Linux调度域负载均衡-设计,实现和应用
2011-12-26 09:58
344 查看
转载于黎明的丰收
1.确保每个cpu核心的负载均衡;
2.在cpu和cache以及内存布局的影响下加权执行1。
1.尽量不执行进程迁移,以确保cache的热度;
2.除非各个cpu的负载已经严重失衡,执行负载均衡
这个道理看似简单,然而如果对于一个大型的综合系统,要想设计一个适用于各种情况的负载均衡体系,却不是很简单。Linux内核的负载均衡设计的相当完美。对于负载均衡,可以分为以下几种情况:
以系统复杂度为核心的分类 :
这种情况下,需要随时保持各cpu上运行的进程数量的均衡
这种情况下,进行负载均衡会影响处理器的cache利用率,负载均衡带来的效益会被cache刷新的开销抵消掉一部分或大部分。
这种情况下,情况二是要考虑的,然而对于同一处理器的不同核心之间由于存在共享的二级cache,多个核心之间的负载均衡抵消掉的cache利用率收益远远小于不同处理器之间的负载均衡作同样的事情。
由于超线程使用同一套计算资源,且共享cache,因此其上的负载均衡几乎不会影响cache利用率。然而如果超线程核的调度算法以及操作系统的调度算法设计的不好,造成一个操作系统线程长期使用超线程核,也会造成上一个切换出的操作系统线程的cache被挤出去,遗憾的是,一般情况下我们无力优化操作系统的调度算法,并且无法接触cpu的smt调度算法。
这种情况下,负载均衡对cache利用率的影响显然是不可避免的,同时还会影响访问内存的时间,也就是内存的利用效率,这就是NUMA的情况...
以上五种情况基本就是一个复杂系统从最简单到最复杂的排列,如果我们不以整个系统为核心,而以处理器为核心, 应该是以下四种排列情况:
以处理器为核心的分类:
这是我们熟知的SMT情况
这是我们熟知的多核处理器情况
这是我们熟知的SMP情况
这是我们熟知的NUMA情况,内存对于不同的处理器来讲,其访问效率是不同的。
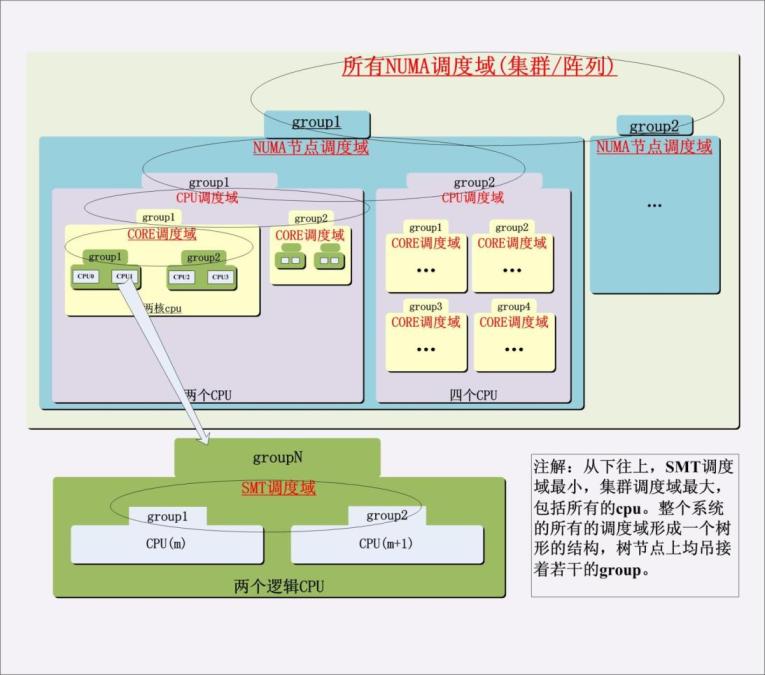
进程在不同cpu之间的迁移和cache利用率总的来说是对立的,并且根据源cpu和目的cpu之间的关系不同这种对立的程度 也不同。 由于进程迁移是基于cpu的,而cpu最小级别的就是超线程处理器的一个smt核,次小的一级就是一个多核cpu的核,然后就是一个物理cpu封装,再往后就是cpu阵列,根据这些cpu级别的不同,Linux将所有同一级别的cpu归为一个“调度组”,然后将同一级别的所有的调度组组成一个“调度域”, 负载均衡首先在调度域的各个调度组之间进行,然后再在最低一级的cpu上进行,注意负载均衡是基于最小一级的cpu的。整个架构如下图所示:
迁移一个进程的代价就是削弱cache的作用。 因此,只要在拥有cache的处理器之间迁移进程,势必会付出这个代价,因此在设计中必然需要一种“阻力”来尽量不做进程迁移,除非万不得已!这种“阻力”就是负载均衡原则2中的“加权”系数。
为防止处理器负载曲线的上下颠簸,用历史值来加权当前值是一个不错的方式 ,也就是说,所谓的负载曲线不再基于时间点 ,而是基于时间段 。 然而历史负载值对总负载的影响肯定没有当前的负载值对总负载的影响大,一个时间点的负载值随着时间的流逝,对负载均衡时总负载的计算的影响应该逐渐减小。因此Linux的负载均衡器设计了一个公式专门用于负载均衡过程中对cpu总负载的计算。该公式如下:
其中delta是一个可变的系数,在linux 2.6.18中设置了3个delta,分别为1,2,4,当然还可以更多,比如高一些版本的内核中delta的取值有CPU_LOAD_IDX_MAX种,CPU_LOAD_IDX_MAX由宏来定义。比如当delta为2的时候,上述公式成为:
total_load=(previous_load+nowa_load)/2
相当于历史值占据整个load值一半,而当前值占据另一半。
让历史值参与计算总负载解决了同一条负载曲线颠簸的问题,但是在负载均衡时是比较两条负载曲线同一时间点上的值 ,当二者相差大于一个阀值时,实施进程迁移。 为了做到“尽量不做进程迁移”这个原则,必须将两条负载曲线的波峰和波谷平滑掉。 如果进程迁移源cpu的负载曲线此时正好在波峰,目的cpu的负载曲线此时正好在波谷,此时就需要将波峰和波谷削平,让源cpu的负载下降a,而目的cpu的负载上升b,这样它们之间的负载差就会减少a+b,这个“阻力”足以阻止很多的进程迁移操作。
负载均衡平滑操作时需要两个值,即上述的a和b,这两个值决定了削平波峰/波谷的幅度,幅度越大,阻碍负载均衡的“力度”也就越大,反之“力度”也就越小。根据参与负载均衡的cpu的层次级别的不同,这种幅度应该不同,幸运的是,可以根据调整“负载均衡过程中对cpu总负载的计算公式”中的delta来影响幅度的大小, 这样,1)和2)就在这点上获得了统一。对于目的cpu,取计算得到的total_load和nowa_load之间的最大值,而对于源cpu,则取二者最小值。可以看出,在公式中,如果delta等于1,则不执行削波峰/波谷操作,这适用于smt的情况,delta越大,历史负载值的影响也就越大,削波峰/波谷后的源cpu负载曲线和目的cpu负载曲线的差值曲线越趋于平滑,这样就越能阻止负载均衡操作(差分算法....)。
Linux在基于调度域进行负载均衡的时候采用的是自下而上的遍历方式,这样就优先在对cache影响最小的cpu之间进行负载均衡,同时这种均衡操作会增加本cpu的负载,反过来在比较高的调度域级别上有力的阻止了对cache影响很大的cpu之间的负载均衡。 我们知道,调度域是从对cache影响最小的最底层向高层构建的。
随着cpu级别的提高,由于负载均衡对cache利用率的影响逐渐增大,“阻力”也应该逐渐加大,因此负载均衡对应调度域使用的delta也应该增加。 算法的根本要点是什么呢?画幅图就一目了然了,delta越大,负载值受历史值的影响越大,因此按照公式所示,只有持续单调递增 的cpu负载,在源cpu选择时才会被选中,偶然一次的高负载并不足以引起其上的进程迁移至别处,相应的,只有负载持续单调递减 ,才会引起其它cpu上的进程迁移至此,这正体现了负载以一个时间段而不是一个时间点为统计周期! 而级别越高的cpu间的进程迁移,需要的“阻力”越大,因此就越受历史值的影响,因为只要历史中有一次负载很小,就会很明显的反应在当前,同样的道理,历史中有一次的负载很大,也很容易反映在当前;反之,所需“阻力”越小,就越容易受当前负载值的影响,极端的情况下,超线程的不同逻辑cpu之间的负载计算公式中delta为1,因此它们的负载计算结果完全就是该cpu的当前负载!
