浅谈内存池几种设计方式
2012-07-19 11:50
323 查看
写服务器的,通常会涉及到内存池的东西,自己在这方面也看了写了一些东西,有些体会,写出来跟大家分享下。
内存池基本包含以下几个东西,第一,初始化。第二,分配内存。第三,回收内存。所谓初始化,就是在服务器启动的时候,或者第一次需要内存的时候,系统分配很大的一块内存,方便之后的使用。分配内存,就是从内存池中取出需要的内存给外部使用,当然这里需要考虑的是当内存池中没有内存可分配时候的处理。回收内存,简单来说,就是外面对象生命期结束了,将分配出去的内存回收入内存池中。好了简单概念就说完了,我们先来看一种最简单的设计方式。
//为了方便描述,这里附上几个简单的链表操作宏
#define INSERT_TO_LIST( head, item, prev, next )
\
do{ \
if ( head )
\
(head)->prev = (item);
\
(item)->next = (head);
\
(head) = (item); \
}while(0)
#define REMOVE_FROM_LIST(head, item, prev, next)
\
do{ \
if ( (head) == (item) )
\
{
\
(head) = (item)->next;
\
if ( head )
\
(head)->prev = NULL;
\
}
\
else
\
{
\
if ( (item)->prev )
\
(item)->prev->next = (item)->next; \
\
if ( (item)->next )
\
(item)->next->prev = (item)->prev; \
}
\
}while(0)
struct student
{
char name[32];
byte sex;
struct student *prev,*next;
};
static struct mem_pool
{
//该指针用来记录空闲节点
struct student *free;
//该变量记录分配结点个数
size_t alloc_cnt;
}s_mem_pool;
//分配内存“块”的函数
bool mem_pool_resize(size_t size)
{
//该函数创建size个不连续的对象,把他们通过链表的方式加入到s_mem_pool.free中
for ( size_t i = 0;i < size;++i )
{
struct student *p = (struct student *)malloc(sizeof(struct student));
if ( !p )
return false;
p->prev = p->next = NULL;
INSERT_TO_LIST(s_mem_pool.free,p,prev,next);
}
s_mem_pool.alloc_cnt += size;
}
#define MEM_INIT_SIZE 512
#define MEM_INC_SIZE 256
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
struct student *get_data()
{
if ( s_mem_pool.free == NULL )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
struct student *ret = s_mem_pool.free;
REMOVE_FROM_LIST(s_mem_pool.free,ret,prev,next)
return ret;
}
void free_data(struct student *p)
{
if ( !p )
return;
memset(p,0,sizeof(struct student));
INSERT_TO_LIST(s_mem_pool.free,p,prev,next)
}
好了最简单的内存池的大致框架就是这样。我们先来看下他的过程。首先,在mem_pool_init()函数中,他先分配512个不连续的student对象。每分配出来一个就把它加入到free链表中,初始化完成后内存池大概是这样的
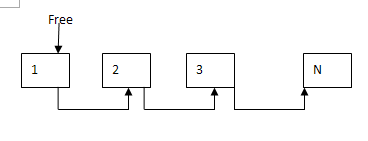
接下来就是从内存池中取出一个对象get_data()。函数先去判断是否有空闲的对象,有则直接分配,否则再向系统获取一"块"大的内存。调用一次后的内存池大概是这样的

释放对象,再把对象加入到Free链表中。
以上就是过程的简单分析,下面我们来看看他的缺点。
第一,内存不是连续的,容易产生碎片
第二,一个类型就得写一个这样的内存池,很麻烦
第三,为了构建这个内存池,每个没对象必须加上一个prev,next指针
好了,我们来优化一下它。我们重新定义下我们的结构体
union student
{
int index;
struct
{
char name[32];
byte sex;
}s;
};
static struct mem_pool
{
//该下标用来记录空闲节点
int free;
//内存池
union student *mem;
//已分配结点个数
size_t alloc_cnt;
}s_mem_pool;
//分配内存块的函数
bool mem_pool_resize(size_t size)
{
size_t new_size = s_mem_pool.alloc_cnt+size;
union student *tmp = (union student *)realloc(s_mem_pool.mem,new_size*sizeof(union student));
if ( !tmp )
return false;
memset(tmp+s_mem_pool.alloc_cnt,0,size*sizeof(union student));
size_t i = s_mem_pool.alloc_cnt;
for ( ;i < new_size - 1;++i )
{
tmp[i].index = i + 1;
}
tmp[i].index = -1;
s_mem_pool.free = s_mem_pool.alloc_cnt;
s_mem_pool.mem = tmp;
s_mem_pool.alloc_cnt = new_size;
