为什么Hadoop将一定会是分布式计算的未来?
2012-04-15 10:09
369 查看
为什么Hadoop将一定会是分布式计算的未来?
版权声明:写本文由leftnoteasy发布于http://leftnoteasy.cnblogs.com 本文可以被全部或者部分的使用,但请注明出处,如果有问题,可以联系wheeleast (at) gmail.com, 也可以加我的新浪微博:http://weibo.com/leftnoteasy
前言:
很久没有写写博客了,之前主要是换工作,耽误了很多的时间,让人也变得懒散,不想花大时间来写东西。另外就是也确实没有什么自己都觉得有意思的东西拿来写写,对一般的知识什么的,我比较倾向于往evernote上面记笔记。不过最近对于Hadoop看得比较多,对它的发展也比较关心,最近了解得越多,也就越相信Hadoop的未来,这里写一篇文章与大家分享分享,为什么我相信Hadoop一定是分布式计算的未来。
写在前面的话:
今天听同事分享了一篇很有意思的讲座,叫做"Why Map-Reduce Is Not The Solution To Your Big-Data Problem"(为什么Map-Reduce不是你的“大数据”问题的解决方案)。同事很牛,也分享了很多非常有价值的观点,不过他预言Map-Reduce将会在5年之内消失(而且还呼吁有做存储方面的牛人来预言一下,Hdfs将在5年之内消失),这个话题如果成立的话,让我这个目前在Hadoop工程师,感到无比的压力。这里不为了争个你死我活,只是谈谈自己的一些想法。另外由于这位同事的分享是内部进行的,这里就不透露分享中具体的内容了,只谈谈自己的观点。
(本文需要对Hadoop有一定的基础方可理解)
Hadoop为何物?
虽说Hadoop的名声很大,但是总还是有同学不太了解的,这里一笔带过一下。
Google分布式计算三驾马车:
Hadoop的创始源头在于当年Google发布的3篇文章,被称为Google的分布式计算三驾马车(Google还有很多很牛的文章,但是在分布式计算方面,应该这三篇的影响力最大了):http://blog.sina.com.cn/s/blog_4ed630e801000bi3.html,链接的文章比我介绍得更清晰,当然最好还是看看原文了,这是做分布式系统、分布式计算的工程师必修课。
Google File System用来解决数据存储的问题,采用N多台廉价的电脑,使用冗余(也就是一份文件保存多份在不同的电脑之上)的方式,来取得读写速度与数据安全并存的结果。
Map-Reduce说穿了就是函数式编程,把所有的操作都分成两类,map与reduce,map用来将数据分成多份,分开处理,reduce将处理后的结果进行归并,得到最终的结果。但是在其中解决了容错性的问题。
BigTable是在分布式系统上存储结构化数据的一个解决方案,解决了巨大的Table的管理、负载均衡的问题。
Google就靠着这几样技术,在搜索引擎和广告方面取得了举世瞩目的成就。不过Google不是傻的,这三篇文章虽然都是干货,但是不是直接就可以用的。话说Google发表了这三篇文章后,在学术界引起了轩然大波,大家对这三样东西提起了浓厚的兴趣,都想着是不是可以实现一下,以为己用。
Doug Cutting:
Doug Cutting之前是一个非常有名的开源社区的人,创造了nutch与lucene(现在都是在Apache基金会下面的),nutch之前就实现了一个分布式的爬虫抓取系统。等Google的三驾马车发布后,Doug Cutting一看,挖靠这么厉害的技术,于是就实现了一个DFS(distributed file system)与Map-Reduce(大牛风范啊),集成进了Nutch,作为Nutch的一个子项目存在。那时,是2004年左右。
在互联网这个领域一直有这样的说法:
“如果老二无法战胜老大,那么就把老大赖以生存的东西开源吧”
当年与Google还是处在强烈竞争关系的Yahoo!于是招了Doug兄进来,把老大赖以生存的DFS与Map-Reduce开源了。开始了Hadoop的童年时期。差不多在2008年的时候,Hadoop才算逐渐成熟。
现在的Hadoop:
现在的Hadoop不仅是当年的老二Yahoo的专用产品了,从Hadoop长长的用户名单中,可以看到Facebook,可以看到Linkedin,可以看到Amazon,可以看到EMC, eBay,Tweeter,IBM, Microsoft, Apple, HP...(后面的一些未必是完全使用)。国内的公司有淘宝、百度等等。
我来定义一下Hadoop:
Hadoop是一套开源的、基础是Java的、目前能够让数千台普通、廉价的服务器组成一个稳定的、强大的集群,使其能够对pb级别的大数据进行存储、计算。已经具有了强大稳定的生态系统,也具有很多使用的延伸产品。比如做查询的Pig, 做分布式命名服务的ZooKeeper, 做数据库的Hive等等。
为什么世界上只有一个Hadoop?
