关于堆排序(参考自算法导论)
2012-05-30 13:51
295 查看
堆排序是一种很有用的排序算法,有用的并不是在排序上的用处,而是那个大根堆和小根堆的建立,在平时的运用中,举足轻重!一个最有用的实例就是操作系统的进程的最大优先权调度算法。从很多进程中,找到优先级最大的进程,然后分配CPU资源。堆排序的主要步骤也就是创建堆。一旦最大堆(最小堆)创建好了,排序也是十分简单的事情了。下面的我们全部以大根堆来做讲解
堆是一种数据结构,可以理解成为一种完全二叉树,但是有个苛刻的要求:除了根节点外的所有节点的父节点的值要大于该节点的值。其实就是所有父节点的值要大于子节点的值。比如下图描述的结构:
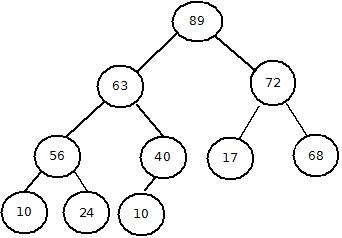
我们有了这种结构之后,就可以确定从堆顶所得到的值一定是最大值,我们可以把最大值换出来,然后再次把我们的结构打乱了的堆重新组合成为标准的大根堆,这就是整个堆排序的过程。堆排序的主要时间也是花在组件堆和重建堆上。
组建堆的过程:
说到最重要的一个子环节:保持最大堆 max_heapify
说明:这个操作可以使堆中的某个节点在其子树满足堆性质的前提下,让它及其子树满足堆的性质。
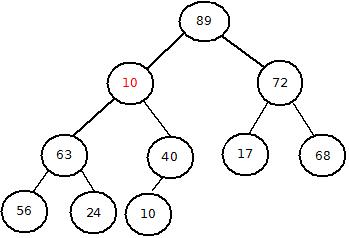
下图的堆中,发现第二个节点不满足堆的性质,且它的子节点对应的子树都是满足堆的性质的,所以进行如下操作,让其重新调整为大根堆
max_heapify:
1)对比节点与其两个子节点,选出值最大的一个节点,如果当前节点不是最大,就把子节点中最大的一个和当前节点进行交换操作
2)由于第一个操作可能让交换节点的那棵子树失去堆的性质,所以对交换后的节点也进行第一布操作,这是一个递归的过程
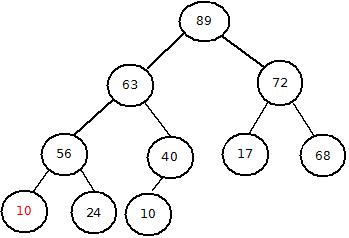
以max_heapify(pos=2)为例的过程如图:
(1、交换节点)

(2、对交换节点进行递归调用)
从上面的操作可以看出,如果我们的子树都是符合大根堆的,则可以依从下往上的的让整个树都变成大根堆。由此特性,我们可以写出让整个树变成大根堆堆的算法:
build_max_heap
ALL)对N/2到1号节点进行max_heapify操作,让整个树变成大根堆。(因为在完全二叉树中只有N/2的节点存在子树其余N/2是叶子)过程我就不再画图了。
以上两步就是组成大根堆的所有过程了,简单吧。接下来就是排序过程了
heap_sort
1)把最后节点和首节点进行交换,得到最大值,放到末尾。
2)从堆中去掉最后一个节点,我们可以用heap_size来表示,heap_size减1即可。对从第一个节点进行max_heapify操作,取得第二大的值。
3)重复1和2操作,依次得到从大到小的所有的值。直到堆只有1个元素为止
具体过程如下:(只针对heap_size为10的情况)
(1、把最后节点和首节点交换,堆大小减1)

(2、堆首节点进行max_heapify操作,重建堆)

