基于机器学习的SNS隐私保护策略推荐向导的设计与实现
2012-06-03 22:09
676 查看
引言:这篇论文是我最近读到的将机器学习/数据挖掘算法引入到SNS网络隐私保护领域中的一篇经典论文,感觉模型比较有新意,实现了自动化的用户隐私设置分析,用户只需要对很少朋友根据自己的隐私偏好打上访问控制标签,分类器就可以对其他大部分朋友的访问权限做自动分类,并且达到了很高的准确率,大大减轻了SNS用户手动隐私设置的负担。该论文发表于WWW10'及CCS10‘,我将全文翻译并加入了自己的理解性注释,发布到自己的博客上与国内网友共享,最近打算将这个项目实现并且深入做下去,目前的进展见博文《数据挖掘-基于机器学习的SNS隐私策略推荐向导分类器的C++及WEKA实现与评估》有兴趣参与这个项目的朋友可以与我联系交流:)。博文是本文目录及前两部分,全文PDF版下载链接见点击打开链接
基于机器学习的SNS隐私保护策略推荐向导的设计与实现
Lujun Fang and Kristen LeFevre
ElectricalEngineering & Computer Science, University of Michigan
CCS10’及WWW10’论文杨柳概述整理核心内容 yang.liu@pku.edu.cn
摘要
设计一个SNS隐私保护策略推荐向导,利用机器学习方法自动计算出SNS用户的隐私保护偏好,只需要用户进行比现行SNS隐私保护机制下少得多的输入,就可以构建描述用户特定隐私偏好的机器学习模型,然后使用这个模型来自动设置用户SNS隐私保护策略。
具体的实现方法是,以用户SNS资料数据项为行,以朋友为列构建访问控制矩阵,填入访问控制标签。对于每一个朋友抽取出若干属性特征,例如所属的“圈子”,性别,生日,城市等信息,可实现对朋友的向量化表示。基于已有的部分朋友和用户打上的访问许可的标签生成训练样本,其他朋友以及用户新添加的朋友作为测试样本。对于每一项用户资料,例如用户生日信息,系统让用户对少量朋友按照自己的意愿打上allow/deny标签,然后系统基于这些输入形成的训练样本,利用机器学习算法构建分类器,就可以使用该分类器来自动对剩余朋友及用户新添加的朋友设置对该资料的allow/deny访问权限。
现有研究表明[CCS10’ WWW10’],真实的SNS用户会更多基于不同的“圈子”来考虑他们的隐私偏好,而“圈子”信息很容易利用现有技术从社交网络图谱中抽取出来。使用朋友所属的“圈子”信息,可以自动计算出很高准确度的用户隐私保护推荐策略,而需要的用户输入比照当前的SNS隐私保护机制少很多。
全文目录
摘要...
1
1
介绍... 3
1.1
设计目标... 3
1.2
主要工作... 3
2
隐私策略推荐向导概述... 4
2.1
初步建模... 4
2.2
通用隐私保护策略推荐向导设计... 4
3
积极学习式的向导... 6
3.1
偏好模型分类器... 7
3.2
特征抽取... 7
3.2.1
主要抽取的属性特征... 7
3.2.2
基于圈子的属性... 7
3.3
不定抽样... 8
3.4
朋友增量维护... 9
4
模型可视化与修正... 10
4.1
可视化... 10
4.2
模型修正和增量维护... 11
5
模型评估... 11
5.1
从真实用户搜集隐私偏好数据... 11
5.2
实验设计... 12
5.3
比较隐私保护策略... 13
5.3.1
静态场景... 13
5.3.2
动态场景... 14
5.3.3
类概率分布的影响... 15
5.4
比较朋友特征... 16
6
相关研究... 16
7
结论和未来工作... 17
致谢...
