LRU缓存的实现算法讨论
2012-09-26 16:51
465 查看
业务模型
读、写、删的比例大致是7:3:1,至少要支持500w条缓存,平均每条缓存6k,要求设计一套性能比较好的缓存算法。
算法分析
不考虑MemCached,Velocity等现成的key-value缓存方案,也不考虑脱离.net
gc自己管理内存,不考虑随机读取数据及顺序读取数据的场景,目前想到的有如下几种LRU方案
目前几种方案在多线程下应该都需要加锁,不太好设计无锁的方案,下面这个链接是一个支持多线程的方案,但原理至今没搞特明白
A High Performance Multi-Threaded LRU Cache
http://www.codeproject.com/KB/recipes/LRUCache.aspx
用普通链表简单实现LRU缓存
以下是最后一种方案的简单实现,大家讨论下这个方案值不值得优化,或者其它的哪个方案比较合适
public class LRUCacheHelper<K, V> {
readonly Dictionary<K, V> _dict;
readonly LinkedList<K> _queue = new LinkedList<K>();
readonly object _syncRoot = new object();
private readonly int _max;
public LRUCacheHelper(int capacity, int max) {
_dict = new Dictionary<K, V>(capacity);
_max = max;
}
public void Add(K key, V value) {
lock (_syncRoot) {
checkAndTruncate();
_queue.AddFirst(key); //O(1)
_dict[key] = value; //O(1)
}
}
private void checkAndTruncate() {
lock (_syncRoot) {
int count = _dict.Count; //O(1)
if (count >= _max) {
int needRemoveCount = count / 10;
for (int i = 0; i < needRemoveCount; i++) {
_dict.Remove(_queue.Last.Value); //O(1)
_queue.RemoveLast(); //O(1)
}
}
}
}
public void Delete(K key) {
lock (_syncRoot) {
_dict.Remove(key); //(1)
_queue.Remove(key); // O(n)
}
}
public V Get(K key) {
lock (_syncRoot) {
V ret;
_dict.TryGetValue(key, out ret); //O(1)
_queue.Remove(key); //O(n)
_queue.AddFirst(key); //(1)
return ret;
}
}
}
用双头链表代替普通链表
突然想起来了,可以把链表换成双头链表,然后在字典里保存链表节点,在Get方法的时候直接从字典里获取到要移动的节点,然后把这个节点的上一个节点的Next指针指向给下一个节点,下一个节点的Previous指针指向上一个节点,这样就把移动节点的操作简化成O(1)了,提高了缓存读取的效率。
_dict.TryGetValue(key, out ret); //O(1)
ret.Next.Previous = ret.Previous //O(1)
ret. Previous.Next. = ret.Next //O(1)
_queue.AddFirst(key); //O(1)
我改进后的链表就差不多满足需求了,
其中截断的时候可以指定当缓存满的时候截断百分之多少的最少使用的缓存项。
其它的就是多线程的时候锁再看看怎么优化,字典有线程安全的版本,就把.net
3.0的读写锁扣出来再把普通的泛型字典保证成ThreadSafelyDictionay就行了,性能应该挺好的。
链表的话不太好用读写锁来做线程同步,大不了用互斥锁,但得考虑下锁的粒度,Move,AddFirst,RemoveLast的时候只操作一两个节点,是不是想办法只lock这几个节点就行了,Truncate的时候因为要批量操作很多节点,所以要上个大多链表锁,但这时候怎么让其它操作停止得考虑考虑,类似数据库的表锁和行锁。
实现代码
public class DoubleLinkedListNode<T> {
public T Value { get; set; }
public DoubleLinkedListNode<T> Next { get; set; }
public DoubleLinkedListNode<T> Prior { get; set; }
public DoubleLinkedListNode(T t) { Value = t; }
public DoubleLinkedListNode() { }
public void RemoveSelf() {
Prior.Next = Next;
Next.Prior = Prior;
}
}
public class DoubleLinkedList<T> {
protected DoubleLinkedListNode<T> m_Head;
private DoubleLinkedListNode<T> m_Tail;
public DoubleLinkedList() {