下面我们简单的对堆排序进行时间复杂度分析:
max_heapify的时间复杂度为O(lgN)(因为完全二叉树树的高度为lgN,最多只会进行二叉树高度次变换)
build_max_heap操作会N/2次调用max_heapify,则时间复杂度为O(N/2*lgN)
heap_sort操作会N次调用max_heap_fy,则时间复杂度为O(N*lgN)
综合上面,时间复杂度为O(N*lgN)+O(N*lgN)=O(N*lgN)
堆排序的效率还是很高的。至少是比较类的排序算法中最优的。
另外,很容易看出堆排序不是稳定的排序算法,因为如果2个相同的值,不是在一棵子树里面,而是分开的,很可能就把后面的那个值交换到了前面。这不用多说了。
总结:堆排序的主要用处并不是光在于它的排序,而是在于堆的这个性质,最大值或者最小值永远在第一个,而且保持性质的所付出的时间代价很小。这样可以做出很多有用的东西,比如优先级队列就是很好的一个应用。下面附上我自己实现的堆排序的C++源代码。
堆排序源码地址
堆是一种数据结构,可以理解成为一种完全二叉树,但是有个苛刻的要求:除了根节点外的所有节点的父节点的值要大于该节点的值。其实就是所有父节点的值要大于子节点的值。比如下图描述的结构:
我们有了这种结构之后,就可以确定从堆顶所得到的值一定是最大值,我们可以把最大值换出来,然后再次把我们的结构打乱了的堆重新组合成为标准的大根堆,这就是整个堆排序的过程。堆排序的主要时间也是花在组件堆和重建堆上。
组建堆的过程:
说到最重要的一个子环节:保持最大堆 max_heapify
说明:这个操作可以使堆中的某个节点在其子树满足堆性质的前提下,让它及其子树满足堆的性质。
下图的堆中,发现第二个节点不满足堆的性质,且它的子节点对应的子树都是满足堆的性质的,所以进行如下操作,让其重新调整为大根堆
max_heapify:
1)对比节点与其两个子节点,选出值最大的一个节点,如果当前节点不是最大,就把子节点中最大的一个和当前节点进行交换操作
2)由于第一个操作可能让交换节点的那棵子树失去堆的性质,所以对交换后的节点也进行第一布操作,这是一个递归的过程
以max_heapify(pos=2)为例的过程如图:
(1、交换节点)
(2、对交换节点进行递归调用)
从上面的操作可以看出,如果我们的子树都是符合大根堆的,则可以依从下往上的的让整个树都变成大根堆。由此特性,我们可以写出让整个树变成大根堆堆的算法:
build_max_heap
ALL)对N/2到1号节点进行max_heapify操作,让整个树变成大根堆。(因为在完全二叉树中只有N/2的节点存在子树其余N/2是叶子)过程我就不再画图了。
以上两步就是组成大根堆的所有过程了,简单吧。接下来就是排序过程了
heap_sort
1)把最后节点和首节点进行交换,得到最大值,放到末尾。
2)从堆中去掉最后一个节点,我们可以用heap_size来表示,heap_size减1即可。对从第一个节点进行max_heapify操作,取得第二大的值。
3)重复1和2操作,依次得到从大到小的所有的值。直到堆只有1个元素为止
具体过程如下:(只针对heap_size为10的情况)
(1、把最后节点和首节点交换,堆大小减1)
(2、堆首节点进行max_heapify操作,重建堆)
下面我们简单的对堆排序进行时间复杂度分析:
max_heapify的时间复杂度为O(lgN)(因为完全二叉树树的高度为lgN,最多只会进行二叉树高度次变换)
build_max_heap操作会N/2次调用max_heapify,则时间复杂度为O(N/2*lgN)
heap_sort操作会N次调用max_heap_fy,则时间复杂度为O(N*lgN)
综合上面,时间复杂度为O(N*lgN)+O(N*lgN)=O(N*lgN)
堆排序的效率还是很高的。至少是比较类的排序算法中最优的。
另外,很容易看出堆排序不是稳定的排序算法,因为如果2个相同的值,不是在一棵子树里面,而是分开的,很可能就把后面的那个值交换到了前面。这不用多说了。
总结:堆排序的主要用处并不是光在于它的排序,而是在于堆的这个性质,最大值或者最小值永远在第一个,而且保持性质的所付出的时间代价很小。这样可以做出很多有用的东西,比如优先级队列就是很好的一个应用。下面附上我自己实现的堆排序的C++源代码。
堆排序源码地址

相关文章推荐
- 【算法导论】C++参考源码之堆排序中的优先级队列
- 关于 栈(C语言) ——(参考算法导论)
- 关于 队列(C语言) ——(参考算法导论)
- 关于 优先队列(C语言) ——(参考算法导论)
- 快速排序--(参考算法导论p146)
- 【算法导论】堆排序实现
- 【算法导论】堆排序
- 【算法导论】学习笔记——第6章 堆排序
- 【算法导论】第六章之堆排序
- 算法导论-堆排序
- 堆排序(最小堆)--【算法导论】
- 算法导论6.4-4 所有元素均不相同时,最好情况下,堆排序复杂度为Ω(nlgn)
- 关于算法导论15.4的步骤2中为什么可以通过求两者的最大值来合并定理15.1
- 一头扎进算法导论-堆排序
- 【算法导论】之堆排序
- 【算法导论】C++参考源码之队列、二叉树
- 算法导论 习题6.2-5 用迭代法实现堆排序
- 算法导论第六章 堆排序
- 算法导论第六章堆排序(一)
- 算法导论例程——堆排序(大根堆为例)