return true;
}
#define MEM_INIT_SIZE 512
#define MEM_INC_SIZE 256
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
union student *get_data()
{
if ( s_mem_pool.free == -1 )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
union student *ret = s_mem_pool.mem+s_mem_pool.free;
s_mem_pool.free = ret->index;
return ret;
}
void free_data(union student *p)
{
if ( !p )
return;
p->index = s_mem_pool.free;
s_mem_pool.free = p - s_mem_pool.mem;
}
我们来看看改进了些什么。第一student改成了联合体,这主要是为了不占用额外的内存,也就是我们上面所说的第三个缺点,第二,我们使用了realloc函数,这样我们可以使我们分配出来的内存是连续的。我们初始化的时候多了一个for循环,这是为了记录空闲对象的下标,当我们取出一个对象时,free可以立刻知道下一个空闲对象的位置,释放的时候,对象先记录free此时的值,接着再把free赋值成该对象在数组的下标,这样就完成了回收工作。
我们继续分析这段代码,问题在realloc函数上,如果我们的s_mem_pool.mem已经很大了,在realloc的时候我们都知道,先要把原来的数据做一次拷贝,所以如果数据量很大的情况下做一次拷贝,是会消耗性能的。那这里有没有好的办法呢,我们进一步优化
思路大概是这样
初始化
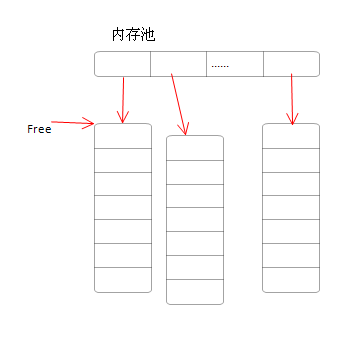
再次分配的时候,我们只需要重新分配新的内存单元,而不需要拷贝之前的内存单元。

因此基于此思路,我们修改我们的代码
#include <stdio.h>
#include <stdlib.h>
struct student
{
int index;
char name[32];
byte sex;
};
static struct mem_pool
{
//该下标用来记录空闲节点
int free;
//内存池
struct student **mem;
//已分配块个数
size_t block_cnt;
}s_mem_pool;
#define BLOCK_SIZE 256 //每块的大小
//分配内存块的函数
bool mem_pool_resize(size_t block_size)
{
size_t new_cnt = s_mem_pool.block_cnt + block_size;
struct student **tmp = (struct student **)realloc(s_mem_pool.mem,new_size*sizeof(struct student *));
if ( !tmp )
return false;
memset(tmp+s_mem_pool.block_cnt,0,size*sizeof(struct student*));
for ( size_t i = s_mem_pool.block_cnt;i < new_cnt;++i )
{
tmp[i] = (struct student *)calloc(BLOCK_SIZE,sizeof(struct student));
if ( !tmp[i] )
return false;
size_t j = 0;
for(;j < BLOCK_SIZE - 1;++j )
{
tmp[i][j].index = i*BLOCK_SIZE+j+1;
}
if ( i != new_cnt-1 )
tmp[i][j].index = (i+1)*BLOCK_SIZE;
else
tmp[i][j].index = -1;
}
s_mem_pool.free = s_mem_pool.alloc_cnt*BLOCK_SIZE;
s_mem_pool.mem = tmp;
s_mem_pool.block_cnt = new_cnt;
return true;
}
#define MEM_INC_SIZE 10
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
struct student *get_data()
{
if ( s_mem_pool.free == -1 )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
struct student *ret = s_mem_pool.mem[s_mem_pool.free/BLOCK_SIZE]+s_mem_pool.free%BLOCK_SIZE;
int pos = s_mem_pool.free;
s_mem_pool.free = ret->index;
ret->index = pos;
return ret;
}
void free_data(struct student *p)
{
if ( !p )
return;
int pos = p->index;
p->index = s_mem_pool.free;
s_mem_pool.free = pos;
}
这里不一样的地方主要在mem_pool_resize函数中,mem变成了2级指针,每次realloc的时候只需要分配指针数组的大小,无须拷贝对象,这样可以提高效率,但是为了在释放的时候把对象放回该放的位置,我们这里在结构体里加入了index变量,记录它的下标。在内存池里,它表示下个空闲对象的下标,在内存池外,它表示在内存池中的下标。总的来说满足了一个需求,却又带来了新的问题,有没有更好的方法呢,答案是肯定,不过今天先写到这里,明天继续。
内存池基本包含以下几个东西,第一,初始化。第二,分配内存。第三,回收内存。所谓初始化,就是在服务器启动的时候,或者第一次需要内存的时候,系统分配很大的一块内存,方便之后的使用。分配内存,就是从内存池中取出需要的内存给外部使用,当然这里需要考虑的是当内存池中没有内存可分配时候的处理。回收内存,简单来说,就是外面对象生命期结束了,将分配出去的内存回收入内存池中。好了简单概念就说完了,我们先来看一种最简单的设计方式。
