构建高性能的web站点学习笔记四------浏览器缓存
2012-04-17 17:34
423 查看
1.为什么使用浏览器缓存
以前了解的动态脚本加速,或者动态内容缓存之类,他们的原理都是避免服务器重复计算,结果仍保留在服务器端,这样获取数据还得从服务器检索然后传送到用户浏览器,如果我们把这些结果放在浏览器中,就省去了服务器的查找和网络传输,浏览器缓存很好的实现了这个功能
2.浏览器缓存存放在哪
浏览器一般会在用户主机中创建一个目录,用来保存缓存文件,有的浏览器会将部分缓存放在内存中,这样又对性能有了很大的提升,省去了浏览器向缓存目录的查找工作
3.不管是服务器端缓存还是浏览器端缓存,都需要创建,判断是否过期等一系列工作;那么浏览器缓存是怎样完成这些工作的呢?
我们只掉动态内容缓存的内容创建,存储,以及过期检查等一系列操作都是在服务器端完成,但是浏览器缓存是由服务器生成内容,有浏览器存储到本地,任何一方都不能完成所有操作,他们需要一种沟通机制,这就是HTTP的“缓存协商”
缓存协商
缓存协商的过程,用户通过浏览器向服务器端发送请求页面,服务器端返回请求结果,并告诉浏览器,哪些内容可以缓存,浏览器将可以缓存的内容存储起来,下次请求这个内容时,他便不会直接向服务器请求完整的内容,而是询问服务器是否可以使用本地缓存,服务器接受到浏览器的询问,然后决定是否允许客户端使用本地缓存,不可以的话就将最新内容传送给浏览器
几个问题
服务器怎样,在哪规定哪些内容可以缓存,哪些不可以? 这个问题我没弄清楚,希望哪位牛人能给讲解一下
服务器根据什么判定浏览器是否可以使用本地缓存?
比较常用的方法是通过最后修改时间来判断缓存是否过期,静态网页一般Web服务器会自动为其生成过期时间,动态页面必须我们通过代码控制,我们需要在被请求的页面中添加header("Last-Modified:".gmdate("D,d M Y H:i:s")."GMT");这意味这我们给动态内容增加了一些HTTP响应头信息,我们通过HTTP Watch工具刷新浏览器看一下服务器端返回的请求里面多出了

我们再此请求该页面,看一下浏览器发出的请求

可见浏览器接收到服务器端的暗示,并在下次请求内容首先询问“我请求的内容在这个时间之后是否有更新”,这是服务器就需要根据这个时间判断文件是否更新(是否修改),可是web服务器却无法胜任这些工作,还得我们通过代码控制,我们再访问的页面中添加

可能大家的发现了这里的修改并非真正的文件修改,而是在原来的基础上加一个时间值
彻底消灭请求
可能大家发现了,虽然上面提到根据Last_Modified判断缓存是否过期,我们还是需要向服务器端发送询问,可不可以在本地判断缓存是否过期呢?其实HTTP还有一个属性Expires ,它定义了一个绝对过期时间,它更像个授权者,浏览器一旦发现他的存在就会自动验证缓存是否过期,Web服务器默认不开启此功能,我们需要进行相应的配置 Apache配置如下
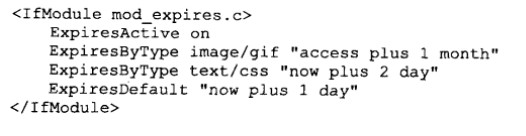
第二行功能开启Expires功能
后三行设置不同的类型的设定绝对过期时间,都采用access plus语法
添加Expires标记

然后我们再跟踪浏览器请求
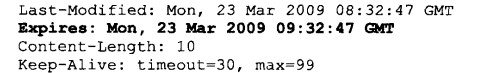
目前还存在一个问题,Expires指定的过期时间使用的是服务器端的过期时间,如果和客户端时间不一致的话,就会影响本地缓存的有效期检查
例如如果我们设置的过期时间是1小时,可是客户端的时间比服务器短时间快2个小时,那么直接就过期了。
怎样解决这个问题呢?幸好HTTP/1.1中还有一个标记用于弥补Experis的不足,他就是Cache-Control,他的格式如下
Cache-Control:max-age=<second>
max-age指定了相对过期时间,单位是秒,并且这个时间是相对客户端浏览器而言的
对于静态页面,Web服务器在开启Expires的情况下,会自动响应Cache-Control的,和上面一样,动态页面必须手动代码添加

目前浏览器做的很好,如果HTTP响应头中既有Expires也有Cache-Control的时候会优先考虑Cache-Control,对于没有Cache-Control则会按照expires