17
8
参考文献... 17
1 介绍
当前SNS都允许用户自主设置自己的隐私策略。例如,Facebook有“Privacy Settings”页面,允许用户设置每一项资料对朋友是否可见。Facebook还允许用户创建朋友名单,然后设置某一部分个人资料是否对该名单的中朋友可见。然而有研究表明,由于比较复杂并不友好的用户接口,大多数用户会跳过或者维持默认隐私保护策略。例如,在Facebook上,要实现用户粒度的访问控制,用户必须手动将朋友填入一个名单,由于Facebook用户平均拥有130个朋友,这个过程非常耗费时间。更糟糕的是,这个隐私保护机制需要很多不同的朋友名单,因为对于不同的个人信息,例如家庭地址和宗教信仰,用户会有不同的隐私保护偏好。
很明显,需要更好的SNS隐私保护机制。本文设计了基于机器学习的SNS隐私保护策略推荐向导,可以使得SNS用户以最小的输入代价自动设置个人隐私保护策略。
1.1设计目标
SNS隐私策略推荐向导的设计目标是以最小的用户输入代价自动设置用户个人隐私保护策略。主要挑战如下:
低代价,高准确度。用户输入应该形式简单,数量较少,同时该向导自动计算出的隐私策略要准确反映用户真实隐私偏好。一个原始的方式就是让用户对所有朋友手动设置隐私策略。尽管这种方式如果被完整执行,可以达到完美的隐私偏好准确度,但是也给用户带来了巨大的输入负担,实际并不可行。
良好的鲁棒性。很难估计用户为了进行隐私设置愿意提供的输入量,隐私策略推荐向导的准确率会随着用户提供输入的增加而增加,但是,向导应该假定用户可以在任何时候停止输入。
数据可视化。除了用户输入,向导还可以使用从SNS上自动抓取和处理的信息,但是这些信息只包括当前对该用户可见的信息,具体包含用户的朋友关系,用户可见的朋友资料以及用户朋友的朋友关系。
1.2 主要工作
为了应对这些挑战,我们为隐私策略向导的设计开发了一个框架,这个框架将在第2部分描述。这个框架是基于真实的SNS用户会根据一个特定的暗含规则集来考虑其隐私保护偏好,因此可以使用机器学习算法和少量用户输入来构建用户隐私偏好模型,通过这个模型,可以实现用户隐私保护策略自动化设置。
作为这个框架的一个实例,我们实现了一个用户隐私保护策略推荐向导。这个向导通过学习一个分类器实现了用户隐私偏好模型。在这个分类器中,描述每个朋友的特征,包括所属“圈子”信息,可以从用户可见的信息中自动抽取。向导提供了非常简便的用户交互接口,利用机器学习中的积极学习范式,让用户对少量挑选的朋友打上隐私标签,例如allow/deny。用户提供的输入越多,分类器的性能越好,但是允许用户在任何时候停止输入。更进一步,向导可以适应用户不断添加新朋友的情况。基本的向导使用简单,对于高级用户,向导会提供可以可视化和修改隐私保护策略的工具,这将在第4部分描述。
为了评估这个方案,我们对45个真实的Facebook用户进行了详尽的实验。实验表明,第一,我们的向导达到了更好的用户使用代价和隐私偏好准确率的tradeoff,一般而言,如果一个用户在200个以上的朋友中标注了25个朋友,向导将以高于90%的准确率自动设置用户隐私保护策略。第二,从用户邻居结点中抽取的“圈子”信息对于预测用户隐私偏好极其重要。
2 隐私策略推荐向导概述
2.1 初步建模
用户隐私偏好表现了用户与每个朋友分享隐私的意愿。对于特定的用户,我们定义用户所有朋友构成集合F,定义用户资料中的数据项构成集合I,那么,用户隐私偏好可以用函数pref来定义,
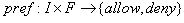
,如果
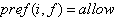
,这就意味着用户的意愿是允许朋友f看到数据项i.
