科普-文本挖掘(文本分类)流程
2012-07-04 13:56
225 查看
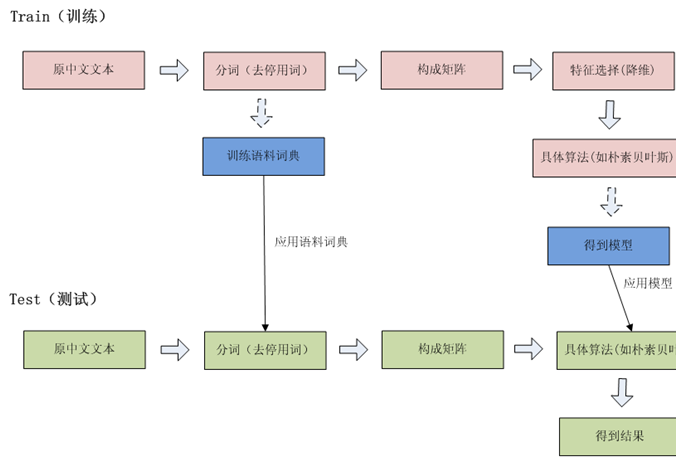
一个典型的文本分类的数据挖掘流程如下图,这张图初看有点乱,我这里解释一下,红色的部分是训练时候调用的模块,绿色是测试时候调用的模块,而蓝色的部分是训练的时候生成的中间文件,它们联系着训练、测试两个部分。从左到右看是算法运行的流程,首先用户给出原始的用于训练的中文文本,然后进行分词等操作。 经过了生成矩阵这个步骤,文本就转化成了数学语言了,之后的算法都是运行在这个数学语言之上,之后的算法就不再关心输入的数据是否是文档了,换句话来说,生成矩阵这个模块相当于是一道门,门内是纯数学表示的算法,门外是原始的文本语料。

相关文章推荐
- 中文文本挖掘预处理流程总结
- 2.1 文本挖掘与文本分类的概念
- 文本挖掘之详细整体的流程
- 以虎嗅网4W+文章的文本挖掘为例,展现数据分析的一整套流程
- 文本挖掘预处理的流程总结
- 算法在文本挖掘中应用流程-svm
- 中文文本挖掘预处理流程总结
- 【文本分类】文本分类流程及算法原理
- 用 Python 做文本挖掘的基本流程
- 英文文本挖掘预处理流程总结
- 文本挖掘的具体流程
- 自然语言处理(4)之中文文本挖掘流程详解(小白入门必读)
- 中文文本挖掘预处理流程
- 用 Python 做文本挖掘的流程
- 英文文本挖掘预处理流程总结
- 文本挖掘预处理的流程总结
- 用Python 做文本挖掘的流程
- 文本挖掘的基本流程
- 用 Python 做文本挖掘的流程
- 文本挖掘的基本流程