m_Head = new DoubleLinkedListNode<T>();
m_Tail = m_Head;
}
public DoubleLinkedList(T t)
: this() {
m_Head.Next = new DoubleLinkedListNode<T>(t);
m_Tail = m_Head.Next;
m_Tail.Prior = m_Head;
}
public DoubleLinkedListNode<T> Tail {
get { return m_Tail; }
}
public DoubleLinkedListNode<T> AddHead(T t) {
DoubleLinkedListNode<T> insertNode = new DoubleLinkedListNode<T>(t);
DoubleLinkedListNode<T> currentNode = m_Head;
insertNode.Prior = null;
insertNode.Next = currentNode;
currentNode.Prior = insertNode;
m_Head = insertNode;
return insertNode;
}
public void RemoveTail() {
m_Tail = m_Tail.Prior;
m_Tail.Next = null;
return;
}
}
public class LRUCacheHelper<K, V> {
class DictItem {
public DoubleLinkedListNode<K> Node { get; set; }
public V Value { get; set; }
}
readonly Dictionary<K, DictItem> _dict;
readonly DoubleLinkedList<K> _queue = new DoubleLinkedList<K>();
readonly object _syncRoot = new object();
private readonly int _max;
public LRUCacheHelper(int capacity, int max) {
_dict = new Dictionary<K, DictItem>(capacity);
_max = max;
}
public void Add(K key, V value) {
lock (this)
{
checkAndTruncate();
DoubleLinkedListNode<K> v = _queue.AddHead(key); //O(1)
_dict[key] = new DictItem() { Node = v, Value = value }; //O(1)
}
}
private void checkAndTruncate() {
int count = _dict.Count; //O(1)
if (count >= _max) {
int needRemoveCount = count / 10;
for (int i = 0; i < needRemoveCount; i++) {
_dict.Remove(_queue.Tail.Value); //O(1)
_queue.RemoveTail(); //O(1)
}
}
}
public void Delete(K key) {
lock (this) {
_dict[key].Node.RemoveSelf();
_dict.Remove(key); //(1)
}
}
public V Get(K key) {
lock (this) {
DictItem ret;
if (_dict.TryGetValue(key, out ret)) {
ret.Node.RemoveSelf();
_queue.AddHead(key);
return ret.Value;
}
return default(V);
}
}
}
性能测试
用双头链表测试了一下,感觉性能还可以接受,每秒钟读取可达80多w,每秒钟写操作越20多w。
程序初始化200w条缓存,然后不断的加,每加到500w,截断掉10分之一,然后继续加。
测试模型中每秒钟的读和写的比例是7:3,以下是依次在3个时间点截取的性能计数器图。
图1
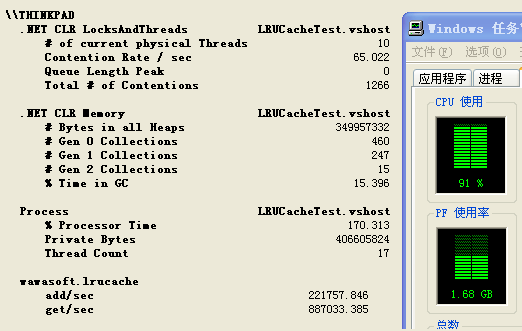
图2
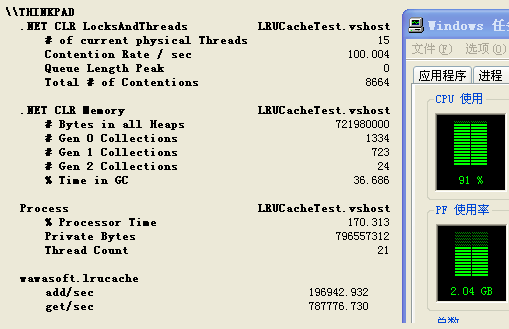
图3

内存最高会达到1g,cpu也平均百分之90以上,但测试到后期会发现每隔一段时间,就会有一两秒,吞吐量为0,如最后一张截图,后来观察发现,停顿的那一两秒是二代内存在回收,等不停顿的时候#
gen 2 collections就会加1,这个原因应该是链表引起的,对链表中节点的添加和删除是很耗费GC的,因为会频繁的创建和销毁对象。
后续改进
1、 用游标链表来代替普通的双头链表,程序起来就收工分配固定大小的数组,然后用数组的索引来做链表,省得每次添加和删除节点都要GC的参与,这相当于手工管理内存了,但目前我还没找到c#合适的实现。
2、 有人说链表不适合用在多线程环境中,因为对链表的每个操作都要加互斥锁,连读写锁都用不上,我目前的实现是直接用互斥锁做的线程同步,每秒的吞吐量七八十万,感觉lock也不是瓶颈,如果要改进的话可以把Dictionary用ThreadSafelyDictionary来代替,然后链表还用互斥锁(刚开始设想的链表操作只锁要操作的几个节点以降低并发冲突的想法应该不可取,不严谨)。