主要术语如下:
用户隐私偏好:指用户理想的隐私保护策略,定义为
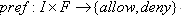
用户隐私设置:SNS实际执行的用户隐私保护策略,定义为
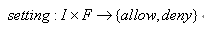
隐私设置准确率:对于特定的朋友集合F和特定的数据项集合I,隐私设置准确率计算公式是
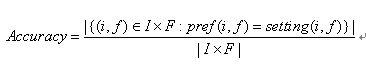
2.2 通用隐私保护策略推荐向导设计
设计隐私保护策略推荐向导的动机是基于这样一个事实,SNS用户实际会根据特定的暗含规则集来考虑其隐私偏好。可以用实例1来说明。
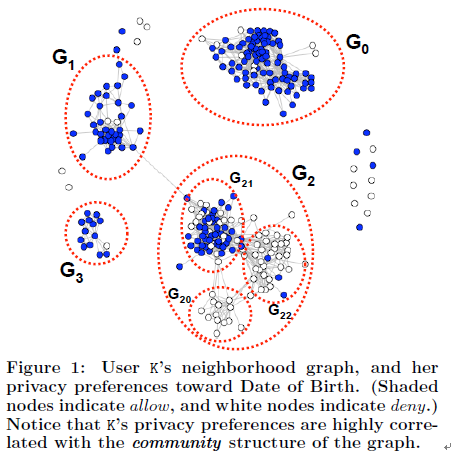
实例1.如图1中所示,在用户K的邻近社交网络中,有几组结点聚集在了一起。图1是使用Fruchterman-Reingold
force-based 布局来描述的,把拓扑上邻近(杨柳注:可以理解为朋友亲密值更大)的结点放置的更近,反之则放置的更远。在社交网络研究中,这些聚集的组称为“圈子”。我们已经在图中手动标明了一些明显的圈子,G0,G1等。观察发现用户K的隐私偏好倾向于在圈子边界处表现出差异。用户愿意同大部分朋友共享其生日信息,但是,有两个圈子,即图中的G20和G22,他不想向其公开自己的生日信息。(杨柳注:比如女生的年龄、身高、体重信息,一般不愿意对异性公布),这就表明了用户K已经根据一组暗含的规则集构建了他的隐私偏好,这些规则与他的朋友网络的基本圈子结构有关。
基于这样一个观察结果,为了应对介绍部分指出的需求,我们提出设计隐私保护策略推荐向导的通用框架,如图2中所示。这个框架由三个部分组成:
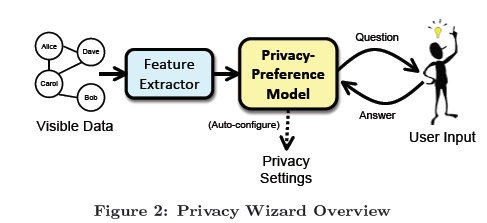
用户输入:向导会向用户请求关于隐私偏好的输入,通常是一些问答互动,用户可以在任何时候放弃回答问题。
特征抽取:使用用户可见信息,向导选取一个特征向量空间,用户的每一个朋友就可以用该空间中的一个向量来描述。
隐私偏好模型:使用抽取的特征和用户输入,向导构建一个隐私偏好模型,包含了推测出的用户考虑隐私偏好时使用的规则特征。这个模型可以被用来自动配置用户的隐私设置。当用户提供更多的输入或者添加新朋友的时候,这个隐私偏好模型和配置的隐私设置应该自动更新。
博文是本文目录及前两部分,全文PDF版下载链接见点击打开链接
基于机器学习的SNS隐私保护策略推荐向导的设计与实现
Lujun Fang and Kristen LeFevre
ElectricalEngineering & Computer Science, University of Michigan
CCS10’及WWW10’论文杨柳概述整理核心内容 yang.liu@pku.edu.cn
摘要
设计一个SNS隐私保护策略推荐向导,利用机器学习方法自动计算出SNS用户的隐私保护偏好,只需要用户进行比现行SNS隐私保护机制下少得多的输入,就可以构建描述用户特定隐私偏好的机器学习模型,然后使用这个模型来自动设置用户SNS隐私保护策略。
具体的实现方法是,以用户SNS资料数据项为行,以朋友为列构建访问控制矩阵,填入访问控制标签。对于每一个朋友抽取出若干属性特征,例如所属的“圈子”,性别,生日,城市等信息,可实现对朋友的向量化表示。基于已有的部分朋友和用户打上的访问许可的标签生成训练样本,其他朋友以及用户新添加的朋友作为测试样本。对于每一项用户资料,例如用户生日信息,系统让用户对少量朋友按照自己的意愿打上allow/deny标签,然后系统基于这些输入形成的训练样本,利用机器学习算法构建分类器,就可以使用该分类器来自动对剩余朋友及用户新添加的朋友设置对该资料的allow/deny访问权限。
现有研究表明[CCS10’ WWW10’],真实的SNS用户会更多基于不同的“圈子”来考虑他们的隐私偏好,而“圈子”信息很容易利用现有技术从社交网络图谱中抽取出来。使用朋友所属的“圈子”信息,可以自动计算出很高准确度的用户隐私保护推荐策略,而需要的用户输入比照当前的SNS隐私保护机制少很多。
全文目录
摘要...
