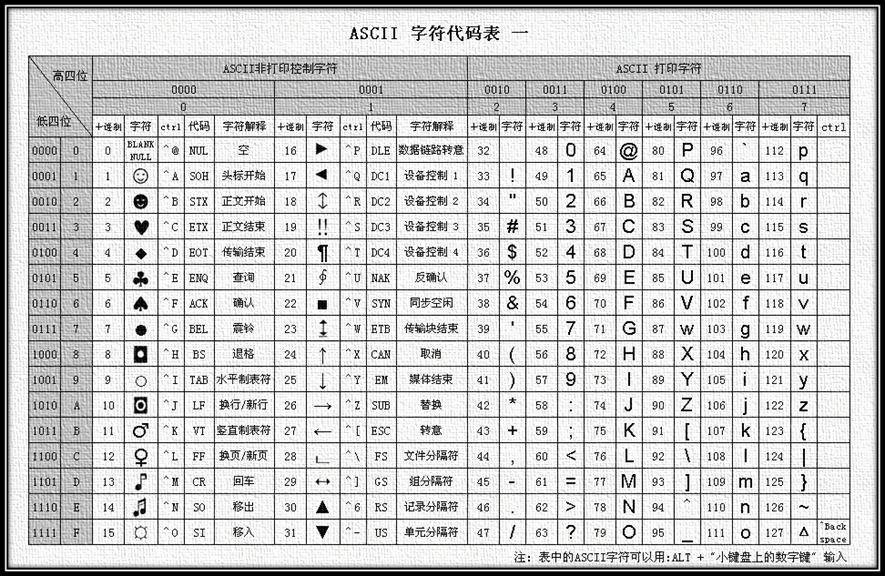
小知识点2:ASCII码
一种很重要的编码方式:ASCII(American Standard Code for Information Interchange, ASCII )
小知识点3:以字符形式给出的数据
在汇编语言中,使用'…'的方式指明数据以字符的形式给出,编译器将它们转化为对应的ASCII码。
例:
经典:大小写转换问题
大小写字母的ASCII码

程序:将'BaSic'编程大写的,将'iNfOrMaTion'编程小写的。
各种寻址方式(更加详细的见下章)
定位内存的方式,称为:寻址方式。主要有:
(1). segreg:[data]用一个常量来表达地址,可用于直接定位一个内存;
(2).[bx]用一个变量表示内存地址,可用于间接定位一个内存单元;
(3).[bx+idata]用一个变量和常量表示地址定位一个内存单元;
(4).[bx+si]两个变量表示地址;
(5).[bx+si+idata]用两个变量和一个常量表示地址。
[bx]和[bx+idata]:进行数组的处理
例:将data段中每个单词的头一个字母改写成大写字母。
[bx+si]和[bx+di]:处理双层循环
例:将data段中每个单词都改写成大写字母。
改进:规范的程序都是使用stack进行数据的保存。
改进代码:
[bx+si+idata]和[bx+di+idata]
例:将data段的首四个字母改成大写。
总结:
(1). [bx]和[bx+idata]用于进行数组的处理; [bx+si/di]和[bx+si/di+idata]用于双层循环的场合,此外[bx+si/di+idata]可以方便进行类结构体的处理。
(2). 双层循环用于loop指令公用cx寄存器。所以需要注意cx寄存器的保存和恢复。
(3). 栈常用于数据的保存和恢复。下一讲将介绍bp将更加强大。
(4). and和or指令常用于复位和置位。
小知识点1:and和or指令
and指令
mov al, 01100011B
and al, 00111011B
or指令
mov al, 01100011B
or al, 00111011B
and和or指令的功能(比如大小写转化,将后面的知识点)
and:复位
or: 置位
小知识点2:ASCII码
一种很重要的编码方式:ASCII(American Standard Code for Information Interchange, ASCII )
小知识点3:以字符形式给出的数据
在汇编语言中,使用'…'的方式指明数据以字符的形式给出,编译器将它们转化为对应的ASCII码。
例:
assume cs:code, ds:data data segment db 'unIX' ; 等价于 db 75H, 6EH, 49H, 58H db 'foRK' ; 等价于 db 66H, 6FH, 52H, 4BH data ends code segment start: mov al, 'a' ; 等价于 mov al, 61H mov bl, 'b' ; 等价于 mov al, 62H mov ax, 4c00h int 21h code ends end start
经典:大小写转换问题
大小写字母的ASCII码
程序:将'BaSic'编程大写的,将'iNfOrMaTion'编程小写的。
assume cs:code, ds:data data segment db 'BaSic' db 'iNfOrMaTion' data ends code segment start: mov ax, data mov ds, ax mov bx, 0 mov cx,5 s: mov al, [bx] and al, 11011111B ;将al的ASCII码的第5位置为0,变成大写字母 inc bx loop s mov cx, 11 s0: mov al, [bx] or al, 00100000B ;将al的ASCII码的第5位置为1,变成小写字母 inc bx loop s0 mov ax, 4C00H int 21h code ends end start
各种寻址方式(更加详细的见下章)
定位内存的方式,称为:寻址方式。主要有:
(1). segreg:[data]用一个常量来表达地址,可用于直接定位一个内存;
(2).[bx]用一个变量表示内存地址,可用于间接定位一个内存单元;
(3).[bx+idata]用一个变量和常量表示地址定位一个内存单元;
(4).[bx+si]两个变量表示地址;
(5).[bx+si+idata]用两个变量和一个常量表示地址。
[bx]和[bx+idata]:进行数组的处理
例:将data段中每个单词的头一个字母改写成大写字母。
assume cs:code, ds:data data segment db '1. file ' db '2. edit ' db '3. search ' db '4. view ' db '5. options ' db '6. help ' data ends code segment start: mov ax, data mov ds, ax mov bx, 0 mov cx, 6 s: mov al, [bx+3] and al, 11011111b mov [bx+3], al add bx, 16 loop s code ends end start