结论有三:
total_load的计算公式实际上使用了一个数列,该数列是一个“等比数列+微扰数列”的和数列, 等比的比值的分母决定着数列的平滑程度,而微扰数列则是cpu的当前真实负载,它根据delta的取值不同对整个cpu的负载影响不同,为了连续化数列,我们设这两个数列为函数f(x)和g(x),证明如下:

不能从delta中得到随着d的增加,阻碍负载均衡的力度将加大这个事实虽然在技术上通过自下而上的遍历方式解决了,然而这使得算法依赖了一个操作方式,这在数学却不是很完美, 因此可以改进,引入一个参数k来微调g(x) ,而不是依赖d来微调,如果配置k和d相等,那么新算法将回退到老算法:

有了新的负载计算公式,我们可以控制一个变量k,然后得知,随着d的增加,负载均衡实际发生的可能性将降低。
view
plain
struct sched_group {
struct sched_group *next; //下一个group指针
cpumask_t cpumask; //该group包含的cpu掩码
unsigned long cpu_power;
};
view
plain
struct sched_domain {
/* These fields must be setup */
struct sched_domain *parent; /* top domain must be null terminated */
struct sched_group *groups; /* the balancing groups of the domain */
cpumask_t span; /* span of all CPUs in this domain */
unsigned long min_interval; /* Minimum balance interval ms */
unsigned long max_interval; /* Maximum balance interval ms */
unsigned int busy_factor; /* less balancing by factor if busy */
unsigned int imbalance_pct; //判断该调度域是否已经均衡的一个基准值。
unsigned long long cache_hot_time; /* Task considered cache hot (ns) */
unsigned int cache_nice_tries; /* Leave cache hot tasks for # tries */
unsigned int per_cpu_gain; /* CPU % gained by adding domain cpus */
unsigned int busy_idx; //忙均衡的cpu_load索引,详见第一部分的“负载均衡算法分析”
unsigned int idle_idx; //空闲均衡的cpu_load索引
unsigned int newidle_idx; //马上就要进入idle的cpu为了尽量不进入idle而进行负载均衡时的cpu_load索引
unsigned int wake_idx; //唤醒进程时将进程拉至本cpu的作用力,也是一个cpu_load索引,该索引也即本地唤醒力,对于支持多队列的网卡有很大的性能增强作用。
unsigned int forkexec_idx;
int flags; /* See SD_* */
/* Runtime fields. */
unsigned long last_balance; /* init to jiffies. units in jiffies */
unsigned int balance_interval; /* initialise to 1. units in ms. */
unsigned int nr_balance_failed; /* initialise to 0 */
...
};
对于每一个最低级别的cpu(比如超线程cpu)依次执行:
view
plain
//初始化物理处理器调度域
p = sd;
sd = &per_cpu(phys_domains, i);
group = cpu_to_phys_group(i);
*sd = SD_CPU_INIT; //宏定义浅拷贝,每一个最低层次的cpu都有一个per cpu项,就是sched_domain,属于同一个sched_domain的各个cpu共享该结构体中的指针数据。
sd->span = nodemask;
sd->parent = p;
sd->groups = &sched_group_phys[group];
//初始化物理处理器的处理器核调度域
p = sd;
sd = &per_cpu(core_domains, i);
group = cpu_to_core_group(i);
*sd = SD_MC_INIT; //宏定义浅拷贝
sd->span = cpu_coregroup_map(i);
cpus_and(sd->span, sd->span, *cpu_map);
sd->parent = p;
sd->groups = &sched_group_core[group];
//初始化SMT逻辑处理器调度域
p = sd;
sd = &per_cpu(cpu_domains, i);
group = cpu_to_cpu_group(i);
*sd = SD_SIBLING_INIT; //宏定义浅拷贝
sd->span = cpu_sibling_map[i];
cpus_and(sd->span, sd->span, *cpu_map);
sd->parent = p;
sd->groups = &sched_group_cpus[group];