3、 还有一个地方就是把锁细分以下,链表还用链表,但每个链表的节点是个HashSet,对HashSet的操作如果只有读,写,删,没有遍历的话应该不需要做线程同步(我感觉不用,因为Set就是一个集合,一个线程往里插入,一个线程往里删除,一个线程读取应该没问题,顶多读进来的数据可能马上就删除了,而整个Set的结构不会破坏)。然后新增数据的时候往链表头顶Set里插入,读取某个数据的时候把它所在的节点的Set里删除该数据,然后再链表头的Set里插入一个数据,这样反复操作后,链表的最后一个节点的Set里的数据都是旧数据了,可以安全的删除了,当然这个删除的时候应该是要锁整个链表的。每个Set应该有个大小上限,比如20w,但set不能安全的遍历,就不能得到当前大小,所以添加、删除Set的数据的时候应该用Interlocked.Decrement()和 Interlocked.Increment()维护一个Count,一遍一个Set满的时候,再到链表的头新增一个Set节点。
性能测试脚本
class Program {
private static PerformanceCounter _addCounter;
private static PerformanceCounter _getCounter;
static void Main(string[] args) {
SetupCategory();
_addCounter = new PerformanceCounter("wawasoft.lrucache", "add/sec", false);
_getCounter = new PerformanceCounter("wawasoft.lrucache", "get/sec", false);
_addCounter.RawValue = 0;
_getCounter.RawValue = 0;
Random rnd = new Random();
const int max = 500 * 10000;
LRUCacheHelper<int, int> cache = new LRUCacheHelper<int, int>(200 * 10000, max);
for (int i = 10000*100000 - 1; i >= 0; i--)
{
if(i % 10 > 7)
{
ThreadPool.QueueUserWorkItem(
delegate
{
cache.Add(rnd.Next(0, 10000), 0);
_addCounter.Increment();
});
}
else
{
ThreadPool.QueueUserWorkItem(
delegate
{
int pop = cache.Get(i);
_getCounter.Increment();
});
}
}
Console.ReadKey();
}
private static void SetupCategory() {
if (!PerformanceCounterCategory.Exists("wawasoft.lrucache")) {
CounterCreationDataCollection CCDC = new CounterCreationDataCollection();
CounterCreationData addcounter = new CounterCreationData();
addcounter.CounterType = PerformanceCounterType.RateOfCountsPerSecond32;
addcounter.CounterName = "add/sec";
CCDC.Add(addcounter);
CounterCreationData getcounter = new CounterCreationData();
getcounter.CounterType = PerformanceCounterType.RateOfCountsPerSecond32;
getcounter.CounterName = "get/sec";
CCDC.Add(getcounter);
PerformanceCounterCategory.Create("wawasoft.lrucache","lrucache",CCDC);
}
}
}
读、写、删的比例大致是7:3:1,至少要支持500w条缓存,平均每条缓存6k,要求设计一套性能比较好的缓存算法。
算法分析
不考虑MemCached,Velocity等现成的key-value缓存方案,也不考虑脱离.net
gc自己管理内存,不考虑随机读取数据及顺序读取数据的场景,目前想到的有如下几种LRU方案
| 算法 | 分析 |
| SortedDictionary | .net自带的,内部用二叉搜索树(应该不是普通树,至少是做过优化的树)实现的,检索为O(log n),比普通的Dictionay(O(1))慢一点。 插入和删除都是O(log n),而且插入和删除,会实时排序。 但是.net 2.0的这个类没有First属性 |
| Dictionary + PriorityQueue | Dictionay可以保证检索是O(1); 优先队列可以保证插入和删除都为O(log n); 但是优先队列删除指定的项不支持(至少我找到的优先队列不支持),所以在删除缓存的时候不知道咋实现 |
| Dictionay + Binary heap | 二叉堆也是优先队列,分析应该同上,我没有详细评估。 |
| b树 | 查找,删除,插入效率都很好,数据库都用它,但实现复杂,写一个没有BUG的B树几乎不可能。有人提到stl:map是自顶向下的红黑树,查找,删除,插入都是O(log n),但咱不懂c++,没做详细测试。 |