[bx+si]和[bx+di]:处理双层循环
例:将data段中每个单词都改写成大写字母。
;双层循环要注意共用cx,要注意cx的保存与恢复。 assume cs:code, ds:data data segment db 'ibm ' db 'dec ' db 'doc ' db 'vax ' data ends code segment start: mov ax, data mov ds, ax mov bx, 0 ; 外层循环的指标 mov cx, 4 s0: mov dx, cx ; 保存cx mov si, 0 ; 内存循环的指标 mov cx, 3 s: mov al, [bx+si] and al, 11011111b mov [bx+si], al inc si loop s add bx, 8 mov cx, dx ; 恢复cx loop s0 mov ax, 4c00h int 21h code ends end start
改进:规范的程序都是使用stack进行数据的保存。
改进代码:
assume cs:code, ds:data, ss:stack data segment db 'ibm ' db 'dec ' db 'doc ' db 'vax ' data ends stack segment dw 0, 0, 0, 0, 0, 0, 0, 0 ;定义一个容量为16个字节的栈 stack ends code segment start: mov ax, stack mov ss, ax mov sp, 16 mov ax, data mov ds, ax mov bx, 0 mov cx, 4 s0: push cx ; 保存cx mov si, 0 mov cx, 3 s: mov al, [bx+si] and al, 11011111b mov [bx+si], al inc si loop s add bx, 16 pop cx ; 恢复cx loop s0 mov ax, 4c00h int 21h code ends end start
[bx+si+idata]和[bx+di+idata]
例:将data段的首四个字母改成大写。
assume cs:code, ds:data, ss:stack data segment db '1. display ' db '2. brows ' db '3. replace ' db '4. modify ' data ends stack segment dw 0, 0, 0, 0, 0, 0, 0, 0 stack ends code segment start: mov ax, stack mov ss, ax mov sp, 16 mov ax, data mov ds, ax mov bx, 0 mov cx, 4 s0: push cx ;保存cx mov si, 0 mov cx, 4 s: mov al, [bx+si+3] and al, 11011111b mov [bx+si+3], al inc si loop s add bx, 16 pop cx ;恢复cx loop s0 mov ax, 4c00h int 21h code ends 40 end start
总结:
(1). [bx]和[bx+idata]用于进行数组的处理; [bx+si/di]和[bx+si/di+idata]用于双层循环的场合,此外[bx+si/di+idata]可以方便进行类结构体的处理。
(2). 双层循环用于loop指令公用cx寄存器。所以需要注意cx寄存器的保存和恢复。
(3). 栈常用于数据的保存和恢复。下一讲将介绍bp将更加强大。
(4). and和or指令常用于复位和置位。

相关文章推荐
- 汇编语言学习笔记(七)更灵活的定位内存地址的方法
- 汇编语言第七章学习笔记——更灵活的定位内存地址的方法
- [置顶] [汇编语言学习笔记][第七章更灵活的定位内存的方法]
- 更灵活的定位内存地址的方法01 - 零基础入门学习汇编语言32
- 更灵活的定位内存地址的方法05 - 零基础入门学习汇编语言36
- 更灵活的定位内存地址的方法01 - 零基础入门学习汇编语言32
- 更灵活的定位内存地址的方法05 - 零基础入门学习汇编语言36
- 汇编语言复习摘要七——更灵活的定位内存地址方法
- 【汇编语言/底层开发】7、更灵活的定位内存地址方法
- [汇编语言]-第七章 更灵活的定位内存地址的方法
- 更灵活的定位内存地址的方法03 - 零基础入门学习汇编语言34
- 更灵活的定位内存地址的方法02 - 零基础入门学习汇编语言33
- 更灵活的定位内存地址的方法03 - 零基础入门学习汇编语言34
- 汇编语言学习第七章-更灵活的定位内存地址的方法
- 更灵活的定位内存地址的方法02 - 零基础入门学习汇编语言33
- 更灵活的定位内存地址的方法04 - 零基础入门学习汇编语言35
- 更灵活的定位内存地址的方法04 - 零基础入门学习汇编语言35
- 更灵活的定位内存地址的方法06 - 零基础入门学习汇编语言37
- 更灵活的定位内存地址的方法06 - 零基础入门学习汇编语言37
- [汇编语言学习笔记][第七章更灵活的定位内存的方法]