1
1
介绍... 3
1.1
设计目标... 3
1.2
主要工作... 3
2
隐私策略推荐向导概述... 4
2.1
初步建模... 4
2.2
通用隐私保护策略推荐向导设计... 4
3
积极学习式的向导... 6
3.1
偏好模型分类器... 7
3.2
特征抽取... 7
3.2.1
主要抽取的属性特征... 7
3.2.2
基于圈子的属性... 7
3.3
不定抽样... 8
3.4
朋友增量维护... 9
4
模型可视化与修正... 10
4.1
可视化... 10
4.2
模型修正和增量维护... 11
5
模型评估... 11
5.1
从真实用户搜集隐私偏好数据... 11
5.2
实验设计... 12
5.3
比较隐私保护策略... 13
5.3.1
静态场景... 13
5.3.2
动态场景... 14
5.3.3
类概率分布的影响... 15
5.4
比较朋友特征... 16
6
相关研究... 16
7
结论和未来工作... 17
致谢...
17
8
参考文献... 17
1 介绍
当前SNS都允许用户自主设置自己的隐私策略。例如,Facebook有“Privacy Settings”页面,允许用户设置每一项资料对朋友是否可见。Facebook还允许用户创建朋友名单,然后设置某一部分个人资料是否对该名单的中朋友可见。然而有研究表明,由于比较复杂并不友好的用户接口,大多数用户会跳过或者维持默认隐私保护策略。例如,在Facebook上,要实现用户粒度的访问控制,用户必须手动将朋友填入一个名单,由于Facebook用户平均拥有130个朋友,这个过程非常耗费时间。更糟糕的是,这个隐私保护机制需要很多不同的朋友名单,因为对于不同的个人信息,例如家庭地址和宗教信仰,用户会有不同的隐私保护偏好。
很明显,需要更好的SNS隐私保护机制。本文设计了基于机器学习的SNS隐私保护策略推荐向导,可以使得SNS用户以最小的输入代价自动设置个人隐私保护策略。
1.1设计目标
SNS隐私策略推荐向导的设计目标是以最小的用户输入代价自动设置用户个人隐私保护策略。主要挑战如下:
低代价,高准确度。用户输入应该形式简单,数量较少,同时该向导自动计算出的隐私策略要准确反映用户真实隐私偏好。一个原始的方式就是让用户对所有朋友手动设置隐私策略。尽管这种方式如果被完整执行,可以达到完美的隐私偏好准确度,但是也给用户带来了巨大的输入负担,实际并不可行。
良好的鲁棒性。很难估计用户为了进行隐私设置愿意提供的输入量,隐私策略推荐向导的准确率会随着用户提供输入的增加而增加,但是,向导应该假定用户可以在任何时候停止输入。
数据可视化。除了用户输入,向导还可以使用从SNS上自动抓取和处理的信息,但是这些信息只包括当前对该用户可见的信息,具体包含用户的朋友关系,用户可见的朋友资料以及用户朋友的朋友关系。
1.2 主要工作
为了应对这些挑战,我们为隐私策略向导的设计开发了一个框架,这个框架将在第2部分描述。这个框架是基于真实的SNS用户会根据一个特定的暗含规则集来考虑其隐私保护偏好,因此可以使用机器学习算法和少量用户输入来构建用户隐私偏好模型,通过这个模型,可以实现用户隐私保护策略自动化设置。
作为这个框架的一个实例,我们实现了一个用户隐私保护策略推荐向导。这个向导通过学习一个分类器实现了用户隐私偏好模型。在这个分类器中,描述每个朋友的特征,包括所属“圈子”信息,可以从用户可见的信息中自动抽取。向导提供了非常简便的用户交互接口,利用机器学习中的积极学习范式,让用户对少量挑选的朋友打上隐私标签,例如allow/deny。用户提供的输入越多,分类器的性能越好,但是允许用户在任何时候停止输入。更进一步,向导可以适应用户不断添加新朋友的情况。基本的向导使用简单,对于高级用户,向导会提供可以可视化和修改隐私保护策略的工具,这将在第4部分描述。
为了评估这个方案,我们对45个真实的Facebook用户进行了详尽的实验。实验表明,第一,我们的向导达到了更好的用户使用代价和隐私偏好准确率的tradeoff,一般而言,如果一个用户在200个以上的朋友中标注了25个朋友,向导将以高于90%的准确率自动设置用户隐私保护策略。第二,从用户邻居结点中抽取的“圈子”信息对于预测用户隐私偏好极其重要。
2 隐私策略推荐向导概述
2.1 初步建模
用户隐私偏好表现了用户与每个朋友分享隐私的意愿。对于特定的用户,我们定义用户所有朋友构成集合F,定义用户资料中的数据项构成集合I,那么,用户隐私偏好可以用函数pref来定义,
,如果
,这就意味着用户的意愿是允许朋友f看到数据项i.