我的前公司是国内某一个著名互联网公司的子公司,专注做云计算,我也在这个公司最兴盛的时候进入,当时宣传的口号是“做最好的云计算”,就是希望自己开发一套存储计算系统(就是类似于前面提到过的dfs与map-reduce),并且克服一些Hadoop的缺点(比如说用c++去实现,克服Java的一些性能问题)。后来结局可能大家也猜到了,投入了很多钱,招了不少牛人,确实也做出了还算不错的云计算(至少在国内是数一数二的)。但是最终不管从稳定性还是效率上还是scalable来说,都远远被Hadoop甩在了后面。虽然我前公司这个云计算项目是否会成功,这里没办法预测,但是前途终究还是比较黯淡的。
最近一年还听说国内不少的互联网巨头都成立了云计算部门,做“自己的”云计算,有些小得像创业时期一样的公司,都宁愿自己写一套map-reduce框架,不愿意直接使用Hadoop。可能这个跟国人的想法,武功秘笈一定要自己藏着,不让别人学,传男不传女。对别人白给你的东西,非常不放心,觉得大家都能学到的东西,肯定竞争力是不够的。
除开心态问题不谈,但从技术实力上来说,一般国内公司的核心开发团队的能力和当年的Yahoo!比,还是有非常大的差距的,至少像是Doug兄这样的大牛是很罕见的,从开发者的实力来说,就差了不止一个档次。
其次从积累来说,Hadoop从初创到现在也经过了至少7年的积累的,碰到过很多刁钻客户的问题都慢慢克服了(比如Facebook的超大数据存储),带给用户的经验教训是很充足的,比如说性能调优这一块,就有非常多的文章去介绍。而自己开发一个,什么都需要从头再来。
最后也是最重要的是,Hadoop形成了一个强大稳定的生态系统,里面有生产者(共享改进的代码、fix bug),也有消费者(使用项目并且反馈经验),Hadoop的用户也可以获得较大的经济利益(不花钱买软件,还可以增加效率)。对于一个开源社区来说,构建出一个完整的生态系统是非常非常的困难,一旦构造出来了,项目就会很稳定的往前去进步。
Hadoop的优势
之前分析了一些“虚”的东西,比如生态系统什么的,这里说说一些实际的东西。
Benchmark:
Hadoop现在保持了很多漂亮的记录:
存储:现在世界上最大的Hadoop集群目前在Facebook,可以存储30PB的数据
计算:Hadoop是目前Terasort记录的保持者(参见:http://sortbenchmark.org/),Terasort是给出1TB的随机数据,看谁能够在最短的时间内完成排序,Hadoop使用了1400多个节点,在2分钟内完成1T的数据排序。
这里顺便说一下,之前给出网站里面有很多的benchmark,可以看到Hadoop的集群是最大的,使用的机器最多的,像是TritonSort这样的集群,使用了区区50多个节点,最终的结果并不比Hadoop差太多,但是这里得注意一下。TritonSort是专门用来做排序的,里面加入了相当多的优化,但是Hadoop是一个通用的集群,并没有为了一种任务进行如此多的优化。从用户的角度上来说,愿意花钱去买一个只会排序的电脑是意义不那么大的。

注:左右两边属于两种不同的terasort,hadoop是其中一种的记录保持者
能做什么?