| Dictionay + List | Dict用来检索; List用来排序; 检索、添加、删除都没问题,只有在清空的时候需要执行List的排序方法,这时候缓存条目比较多的话,可能比较慢。 |
| Dictionay + LinkedList | Dict用来检索; LinkedList的添加和删除都是O(1),添加缓存时在链表头加节点,获取缓存时把特定节点移动(先删除特定节点(O(n)),再到头部添加节点(O(1)))到头,缓存满地时候截断掉尾部的一些节点。 |
A High Performance Multi-Threaded LRU Cache
http://www.codeproject.com/KB/recipes/LRUCache.aspx
用普通链表简单实现LRU缓存
以下是最后一种方案的简单实现,大家讨论下这个方案值不值得优化,或者其它的哪个方案比较合适
public class LRUCacheHelper<K, V> {
readonly Dictionary<K, V> _dict;
readonly LinkedList<K> _queue = new LinkedList<K>();
readonly object _syncRoot = new object();
private readonly int _max;
public LRUCacheHelper(int capacity, int max) {
_dict = new Dictionary<K, V>(capacity);
_max = max;
}
public void Add(K key, V value) {
lock (_syncRoot) {
checkAndTruncate();
_queue.AddFirst(key); //O(1)
_dict[key] = value; //O(1)
}
}
private void checkAndTruncate() {
lock (_syncRoot) {
int count = _dict.Count; //O(1)
if (count >= _max) {
int needRemoveCount = count / 10;
for (int i = 0; i < needRemoveCount; i++) {
_dict.Remove(_queue.Last.Value); //O(1)
_queue.RemoveLast(); //O(1)
}
}
}
}
public void Delete(K key) {
lock (_syncRoot) {
_dict.Remove(key); //(1)
_queue.Remove(key); // O(n)
}
}
public V Get(K key) {
lock (_syncRoot) {
V ret;
_dict.TryGetValue(key, out ret); //O(1)
_queue.Remove(key); //O(n)
_queue.AddFirst(key); //(1)
return ret;
}
}
}
用双头链表代替普通链表
突然想起来了,可以把链表换成双头链表,然后在字典里保存链表节点,在Get方法的时候直接从字典里获取到要移动的节点,然后把这个节点的上一个节点的Next指针指向给下一个节点,下一个节点的Previous指针指向上一个节点,这样就把移动节点的操作简化成O(1)了,提高了缓存读取的效率。
_dict.TryGetValue(key, out ret); //O(1)
ret.Next.Previous = ret.Previous //O(1)
ret. Previous.Next. = ret.Next //O(1)
_queue.AddFirst(key); //O(1)
我改进后的链表就差不多满足需求了,
| 操作 | 基本操作 | 复杂度 |
| 读取 | Dict.Get Queue.Move | O 1 O 1 |
| 删除 | Dict.Remove Queue.Remove | O 1 O 1 |
| 增加 | Dict.Add Queue.AddFirst | O 1 O 1 |
| 截断 | Dict.Remove Queue.RemoveLast | O k O k K表示截断缓存元素的个数 |
其它的就是多线程的时候锁再看看怎么优化,字典有线程安全的版本,就把.net
3.0的读写锁扣出来再把普通的泛型字典保证成ThreadSafelyDictionay就行了,性能应该挺好的。
链表的话不太好用读写锁来做线程同步,大不了用互斥锁,但得考虑下锁的粒度,Move,AddFirst,RemoveLast的时候只操作一两个节点,是不是想办法只lock这几个节点就行了,Truncate的时候因为要批量操作很多节点,所以要上个大多链表锁,但这时候怎么让其它操作停止得考虑考虑,类似数据库的表锁和行锁。
实现代码
public class DoubleLinkedListNode<T> {
public T Value { get; set; }
public DoubleLinkedListNode<T> Next { get; set; }
public DoubleLinkedListNode<T> Prior { get; set; }
public DoubleLinkedListNode(T t) { Value = t; }
public DoubleLinkedListNode() { }
public void RemoveSelf() {