其中三个函数返回了cpu在对应级别的编号,用于初始化调度组:
view
plain
static int cpu_to_phys_group(int cpu)
{//cpu核组的第一个cpu的cpu号
cpumask_t mask = cpu_coregroup_map(cpu);
return first_cpu(mask);
}
view
plain
static int cpu_to_core_group(int cpu)
{//逻辑cpu组的第一个cpu的cpu号
return first_cpu(cpu_sibling_map[cpu]);
}
view
plain
static int cpu_to_cpu_group(int cpu)
{//直接返回cpu,这是最底层次的
return cpu;
}
初始化了每一个逻辑cpu的调度域之后,依次初始化每一个调度域的各个调度组
view
plain
for_each_cpu_mask(i, *cpu_map) {
cpumask_t this_sibling_map = cpu_sibling_map[i];
cpus_and(this_sibling_map, this_sibling_map, *cpu_map);
if (i != first_cpu(this_sibling_map)) //仅以共享cpu核或者共享物理cpu的第一个逻辑cpu开始创建该调度域中所有的调度组
continue;
init_sched_build_groups(sched_group_cpus, this_sibling_map, &cpu_to_cpu_group);
}
for_each_cpu_mask(i, *cpu_map) {
cpumask_t this_core_map = cpu_coregroup_map(i);
cpus_and(this_core_map, this_core_map, *cpu_map);
if (i != first_cpu(this_core_map)) //仅以共享物理cpu的第一个cpu核开始创建该调度域中所有的调度组
continue;
init_sched_build_groups(sched_group_core, this_core_map, &cpu_to_core_group);
}
for (i = 0; i < MAX_NUMNODES; i++) {
cpumask_t nodemask = node_to_cpumask(i);
cpus_and(nodemask, nodemask, *cpu_map);
if (cpus_empty(nodemask)) //以一个NUMA节点的所有物理cpu为mask创建该调度域中所有的调度组
continue;
init_sched_build_groups(sched_group_phys, nodemask, &cpu_to_phys_group);
}
该函数初始化了同一调度域中的所有的调度组,逻辑很简单:
view
plain
static void init_sched_build_groups(struct sched_group groups[], cpumask_t span,
int (*group_fn)(int cpu)) //该回调函数就是1.1.1/1.1.2/1.1.3所示的函数
{
struct sched_group *first = NULL, *last = NULL;
cpumask_t covered = CPU_MASK_NONE;
int i;
for_each_cpu_mask(i, span) { //外层循环,创建每一个调度组
int group = group_fn(i);
struct sched_group *sg = &groups[group];
int j;
if (cpu_isset(i, covered))
continue;
sg->cpumask = CPU_MASK_NONE;
sg->cpu_power = 0;
for_each_cpu_mask(j, span) { //内层循环,为每一个调度组添加所有的成员
if (group_fn(j) != group)
continue;
cpu_set(j, covered);
cpu_set(j, sg->cpumask);
}
if (!first)
first = sg;
if (last)
last->next = sg;
last = sg;
}
last->next = first;
}
每次时钟中断时,要判断是否要做负载均衡操作了,具体来讲实现两个逻辑:
view
plain
for (i = 0, scale = 1; i < 3; i++, scale <<= 1) {//在高一些的内核版本中,不再仅设置3个cpu_load值,而是CPU_LOAD_IDX_MAX(#define CPU_LOAD_IDX_MAX 5)个,这样,囊括的策略就更多了。
unsigned long old_load, new_load;
old_load = this_rq->cpu_load[i];
new_load = this_load;
this_rq->cpu_load[i] = (old_load*(scale-1) + new_load) / scale;
}
可见,Linux将3个负载值保存成了数组,随着索引的增加,历史值影响逐渐加大,具体祥见第一部分的分析
view
plain
j = cpu_offset(this_cpu); //不同的cpu对应的j是不同的,j的值实际就是jiffies+cpu*HZ/NR_CPUS
for_each_domain(this_cpu, sd) {
if (!(sd->flags & SD_LOAD_BALANCE))
continue;