前面说的基本的存储和计算Hadoop是一定能胜任的,下面谈谈一些“高级”的功能。
常见的数据库操作,比如orderby、select这样的操作都可以的,Hive就是支持这样的Sql模型,能够将Sql语句最终转化到Map-Reduce程序中去。其性能和可用性已经得到了证明,Facebook就用它做了不少的数据分析的工作
常见的机器学习、矩阵分析算法,目前Mahout作为一个发展迅速的项目,在逐渐填补Hadoop在机器学习领域的空白,现在常见的分类、聚类、推荐、主成分分析算法(比如SVD)都已经有相应的Map-Reduce实现了。虽然目前从用户群和效率上来说是不够的,但是从它的发展来说应该会很快的达到工业界的标准
Hadoop的劣势
现在Hadoop依然有很多的问题没有解决,这让有些人非常的怀疑Hadoop的未来,这里谈谈Hadoop的一些重要的劣势
HA(High Availability)高可用性:
这一点是Hadoop非常弱的一个缺点,不管是Hdfs还是Map-reduce,都是采用单master的方式,集群中的其他机器都是与一台中心机器进行通信,如果这个中心机器挂了,集群就只有不工作了(不一定数据会丢失,但是至少需要重启等等工作),让可用性变得更低。这个一般叫做单点失败(single point of failure,SPOF)。
虽然现在有些公司已经给出了解决方案,比如EMC就有用Vmware搭建虚拟集群,对master节点进行镜像备份,如果master挂掉,那么立刻换上镜像备份的机器,使其可用性变高,不过这个终究不是一个内置的解决方案,而且Vmware这一套东西也并不便宜。
不过之后这个问题将会得到非常好的解决,我在Hadoop的未来这一章将说以说。
Hadoop目前解决得不那么好的一些算法:
Join等:
Map-Reduce还有一个问题是,对于Join这个最常见的数据库操作,支持力度还是不够,特别是针对那种上TB的数据,Join将会很不给力,现在已经有了一些解决方案,比如说SIGMOD'2010的这篇文章:
A Comparison of Join Algorithms for Log Processing in MapReduce
不过在现在的情况下,只有尽量的避免大数据库的Join操作
需要进行很多轮迭代、循环的算法:
对于循环,Map-Reduce稍好,比如矩阵计算,高斯消元法这样的,循环的次数的确定的算法,实现起来还是不难,只是有点慢。但是迭代就更麻烦了,因为现在的Map-Reduce的mapper和reducer是不太方便去弄这样的终止条件。
还有就是迭代次数超多的算法(比如说矩阵的SVD分解),在超大矩阵的情况下,迭代次数可能会上亿次。而Map-Reduce在每次迭代的时候都会把数据往文件里面读写一遍,这样的浪费的时间是巨大的。
其实Map-Reduce不是绝对没有办法去解决这些问题,而只是现在这个还不是最重要的日程,Hadoop还有很多很多的东西可以优化,比如说前面提到的HA,这些东西只有往后放放,我将在之后的Hadoop的未来部分,谈谈未来版的Hadoop怎么去解决这些问题。
编程复杂,学习曲线陡峭:
对于一般的map-reduce框架,hello world程序就变成了word count,就是给出一堆的文本文件,最终统计出里面每一个不同的单词出现的次数,这样一个简单的任务(可能在linux shell下一行就写出来了),在Map-reduce中需要几十行,一般新人从理解word count到写出自己的word count,到跑通,一个星期是肯定需要的。这样陡峭的学习曲线让许多人难以深入。
另外还有一点Hadoop被人所诟病的是,代码丑陋,虽然Hadoop是用高级语言Java写成的,但是里面对每一个步骤都要分成mapper和reducer,这个被戏称为新时代的汇编语言。
一般来说,做数据分析的人程序都写得不咋地(强哥这样的达人除外),能写写matlab,R,或者spss就差不多了,如果要让他们去写map-reduce,那就等于叫他们别干活了。而大数据的重要的作用就是用来做数据分析,Hadoop的未来发展必须得抓住这群数据分析师的心。
其实现在已经有一些实验中的产品,让用户可以用高级语言编程,不会再看到丑丑的map-reduce了。我在前公司的时候就与团队一起做了还不错的尝试,至少,数据分析师可以用Python来编程了。map-reduce变成了一个底层的东西,现在不是某些人在分析性能的时候就贴上汇编代码吗,之后可能会变成在前段的程序效率不行的时候,就贴上后端Java的map-reduce程序。
所以对这个难题之后肯定会解决掉,底层分布式程序开发与用户将被清楚的分开,之后想要写word-count一定会像hello world一样简单。
Hadoop的未来怎么样?