Prior.Next = Next;
Next.Prior = Prior;
}
}
public class DoubleLinkedList<T> {
protected DoubleLinkedListNode<T> m_Head;
private DoubleLinkedListNode<T> m_Tail;
public DoubleLinkedList() {
m_Head = new DoubleLinkedListNode<T>();
m_Tail = m_Head;
}
public DoubleLinkedList(T t)
: this() {
m_Head.Next = new DoubleLinkedListNode<T>(t);
m_Tail = m_Head.Next;
m_Tail.Prior = m_Head;
}
public DoubleLinkedListNode<T> Tail {
get { return m_Tail; }
}
public DoubleLinkedListNode<T> AddHead(T t) {
DoubleLinkedListNode<T> insertNode = new DoubleLinkedListNode<T>(t);
DoubleLinkedListNode<T> currentNode = m_Head;
insertNode.Prior = null;
insertNode.Next = currentNode;
currentNode.Prior = insertNode;
m_Head = insertNode;
return insertNode;
}
public void RemoveTail() {
m_Tail = m_Tail.Prior;
m_Tail.Next = null;
return;
}
}
public class LRUCacheHelper<K, V> {
class DictItem {
public DoubleLinkedListNode<K> Node { get; set; }
public V Value { get; set; }
}
readonly Dictionary<K, DictItem> _dict;
readonly DoubleLinkedList<K> _queue = new DoubleLinkedList<K>();
readonly object _syncRoot = new object();
private readonly int _max;
public LRUCacheHelper(int capacity, int max) {
_dict = new Dictionary<K, DictItem>(capacity);
_max = max;
}
public void Add(K key, V value) {
lock (this)
{
checkAndTruncate();
DoubleLinkedListNode<K> v = _queue.AddHead(key); //O(1)
_dict[key] = new DictItem() { Node = v, Value = value }; //O(1)
}
}
private void checkAndTruncate() {
int count = _dict.Count; //O(1)
if (count >= _max) {
int needRemoveCount = count / 10;
for (int i = 0; i < needRemoveCount; i++) {
_dict.Remove(_queue.Tail.Value); //O(1)
_queue.RemoveTail(); //O(1)
}
}
}
public void Delete(K key) {
lock (this) {
_dict[key].Node.RemoveSelf();
_dict.Remove(key); //(1)
}
}
public V Get(K key) {
lock (this) {
DictItem ret;
if (_dict.TryGetValue(key, out ret)) {
ret.Node.RemoveSelf();
_queue.AddHead(key);
return ret.Value;
}
return default(V);
}
}
}
性能测试
用双头链表测试了一下,感觉性能还可以接受,每秒钟读取可达80多w,每秒钟写操作越20多w。
程序初始化200w条缓存,然后不断的加,每加到500w,截断掉10分之一,然后继续加。
测试模型中每秒钟的读和写的比例是7:3,以下是依次在3个时间点截取的性能计数器图。
图1
图2
图3
内存最高会达到1g,cpu也平均百分之90以上,但测试到后期会发现每隔一段时间,就会有一两秒,吞吐量为0,如最后一张截图,后来观察发现,停顿的那一两秒是二代内存在回收,等不停顿的时候#
gen 2 collections就会加1,这个原因应该是链表引起的,对链表中节点的添加和删除是很耗费GC的,因为会频繁的创建和销毁对象。
后续改进
1、 用游标链表来代替普通的双头链表,程序起来就收工分配固定大小的数组,然后用数组的索引来做链表,省得每次添加和删除节点都要GC的参与,这相当于手工管理内存了,但目前我还没找到c#合适的实现。
