数据挖掘基础:K-Means算法的原理与Python实现
2012-04-27 11:53
666 查看
数据挖掘基础:K-Means算法的原理与Python实现
原理
K-Means是一种基于样本间相似度量的间接聚类方法,属于非监督学习方法。K-Means接受参数k,将n个数据对象划分为k个聚类。计算每一个数据对象的依据为对象与k个聚类的相似度(或者距离),选择相似度最高的聚类,将这个数据对象划入这个聚类。同时,也需要更新这个聚类的中心点。输入:
k个聚类的中心点的位置;n个数据对象的位置;
输出:
将这n个数据对象划入这k个聚类中,即计算出这k个聚类所属的聚类。计算过程:
1. 计算点p与这k个聚类的距离l1,l2,...,lk,并得到l1,l2,…,lk的最大值lm(设点p与聚类m的距离最近,值为lm)。
如下图所示,共有3个聚类,每一个聚类的中心位置为黑色粗边框的点。现在需要计算点p,也即图中灰色点所属的聚类。计算得到点p与红色聚类的距离为1.2,与蓝色
聚类的距离为2.5,与绿色聚类的距离为3.1。因而,点p应当属于红色聚类。如下图所示:
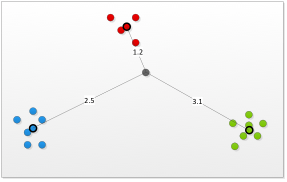
2. 将点p划入到聚类m,并重新计算聚类m的中心点位置。
继续上述示例,点p被划入了红点聚类。从而,红色聚类的中心也发生了变化。如下图所示:
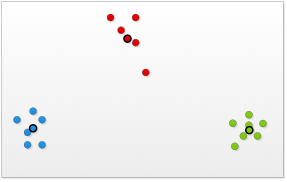
3. 重复以上步骤,直到n个数据对象全部计算完成。
实现
运行前提:
Python运行环境与编辑环境;Matplotlib.pyplot图形库,可用于快速绘制2D图表,与matlab中的plot命令类似,而且用法也基本相同。
代码:
# coding=utf-8 ''' 作者:Jairus Chan 程序:kmeans算法 ''' import matplotlib.pyplot as plt import math import numpy import random #dotOringalNum为各个分类最初的大小 dotOringalNum=100 #dotAddNum最后测试点的数目 dotAddNum=1000 fig = plt.figure() ax = fig.add_subplot(111) sets=[] colors=['b','g','r','y'] #第一个分类,颜色为蓝色,在左下角 a=[] txx=0.0 tyy=0.0 for i in range(0,dotOringalNum): tx=float(random.randint(1000,3000))/100 ty=float(random.randint(1000,3000))/100 a.append([tx,ty]) txx+=tx tyy+=ty #ax.plot([tx],[ty],color=colors[0],linestyle='',marker='.') #a的第一个元素为a的各个元素xy值之合 a.insert(0,[txx,tyy]) sets.append(a) #第二个分类,颜色为绿色,在右上角 b=[] txx=0.0 tyy=0.0 for i in range(0,dotOringalNum): tx=float(random.randint(4000,6000))/100 ty=float(random.randint(4000,6000))/100 b.append([tx,ty]) txx+=tx tyy+=ty #ax.plot([tx],[ty],color=colors[1],linestyle='',marker='.') b.insert(0,[txx,tyy]) sets.append(b) #第三个分类,颜色为红色,在左上角 c=[] txx=0.0 tyy=0.0 for i in range(0,dotOringalNum): tx=float(random.randint(1000,3000))/100 ty=float(random.randint(4000,6000))/100 c.append([tx,ty]) txx+=tx tyy+=ty #ax.plot([tx],[ty],color=colors[2],linestyle='',marker='.') c.insert(0,[txx,tyy]) sets.append(c) #第四个分类,颜色为黄色,在右下角 d=[] txx=0 tyy=0 for i in range(0,dotOringalNum): tx=float(random.randint(4000,6000))/100 ty=float(random.randint(1000,3000))/100 d.append([tx,ty]) txx+=tx tyy+=ty #ax.plot([tx],[ty],color=colors[3],linestyle='',marker='.') d.insert(0,[txx,tyy]) sets.append(d) #测试 for i in range(0,dotAddNum): tx=float(random.randint(0,7000))/100 ty=float(random.randint(0,7000))/100 dist=9000.0 setBelong=0 for j in range(0,4): length=len(sets[j])-1 centX=sets[j][0][0]/length centY=sets[j][0][1]/length if (centX-tx)*(centX-tx)+(centY-ty)*(centY-ty)<dist: setBelong=j dist=(centX-tx)*(centX-tx)+(centY-ty)*(centY-ty) #ax.plot([tx],[ty],color=colors[setBelong],linestyle='',marker='.') sets[setBelong][0][0]+=tx sets[setBelong][0][1]+=ty sets[setBelong].append([tx,ty]) #输出所有的点 for i in range(0,4): tx=[] ty=[] for j in range(1,len(sets[i])): tx.append(sets[i][j][0]) ty.append(sets[i][j][1]) ax.plot(tx,ty,color=colors[i],linestyle='',marker='.') plt.show()
运行效果:

本博客中所有的博文都为笔者(Jairus Chan)原创。
如需转载,请标明出处:http://blog.csdn.net/JairusChan。
如果您对本文有任何的意见与建议,请联系笔者(JairusChan)。

相关文章推荐
- 数据挖掘:K-Means算法的原理与Python实现
- 数据挖掘之k-means算法的Python实现
- 数据挖掘(二)用python实现数据探索:汇总统计和可视化
- 【Python数据挖掘课程笔记】八.关联规则挖掘及Apriori实现购物推荐
- python数据挖掘学习笔记】十四.Scipy调用curve_fit实现曲线拟合
- 数据挖掘(Python)——利用sklearn进行数据挖掘,实现算法:svm、knn、C5.0、NaiveBayes
- 续前篇---数据挖掘之聚类算法k-mediod(PAM)原理及实现
- 基于.NET实现数据挖掘--神经网络算法原理
- ZH奶酪:【数据结构与算法】基础排序算法总结与Python实现
- 常见数据挖掘算法和Python简单实现
- <基础原理进阶>机器学习算法python实现【1】--分类简谈&KNN算法
- 【Python数据挖掘课程】三.Kmeans聚类代码实现、作业及优化
- 续前篇---数据挖掘之聚类算法k-mediod(PAM)原理及实现
- 数据挖掘学习-准备篇-python基础
- 数据挖掘笔记-聚类-Canopy-原理与简单实现
- 数据挖掘之----使用 Python & Flask 实现 RESTful Web API
- 数据挖掘——单层感知器的Python实现
- 【python数据挖掘课程】十四.Scipy调用curve_fit实现曲线拟合
- 数据挖掘分类算法之贝叶斯分类法原理及C++实现
- 数据挖掘 --- Python实现KNN算法项目-约会推荐算法