http://www.slideshare.net/hortonworks/apache-hadoop-023 (hadoop 0.23)
给出这样的一个官方文档,谈谈之后的hadoop的发展。目前的hadoop的稳定版是0.20.x,这个0.23是个未来版,估计将在今年的Q4进行beta的发布(目前看起来,至少代码是写了很多了) 。
HDFS Federation
首先是一个叫做HDFS Federation的东西,它将hdfs的命名空间进行了扩展,目前的HDFS的所有文件的meta信息都保存在一台机器的内存中,使得HDFS支持的文件数目是有限的,现在进行了这样改动后,将hdfs的命名空间做成了分布式的,对之后方便对不同的用户文件夹进行管理,还有从HDFS的实现上来说,都会更为简单。
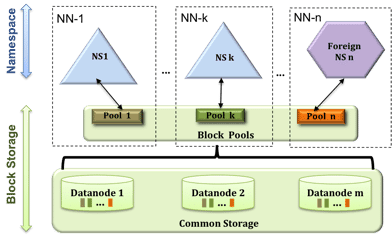
下一代的Map-Reduce:
节点数:从目前的4000增加到6000-10000台
并发的任务数:从目前的40000增加到100000
更高级的硬件支持,目前支持的硬件主要是8core, 16G ram, 4T disk, 之后将会支持16+core, 48/96G ram, 24/48T disk
架构的改变,对现在的JobTracker-TaskTracker的结构做了很大的改进,现在会用ZooKeeper去保存master的状态,避免了之前提到的SPOF
更多的编程模式的支持(这个很重要)
比如MPI,迭代程序的处理,并且在Hadoop中运行这些类型的编程模式,并且这些程序将会被Hadoop统一管理
总结:
之前谈了Hadoop的优势、劣势等等,综合来说就是,优势是很明显的(比如这么多牛公司在用,并且也贡献了很多的代码),远远超出了其他的分布式系统,劣势虽然不小,但是改进这些不足的地方是在计划中,已经在实施了。而且Hadoop不仅在学术界或者是工业界,都有很高的地位,综合了这些天时地利人和,那前途还是非常光明的
分类:
分布式存储,
Hadoop
标签: Hadoop,
分布式计算,
map-reduce
绿色通道:好文要顶关注我收藏该文与我联系

LeftNotEasy
关注 - 15
粉丝 - 185
+加关注
13
0
(请您对文章做出评价)
«
博主前一篇:PyMining-开源中文文本数据挖掘平台 Ver 0.2发布
»
博主后一篇:上海Hadoop开发者聚会(EMC赞助,众多业界内资深专家参加)
posted on 2011-08-27 10:53
LeftNotEasy 阅读(6406)
评论(12)
编辑
收藏
评论
2257122#1楼
2011-08-27 15:00
zhuangzhuang1988
NB 回复 引用 查看 #2楼
2011-08-27 18:30
qiang.xu
感觉作者没有将关键的问题将出来 Why Map-Reduce Is Not The Solution To Your Big-Data Problem 回复 引用 查看 #3楼
2011-08-28 13:38
蛋蛋拜尔
引用qiang.xu:感觉作者没有将关键的问题将出来 Why Map-Reduce Is Not The Solution To Your Big-Data Problem
确实 倒是对Hadoop有了点了解 回复 引用 查看
#4楼[楼主]
2011-08-28 14:23
LeftNotEasy