主要术语如下:
用户隐私偏好:指用户理想的隐私保护策略,定义为
用户隐私设置:SNS实际执行的用户隐私保护策略,定义为
隐私设置准确率:对于特定的朋友集合F和特定的数据项集合I,隐私设置准确率计算公式是
2.2 通用隐私保护策略推荐向导设计
设计隐私保护策略推荐向导的动机是基于这样一个事实,SNS用户实际会根据特定的暗含规则集来考虑其隐私偏好。可以用实例1来说明。
实例1.如图1中所示,在用户K的邻近社交网络中,有几组结点聚集在了一起。图1是使用Fruchterman-Reingold
force-based 布局来描述的,把拓扑上邻近(杨柳注:可以理解为朋友亲密值更大)的结点放置的更近,反之则放置的更远。在社交网络研究中,这些聚集的组称为“圈子”。我们已经在图中手动标明了一些明显的圈子,G0,G1等。观察发现用户K的隐私偏好倾向于在圈子边界处表现出差异。用户愿意同大部分朋友共享其生日信息,但是,有两个圈子,即图中的G20和G22,他不想向其公开自己的生日信息。(杨柳注:比如女生的年龄、身高、体重信息,一般不愿意对异性公布),这就表明了用户K已经根据一组暗含的规则集构建了他的隐私偏好,这些规则与他的朋友网络的基本圈子结构有关。
基于这样一个观察结果,为了应对介绍部分指出的需求,我们提出设计隐私保护策略推荐向导的通用框架,如图2中所示。这个框架由三个部分组成:
用户输入:向导会向用户请求关于隐私偏好的输入,通常是一些问答互动,用户可以在任何时候放弃回答问题。
特征抽取:使用用户可见信息,向导选取一个特征向量空间,用户的每一个朋友就可以用该空间中的一个向量来描述。
隐私偏好模型:使用抽取的特征和用户输入,向导构建一个隐私偏好模型,包含了推测出的用户考虑隐私偏好时使用的规则特征。这个模型可以被用来自动配置用户的隐私设置。当用户提供更多的输入或者添加新朋友的时候,这个隐私偏好模型和配置的隐私设置应该自动更新。
博文是本文目录及前两部分,全文PDF版下载链接见点击打开链接

相关文章推荐
- 数据挖掘-基于机器学习的SNS隐私策略推荐向导分类器的C++及WEKA实现与评估
- 数据挖掘-基于机器学习的SNS隐私策略推荐向导分类器的C++及WEKA实现与评估
- 基于JSP的RSS阅读器的设计与实现方法(推荐)
- [Spark机器学习]基于Spark 2.0 机器学习之推荐系统实现
- [Spark机器学习]基于Spark 2.0 机器学习之推荐系统实现
- 基于机器学习的移动应用推荐系统的研究与实现
- 基于SSDT HOOK技术的Ring0级进程保护组件设计与实现
- 基于JSP的RSS阅读器的设计与实现方法(推荐)
- Android HAL实现的三种方式(2) - 基于Service的HAL设计 推荐
- [Spark机器学习]基于Spark 2.0 机器学习之推荐系统实现
- 程序代写综合推荐-基于JSP技术的学生宿舍管理系统的设计与实现等程序代写
- 机器学习—— 基于深度学习的推荐系统的实现
- Android HAL实现的三种方式(1) - 基于JNI的简单HAL设计 推荐
- STL实现DFS/BFS算法——基于策略的类设计
- 论坛源码推荐(8月14日):基于高德地图iOS SDK的轨迹回放库,用Swift实现的设计模式
- 基于MIS通用管理组件的GIS信息管理平台设计与实现 推荐
- 基于Android移动终端的微型餐饮管理系统的设计与实现3-技术整合
- 基于SNMP数据采集模块的设计和实现2
- WebApi系列~基于单请求封装多请求的设计~请求的安全性设计与实现
- 基于GPS 和GSM的农场短信中心的设计与实现