下面说下浏览器刷新方式
Ctrl+F5 或者按着Ctrl键单击刷新按钮,强制刷新网页内容,跳过浏览器
以前了解的动态脚本加速,或者动态内容缓存之类,他们的原理都是避免服务器重复计算,结果仍保留在服务器端,这样获取数据还得从服务器检索然后传送到用户浏览器,如果我们把这些结果放在浏览器中,就省去了服务器的查找和网络传输,浏览器缓存很好的实现了这个功能
2.浏览器缓存存放在哪
浏览器一般会在用户主机中创建一个目录,用来保存缓存文件,有的浏览器会将部分缓存放在内存中,这样又对性能有了很大的提升,省去了浏览器向缓存目录的查找工作
3.不管是服务器端缓存还是浏览器端缓存,都需要创建,判断是否过期等一系列工作;那么浏览器缓存是怎样完成这些工作的呢?
我们只掉动态内容缓存的内容创建,存储,以及过期检查等一系列操作都是在服务器端完成,但是浏览器缓存是由服务器生成内容,有浏览器存储到本地,任何一方都不能完成所有操作,他们需要一种沟通机制,这就是HTTP的“缓存协商”
缓存协商
缓存协商的过程,用户通过浏览器向服务器端发送请求页面,服务器端返回请求结果,并告诉浏览器,哪些内容可以缓存,浏览器将可以缓存的内容存储起来,下次请求这个内容时,他便不会直接向服务器请求完整的内容,而是询问服务器是否可以使用本地缓存,服务器接受到浏览器的询问,然后决定是否允许客户端使用本地缓存,不可以的话就将最新内容传送给浏览器
几个问题
服务器怎样,在哪规定哪些内容可以缓存,哪些不可以? 这个问题我没弄清楚,希望哪位牛人能给讲解一下
服务器根据什么判定浏览器是否可以使用本地缓存?
比较常用的方法是通过最后修改时间来判断缓存是否过期,静态网页一般Web服务器会自动为其生成过期时间,动态页面必须我们通过代码控制,我们需要在被请求的页面中添加header("Last-Modified:".gmdate("D,d M Y H:i:s")."GMT");这意味这我们给动态内容增加了一些HTTP响应头信息,我们通过HTTP Watch工具刷新浏览器看一下服务器端返回的请求里面多出了
我们再此请求该页面,看一下浏览器发出的请求
可见浏览器接收到服务器端的暗示,并在下次请求内容首先询问“我请求的内容在这个时间之后是否有更新”,这是服务器就需要根据这个时间判断文件是否更新(是否修改),可是web服务器却无法胜任这些工作,还得我们通过代码控制,我们再访问的页面中添加
可能大家的发现了这里的修改并非真正的文件修改,而是在原来的基础上加一个时间值
彻底消灭请求
可能大家发现了,虽然上面提到根据Last_Modified判断缓存是否过期,我们还是需要向服务器端发送询问,可不可以在本地判断缓存是否过期呢?其实HTTP还有一个属性Expires ,它定义了一个绝对过期时间,它更像个授权者,浏览器一旦发现他的存在就会自动验证缓存是否过期,Web服务器默认不开启此功能,我们需要进行相应的配置 Apache配置如下
第二行功能开启Expires功能
后三行设置不同的类型的设定绝对过期时间,都采用access plus语法
添加Expires标记
然后我们再跟踪浏览器请求
目前还存在一个问题,Expires指定的过期时间使用的是服务器端的过期时间,如果和客户端时间不一致的话,就会影响本地缓存的有效期检查
例如如果我们设置的过期时间是1小时,可是客户端的时间比服务器短时间快2个小时,那么直接就过期了。
怎样解决这个问题呢?幸好HTTP/1.1中还有一个标记用于弥补Experis的不足,他就是Cache-Control,他的格式如下
Cache-Control:max-age=<second>
max-age指定了相对过期时间,单位是秒,并且这个时间是相对客户端浏览器而言的
对于静态页面,Web服务器在开启Expires的情况下,会自动响应Cache-Control的,和上面一样,动态页面必须手动代码添加
目前浏览器做的很好,如果HTTP响应头中既有Expires也有Cache-Control的时候会优先考虑Cache-Control,对于没有Cache-Control则会按照expires
下面说下浏览器刷新方式
Ctrl+F5 或者按着Ctrl键单击刷新按钮,强制刷新网页内容,跳过浏览器

相关文章推荐
- 构建高性能的web站点学习笔记四------浏览器缓存
- 构建高性能的web站点学习笔记五------Web服务器缓存
- 构建高性能的web站点学习笔记五------Web服务器缓存
- 构建高性能的web站点学习笔记三------动态内容缓存
- 构建高性能的web站点学习笔记三------动态内容缓存
- 构建高性能的web站点学习笔记二------数据库扩展
- 构建高性能的web站点学习笔记六------反向代理缓存
- 构建高性能的web站点学习笔记一
- 构建高性能的web站点学习笔记二------数据库扩展
- 构建高性能的web站点学习笔记一
- [构建高性能web站点]-笔记1绪论
- 构建高性能Web站点(修订版)笔记
- 建高性能的web站点学习笔记六------反向代理缓存
- JavaWeb_Day10_学习笔记1_response(3、4、5、6、7、8、9)发送状态码、响应、重定向、定时刷新、禁用浏览器缓存、响应字节数据、快捷重定向方法、完成防盗链
- 构建高性能Web站点(笔记八)
- 构建高性能web站点笔记一
- 构建高性能Web站点(笔记六)
- 构建高性能Web站点(笔记七)
- 如何构建高性能web站点之:分布式缓存
- 构建高性能web站点-阅读笔记(一)