//为了方便描述,这里附上几个简单的链表操作宏
#define INSERT_TO_LIST( head, item, prev, next )
\
do{ \
if ( head )
\
(head)->prev = (item);
\
(item)->next = (head);
\
(head) = (item); \
}while(0)
#define REMOVE_FROM_LIST(head, item, prev, next)
\
do{ \
if ( (head) == (item) )
\
{
\
(head) = (item)->next;
\
if ( head )
\
(head)->prev = NULL;
\
}
\
else
\
{
\
if ( (item)->prev )
\
(item)->prev->next = (item)->next; \
\
if ( (item)->next )
\
(item)->next->prev = (item)->prev; \
}
\
}while(0)
struct student
{
char name[32];
byte sex;
struct student *prev,*next;
};
static struct mem_pool
{
//该指针用来记录空闲节点
struct student *free;
//该变量记录分配结点个数
size_t alloc_cnt;
}s_mem_pool;
//分配内存“块”的函数
bool mem_pool_resize(size_t size)
{
//该函数创建size个不连续的对象,把他们通过链表的方式加入到s_mem_pool.free中
for ( size_t i = 0;i < size;++i )
{
struct student *p = (struct student *)malloc(sizeof(struct student));
if ( !p )
return false;
p->prev = p->next = NULL;
INSERT_TO_LIST(s_mem_pool.free,p,prev,next);
}
s_mem_pool.alloc_cnt += size;
}
#define MEM_INIT_SIZE 512
#define MEM_INC_SIZE 256
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
struct student *get_data()
{
if ( s_mem_pool.free == NULL )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
struct student *ret = s_mem_pool.free;
REMOVE_FROM_LIST(s_mem_pool.free,ret,prev,next)
return ret;
}
void free_data(struct student *p)
{
if ( !p )
return;
memset(p,0,sizeof(struct student));
INSERT_TO_LIST(s_mem_pool.free,p,prev,next)
}
好了最简单的内存池的大致框架就是这样。我们先来看下他的过程。首先,在mem_pool_init()函数中,他先分配512个不连续的student对象。每分配出来一个就把它加入到free链表中,初始化完成后内存池大概是这样的
接下来就是从内存池中取出一个对象get_data()。函数先去判断是否有空闲的对象,有则直接分配,否则再向系统获取一"块"大的内存。调用一次后的内存池大概是这样的
释放对象,再把对象加入到Free链表中。
以上就是过程的简单分析,下面我们来看看他的缺点。
第一,内存不是连续的,容易产生碎片
第二,一个类型就得写一个这样的内存池,很麻烦
第三,为了构建这个内存池,每个没对象必须加上一个prev,next指针
好了,我们来优化一下它。我们重新定义下我们的结构体
union student
{
int index;
struct
{
char name[32];
byte sex;
}s;
};
static struct mem_pool
{
//该下标用来记录空闲节点
int free;
//内存池
union student *mem;
//已分配结点个数
size_t alloc_cnt;
}s_mem_pool;
//分配内存块的函数
bool mem_pool_resize(size_t size)
{
size_t new_size = s_mem_pool.alloc_cnt+size;
union student *tmp = (union student *)realloc(s_mem_pool.mem,new_size*sizeof(union student));
if ( !tmp )
return false;
memset(tmp+s_mem_pool.alloc_cnt,0,size*sizeof(union student));
size_t i = s_mem_pool.alloc_cnt;
for ( ;i < new_size - 1;++i )
{
tmp[i].index = i + 1;
}
tmp[i].index = -1;
s_mem_pool.free = s_mem_pool.alloc_cnt;
s_mem_pool.mem = tmp;
s_mem_pool.alloc_cnt = new_size;
return true;
}
#define MEM_INIT_SIZE 512
#define MEM_INC_SIZE 256
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
union student *get_data()
{
if ( s_mem_pool.free == -1 )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
union student *ret = s_mem_pool.mem+s_mem_pool.free;
