关于__int64类型使用的一点感受
2012-03-20 16:27
274 查看
今天要生成一个20G的单词文件,遇到数据边界的问题,这里记下。
要生成这个20G的文件,我首先从一个文件里面读取了一定量的单词,放在缓冲区里面,然后重复把这个缓冲区写入文件。这里我需要计算出循环的次数,如果这么写:
那么恭喜你,结果是0!
因为在计算20*1024*1024*1024的时候,数据是按照32位来对待的,所以实际上当计算结果大于2^32时,就会发生数据截断.请看下面的截图(来自于调试窗口):

可见上面的计算结果都是被当做int的。一旦数据结果越界,就会发生数据截断。所谓截断实际上是一个内存块的覆盖,多余的部分被舍弃。当你把一个int赋值给char,多出来的部分就被舍弃。这个截断的结果取决于数据原始的类型,比如上面的int,覆盖以后结果仍然是有符号的。上面的结果可以自己画一下数据在内存里面的存储模型,可以得到跟上面一样的结果。
那么如何使上面的计算得到正确的结果呢?答案是让每次计算都不会溢出
把上面的计算乘法改一下就可以实现了:
这里的每次中间运算(1024*1024*1024=2^30 < 2^31-1)都没有超过int的范围
这里出现了__int64类型,通过查看msdn可以得知,他是微软编译器对于64整形的拓展,相应的还有unsigned __int64类型。
注意这两种类型的格式化方式:
__int64 i64;
scanf(“%I64d”, &i64);
printf(“%I64d \n”, &i64);
格式化的形式
在c++中,最好不要使用cout,cin处理__int64,否则结果可能会出现差异,我就遇到输出结果中有字母的情况。相反应该使用c库中的格式化函数处理。
要生成这个20G的文件,我首先从一个文件里面读取了一定量的单词,放在缓冲区里面,然后重复把这个缓冲区写入文件。这里我需要计算出循环的次数,如果这么写:
__int64 k = 20; //20GB的文件需要循环的次数 k = 20 * 1024 * 1024 * 1024 / nStrLen; //nStrLen:缓冲区字符数
那么恭喜你,结果是0!
因为在计算20*1024*1024*1024的时候,数据是按照32位来对待的,所以实际上当计算结果大于2^32时,就会发生数据截断.请看下面的截图(来自于调试窗口):
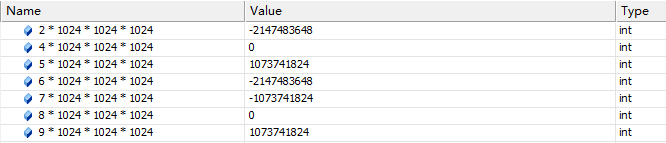
可见上面的计算结果都是被当做int的。一旦数据结果越界,就会发生数据截断。所谓截断实际上是一个内存块的覆盖,多余的部分被舍弃。当你把一个int赋值给char,多出来的部分就被舍弃。这个截断的结果取决于数据原始的类型,比如上面的int,覆盖以后结果仍然是有符号的。上面的结果可以自己画一下数据在内存里面的存储模型,可以得到跟上面一样的结果。
那么如何使上面的计算得到正确的结果呢?答案是让每次计算都不会溢出
把上面的计算乘法改一下就可以实现了:
__int64 k = 20; //20GB的文件需要循环的次数 k *= 1024 * 1024 * 1024; k /= nStrLen; cout << "Loop = " << k << endl;
这里的每次中间运算(1024*1024*1024=2^30 < 2^31-1)都没有超过int的范围
这里出现了__int64类型,通过查看msdn可以得知,他是微软编译器对于64整形的拓展,相应的还有unsigned __int64类型。
注意这两种类型的格式化方式:
__int64 i64;
scanf(“%I64d”, &i64);
printf(“%I64d \n”, &i64);
| 类型 | 使用的前缀 | 指定的类型 |
| __int64 | I64 | d, i, o, x, or X |
| unsigned __int64 | I64 | o, u, x, or X |
%[flags] [width] [.precision] [{h | l | ll | I | I32 | I64}]type在c++中,最好不要使用cout,cin处理__int64,否则结果可能会出现差异,我就遇到输出结果中有字母的情况。相反应该使用c库中的格式化函数处理。

相关文章推荐
- 关于Java Primitive类型与内置Wrapper类型使用过程中的一点小总结
- 关于使用sping MVC框架进行文件上传的一点感受
- 关于Exists使用的一点个人感受
- 关于ArcGIS Runtime SDK for iOS中AGSLayerDefinition使用日期类型字段过滤的问题
- 关于引用对象的使用的一点小理解
- 关于C++类型检查的一点小挫折
- 关于switch语句中使用String类型的实现原理
- 关于mysql数据类型的一点所得
- 使用驱动直写内存时,关于类型需要注意的问题!
- 关于SubSonic3.0插件使用SubSonic.Query.Select查询时,字段类型为tinyint时列丢失问题的Bug修复
- 关于embedded linux的使用、开发、学习的一点自已的体会
- 关于caffe学习系列的一点补充——如何将float类型的特征数据存入lmdb
- 关于字符和数字类型的索引,Oracle如何实现内部自动转换以及索引使用的验证测试
- 关于使用Glide的一点小坑
- 关于音频管理的一点使用
- 关于R.java文件不能自动更新的使用感受
- 关于Windows与Linux下32位与64位开发中的数据类型长度的一点汇总
- 关于泛型的一点应用(数值类型间的转换)
- 关于三层结构的一点使用心得与开发建议
- 关于使用地图 创建 类型数目可控的海量“精灵节点”的优化封装(研究续集)