@qiang.xu呵呵,谢谢你的意见,不过本文的目的并不是要说明"Why Map-reduce is not the solution to your big-data problem", 而是想说明"Why Map-reduce is the future of distributed computing", 之前那个why ... not 的论点由于是公司的内部分享,所以这里就不方便提太多 回复 引用 查看
#5楼
2011-08-30 09:38
mdyang
楼主咱俩是一个公司的啊,上周五我也听了这个报告。你说的前公司那个C++的MapReduce是HCE么? 回复 引用 查看 #6楼[楼主]
2011-08-30 22:50
LeftNotEasy
@mdyang呵呵,我知道你是北京CoE的intern吧,上次好像在园子里跟你聊过的。之前不是HCE 回复 引用 查看
#7楼
2011-08-31 11:36
mdyang
是的,我在Labs China这边做intern. 接下来就要找工作了,想请教前辈:我想做MapReduce、Big Data这块的东西,可以拿到并且是这一块的offer有百度、腾讯、淘宝、阿里云(后面可能还会有EMC),以您了解的情况,哪些现在做得比较好,也比较有前途? 回复 引用 查看 #8楼[楼主]
2011-08-31 18:48
LeftNotEasy
@mdyang呵呵,最好肯定是能拿EMC了,国内这几家公司我其实不太看好。不过如果在淘宝做大数据还是不错的,毕竟他们有平台也有数据。阿里云现在状态不好。百度和腾讯就不太了解了,呵呵~
你现在在Labs China这边做什么方向的工作呢 回复 引用 查看
#9楼
2011-08-31 20:55
mdyang
@LeftNotEasy多谢前辈指点咯~我参加的项目是并行关系数据库,做sharding算法。我们这个项目貌似和Greenplum还有Aurora那边关系大一点。公司的Hadoop项目有些了解,感觉很不错,我努力争取了。 回复 引用 查看
#10楼[楼主]
2011-08-31 21:41
LeftNotEasy
@mdyang你现在的方向也很好啊,数据库也非常有前途啊,做其实大型的这种系统都很有学习的必要,我现在就是在Greenplum的。
虽然在campus hiring中招develop的不太多,但是intern做develop的也不多啊,加油应该很有希望的。 回复 引用 查看
#11楼
2011-11-04 16:02
李克华
很精彩的文章,顶个! 回复 引用 查看 #12楼
2011-11-30 10:16
Roy-豆腐好软
很不错 至少能让我这个菜鸟了解到hadoop的一些基础 回复 引用 查看 刷新评论列表刷新页面返回顶部
注册用户登录后才能发表评论,请
登录 或
注册,访问网站首页。
程序员问答社区,解决您的IT难题
简洁阅读版式
网站首页博问新闻闪存程序员招聘知识库
最新IT新闻:
· 苹果开用iPhone 4S替换送修iPhone 4
· 杜比和飞利浦联手推出全高清裸眼3D技术
· Wintel赴平板饭局 微软英特尔拉厂商对抗苹果
· 点点网推出博客开放平台
· 米聊招聘信息揭示:小米手机将出WP版
» 更多新闻...
最新知识库文章:
·
Facebook工程发布技术的幕后故事
· 使用Phalanger整合PHP和.Net
· 程序员编程生产力相差10倍意味着什么?
· 敏捷开发:如何通过回顾保持学习状态
· 程序员真的很懒
» 更多知识库文章...