2、 有人说链表不适合用在多线程环境中,因为对链表的每个操作都要加互斥锁,连读写锁都用不上,我目前的实现是直接用互斥锁做的线程同步,每秒的吞吐量七八十万,感觉lock也不是瓶颈,如果要改进的话可以把Dictionary用ThreadSafelyDictionary来代替,然后链表还用互斥锁(刚开始设想的链表操作只锁要操作的几个节点以降低并发冲突的想法应该不可取,不严谨)。
3、 还有一个地方就是把锁细分以下,链表还用链表,但每个链表的节点是个HashSet,对HashSet的操作如果只有读,写,删,没有遍历的话应该不需要做线程同步(我感觉不用,因为Set就是一个集合,一个线程往里插入,一个线程往里删除,一个线程读取应该没问题,顶多读进来的数据可能马上就删除了,而整个Set的结构不会破坏)。然后新增数据的时候往链表头顶Set里插入,读取某个数据的时候把它所在的节点的Set里删除该数据,然后再链表头的Set里插入一个数据,这样反复操作后,链表的最后一个节点的Set里的数据都是旧数据了,可以安全的删除了,当然这个删除的时候应该是要锁整个链表的。每个Set应该有个大小上限,比如20w,但set不能安全的遍历,就不能得到当前大小,所以添加、删除Set的数据的时候应该用Interlocked.Decrement()和 Interlocked.Increment()维护一个Count,一遍一个Set满的时候,再到链表的头新增一个Set节点。
性能测试脚本
class Program {
private static PerformanceCounter _addCounter;
private static PerformanceCounter _getCounter;
static void Main(string[] args) {
SetupCategory();
_addCounter = new PerformanceCounter("wawasoft.lrucache", "add/sec", false);
_getCounter = new PerformanceCounter("wawasoft.lrucache", "get/sec", false);
_addCounter.RawValue = 0;
_getCounter.RawValue = 0;
Random rnd = new Random();
const int max = 500 * 10000;
LRUCacheHelper<int, int> cache = new LRUCacheHelper<int, int>(200 * 10000, max);
for (int i = 10000*100000 - 1; i >= 0; i--)
{
if(i % 10 > 7)
{
ThreadPool.QueueUserWorkItem(
delegate
{
cache.Add(rnd.Next(0, 10000), 0);
_addCounter.Increment();
});
}
else
{
ThreadPool.QueueUserWorkItem(
delegate
{
int pop = cache.Get(i);
_getCounter.Increment();
});
}
}
Console.ReadKey();
}
private static void SetupCategory() {
if (!PerformanceCounterCategory.Exists("wawasoft.lrucache")) {
CounterCreationDataCollection CCDC = new CounterCreationDataCollection();
CounterCreationData addcounter = new CounterCreationData();
addcounter.CounterType = PerformanceCounterType.RateOfCountsPerSecond32;
addcounter.CounterName = "add/sec";
CCDC.Add(addcounter);
CounterCreationData getcounter = new CounterCreationData();
getcounter.CounterType = PerformanceCounterType.RateOfCountsPerSecond32;
getcounter.CounterName = "get/sec";
CCDC.Add(getcounter);
PerformanceCounterCategory.Create("wawasoft.lrucache","lrucache",CCDC);
}
}
}

相关文章推荐
- 蛙蛙推荐: LRU缓存的实现算法讨论
- 蛙蛙推荐: LRU缓存的实现算法讨论
- 简单LRU算法实现缓存
- 基于LinkedHashMap实现LRU缓存调度算法原理
- 采用LRU算法的MemoryCache缓存实现
- LRU缓存淘汰算法分析与实现
- Nodejs基于LRU算法实现的缓存处理操作示例
- c++实现的常见缓存算法和LRU
- 简单LRU算法实现缓存
- 简单LRU算法实现缓存大小的限制策略
- 简单LRU算法实现缓存
- 缓存淘汰算法之LRU实现
- 简单LRU算法实现缓存
- 基于LRU算法的缓存实现
- LRU缓存替换算法介绍与编程实现
- 【Leetcode】:LRU Cache_缓存淘汰算法LRU的设计与实现
- 利用LinkedHashMap实现LRU算法缓存
- leetcode LRU Cache(高级缓存的最近最少使用算法实现)
- 算法: 实现LRU缓存,读取、写入O(1)实现
- Java缓存的Lru算法实现---并对Android util类LruCache的改进