s_mem_pool.free = ret->index;
return ret;
}
void free_data(union student *p)
{
if ( !p )
return;
p->index = s_mem_pool.free;
s_mem_pool.free = p - s_mem_pool.mem;
}
我们来看看改进了些什么。第一student改成了联合体,这主要是为了不占用额外的内存,也就是我们上面所说的第三个缺点,第二,我们使用了realloc函数,这样我们可以使我们分配出来的内存是连续的。我们初始化的时候多了一个for循环,这是为了记录空闲对象的下标,当我们取出一个对象时,free可以立刻知道下一个空闲对象的位置,释放的时候,对象先记录free此时的值,接着再把free赋值成该对象在数组的下标,这样就完成了回收工作。
我们继续分析这段代码,问题在realloc函数上,如果我们的s_mem_pool.mem已经很大了,在realloc的时候我们都知道,先要把原来的数据做一次拷贝,所以如果数据量很大的情况下做一次拷贝,是会消耗性能的。那这里有没有好的办法呢,我们进一步优化
思路大概是这样
初始化
再次分配的时候,我们只需要重新分配新的内存单元,而不需要拷贝之前的内存单元。
因此基于此思路,我们修改我们的代码
#include <stdio.h>
#include <stdlib.h>
struct student
{
int index;
char name[32];
byte sex;
};
static struct mem_pool
{
//该下标用来记录空闲节点
int free;
//内存池
struct student **mem;
//已分配块个数
size_t block_cnt;
}s_mem_pool;
#define BLOCK_SIZE 256 //每块的大小
//分配内存块的函数
bool mem_pool_resize(size_t block_size)
{
size_t new_cnt = s_mem_pool.block_cnt + block_size;
struct student **tmp = (struct student **)realloc(s_mem_pool.mem,new_size*sizeof(struct student *));
if ( !tmp )
return false;
memset(tmp+s_mem_pool.block_cnt,0,size*sizeof(struct student*));
for ( size_t i = s_mem_pool.block_cnt;i < new_cnt;++i )
{
tmp[i] = (struct student *)calloc(BLOCK_SIZE,sizeof(struct student));
if ( !tmp[i] )
return false;
size_t j = 0;
for(;j < BLOCK_SIZE - 1;++j )
{
tmp[i][j].index = i*BLOCK_SIZE+j+1;
}
if ( i != new_cnt-1 )
tmp[i][j].index = (i+1)*BLOCK_SIZE;
else
tmp[i][j].index = -1;
}
s_mem_pool.free = s_mem_pool.alloc_cnt*BLOCK_SIZE;
s_mem_pool.mem = tmp;
s_mem_pool.block_cnt = new_cnt;
return true;
}
#define MEM_INC_SIZE 10
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
struct student *get_data()
{
if ( s_mem_pool.free == -1 )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
struct student *ret = s_mem_pool.mem[s_mem_pool.free/BLOCK_SIZE]+s_mem_pool.free%BLOCK_SIZE;
int pos = s_mem_pool.free;
s_mem_pool.free = ret->index;
ret->index = pos;
return ret;
}
void free_data(struct student *p)
{
if ( !p )
return;
int pos = p->index;
p->index = s_mem_pool.free;
s_mem_pool.free = pos;
}
这里不一样的地方主要在mem_pool_resize函数中,mem变成了2级指针,每次realloc的时候只需要分配指针数组的大小,无须拷贝对象,这样可以提高效率,但是为了在释放的时候把对象放回该放的位置,我们这里在结构体里加入了index变量,记录它的下标。在内存池里,它表示下个空闲对象的下标,在内存池外,它表示在内存池中的下标。总的来说满足了一个需求,却又带来了新的问题,有没有更好的方法呢,答案是肯定,不过今天先写到这里,明天继续。

相关文章推荐
- 浅谈单例设计模式的几种实现方式
- 第三方支付常见几种支付方式的流程设计
- 设计模式--单例模式的几种实现方式
- 设计模式——单例模式的几种实现方式
- 浅谈iOS开发中方法延迟执行的几种方式(转载)
- 浅谈Hyper-V的几种备份方式(二)----Windows Server Backup &VSS
- 进程间通信的几种方式浅谈(下)
- java设计模式学习笔记5 适配器模式几种实现方式
- 浅谈MapRuduce的几种Join方式
- 浅谈Android平台短信拦截的几种实现方式(包括NDK注册短信监听器)
- 浅谈 EF CORE 迁移和实例化的几种方式
- 浅谈 EF CORE 迁移和实例化的几种方式
- 【自然框架】之通用权限:数据库设计的几种使用方式
- 基于linux的数字电视机顶盒几种升级方式的设计与实现
- 浅谈XMl解析的几种方式
- 权限管理编程的几种设计方式
- linux下并发机制设计的几种方式介绍
- 浅谈Activity几种不同的启动方式
- 权限管理编程的几种设计方式
- 浅谈Node.js 访问文件系统的几种读取方式