China-pub 2011秋季教材巡展
China-Pub 计算机绝版图书按需印刷服务
导航
博客园首页
联系
订阅

管理
我的标签
机器学习(7)搜索引擎(7)
Lucene(6)
machine learning(4)
pymining(3)
mathmatics(3)
人工智能(3)
数据挖掘(3)
PCA(2)
Model Combining(2)
更多
随笔分类
Hadoop(2)(rss)
Lucene C++重写心得(2)
(rss)
Lucene JAVA心得(9)
(rss)
安排,计划,总结(2)
(rss)
分布式存储(2)
(rss)
机器学习(7)
(rss)
结构设计(1)
(rss)
数学(7)
(rss)
随笔档案
2012年2月 (1)2011年9月 (1)
2011年8月 (1)
2011年5月 (5)
2011年3月 (1)
2011年2月 (1)
2011年1月 (3)
2010年12月 (2)
2010年11月 (1)
2010年10月 (1)
2010年9月 (2)
2010年8月 (1)
2010年1月 (12)
2009年12月 (2)
2009年11月 (4)
最新评论
1. Re:PyMining-开源中文文本数据挖掘平台 Ver 0.2发布你好:
十分感谢你的数据挖掘程序,请问一个问题
twc_naive_bayes_train_test_bysample.py 这个测试程序中没有再用 ChiSquareFilter 生成的黑名单,是不再需要了吗?
--shguan2003
2. Re:贝叶斯、概率分布与机器学习
用平方的原因是,平方好算...可能在数学上有可以合并的性质。
--原来你也在
3. Re:贝叶斯、概率分布与机器学习
写的很棒!
--Fuzzy Joke
4. Re:机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
谢谢您的分享,对我很有帮助!
--会飞的瓶子
5. Re:hadoop杂记-为什么会有Map-reduce v2 (Yarn)
顶一个 对于迭代型的算法可能spark更加合适呢 而且能够直接从hdfs读写数据
--Leo Zhang
阅读排行榜
1. 机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用(15038)2. 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)(10926)
3. 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)(9658)
4. 机器学习中的算法(2)-支持向量机(SVM)基础(9283)
5. 机器学习中的数学(3)-模型组合(Model Combining)之Boosting与Gradient Boosting(8892)
评论排行榜
1. 机器学习中的算法(2)-支持向量机(SVM)基础(19)2. 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)(17)
3. 贝叶斯、概率分布与机器学习(17)
4. 机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用(15)
5. 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)(14)
推荐排行榜
1. 为什么Hadoop将一定会是分布式计算的未来?(13)2. 机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用(11)
3. PyMining-开源中文文本数据挖掘平台 Ver 0.1发布(8)
4. 支持中文文本的数据挖掘平台开源项目PyMining发布(8)
5. 机器学习中的算法(2)-支持向量机(SVM)基础(7)
Powered by:
博客园 Copyright © LeftNotEasy

相关文章推荐
- 为什么Hadoop将一定会是分布式计算的未来?
- 为什么Hadoop将一定会是分布式计算的未来?
- 为什么Hadoop将一定会是分布式计算的未来?
- 为什么Hadoop将一定会是分布式计算的未来?
- 为什么Hadoop将一定会是分布式计算的未来
- 为什么Hadoop将一定会是分布式计算的未来?
- 为什么Hadoop将一定会是分布式计算的未来?
- 为什么Hadoop将一定会是分布式计算的未来?
- 为什么Hadoop将一定会是分布式计算的未来?
- [博文精选]为什么Hadoop是分布式计算的未来
- [博文精选]为什么Hadoop是分布式计算的未来
- 为什么hadoop一定是分布式的未来
- 使用 Linux 和 Hadoop 进行分布式计算
- 分布式计算开源框架Hadoop介绍
- Hadoop-- 海量文件的分布式计算处理方案
- 分布式计算开源框架Hadoop入门实践(二)
- 为什么说HDFS是分布式计算的存储基石?
- 分布式计算开源框架Hadoop入门实践(一)
- hadoop MapReduce分布式计算架构
- 分布式计算开源框架Hadoop介绍1