interval = sd->balance_interval;
if (idle != SCHED_IDLE)
interval *= sd->busy_factor;
if (j - sd->last_balance >= interval) { //用到了j,可见不同的cpu不会同时对该cpu进行负载均衡
if (load_balance(this_cpu, this_rq, sd, idle)) {
idle = NOT_IDLE; //返回非0,说明成功迁移了进程到本cpu,更新idle
}
sd->last_balance += interval;
}
}
j的设置是巧妙的,由于每次时钟中断都会导致jiffies递增,因此当某个时刻j-sd->last_balance正好等于interval的时候,比该cpu的cpu号大的cpu的结果将是j-sd->last_balance<interval,由此多个cpu同时操作同一个cpu的几率将减少(有效避免了该cpu将别的cpu上的进程拉了过来,然而别的cpu在调用同一函数的时候又将进程拉了回去这种互相扯皮的事情),鉴于随机数的产生会有很大的开销,因此采用了jiffies+cpu*HZ/NR_CPUS这种算法来混乱化执行的时间。 然而,由于对于每一个cpu,balance_interval参数是可以配置的,因此配置不同的balance_interval参数可能会抵消掉这种混乱化操作的结果。
该函数比较复杂,它在同一个调度域的各个调度组之间进行负载均衡,总的来讲分为三块
该函数实现很复杂,然而逻辑很简单,基本策略祥见第一部分的“负载均衡算法分析”。对于代码,实际上就是一个两层的循环加上数据的更新 :
view
plain
do { //外层循环,遍历该调度域的每一个调度组
...
local_group = cpu_isset(this_cpu, group->cpumask);
...
for_each_cpu_mask(i, group->cpumask) { //内存循环,遍历同一调度组的所有cpu,并累加这些cpu的负载
struct rq *rq = cpu_rq(i);
if (*sd_idle && !idle_cpu(i))
*sd_idle = 0;
if (local_group) //我们自己的组,削掉波谷,因为我们尽力在避免迁移进程
load = target_load(i, load_idx);
else //不是我们自己的组,削掉波峰,因为我们尽力避免迁移进程
load = source_load(i, load_idx);
avg_load += load;
sum_nr_running += rq->nr_running;
sum_weighted_load += rq->raw_weighted_load;
}
if (local_group) {
...
} else if (avg_load > max_load &&
...
busiest = group; //在同一层次(即同一调度域),永远不会将自己的组作为最busy的组。在一层是一个组,在其下层可能就是一个组,而调度域的遍历方向是自下而上的,因此这个算法的要点则是认为自己附近的cpu已经均衡过了。一般的第n层的所有的group在第n+1层会恰好组成同一group。
...
}
...
group = group->next;
} while (group != sd->groups);
其中source_load取了cpu_load[delta]和nowa_load的最小值,削掉了波峰,而target_load则相反,削掉了波谷
view
plain
static inline unsigned long source_load(int cpu, int type)
{
struct rq *rq = cpu_rq(cpu);
return min(rq->cpu_load[type-1], rq->raw_weighted_load);
}
static inline unsigned long target_load(int cpu, int type)
{
struct rq *rq = cpu_rq(cpu);
return max(rq->cpu_load[type-1], rq->raw_weighted_load);
}
可以看到,基于调度域的负载均衡是从下往上进行的,这样做的好处在于,每次优先从最底层级别附近pull进程过来,这样对cache的影响最小,比如两个逻辑cpu之间迁移进程对cache的影响就会小到可以忽略。随着调度域的级别的增加以及pull过来的进程增加,本cpu的负载会增加,一般而言,到达物理cpu级别这个调度域,本cpu已经就已经很忙了,因此也就很难再进行负载均衡了,实际上这也是一种阻碍进程迁移的方式。
在最busy的组中寻找最busy的cpu,很简单,就是一次冒泡算法。
迁移进程
内核代码中的注释解决本函数:
We do not migrate tasks that are:
1) running (obviously), or
2) cannot be migrated to this CPU due to cpus_allowed, or
3) are cache-hot on their current CPU.
Aggressive migration if:
1) task is cache cold, or
2) too many balance attempts have failed.
需要注意的是,cache的热度是通过进程离开运行态到现在的时间差来决定的,而这个差的阀值到底是多少,则由调度域的一个cache_hot_time字段决定。
本文不谈这种push模式的进程迁移,同时也不深究所谓的主动均衡和被动均衡,这些在理解了核心算法后都会很简单的。故此处略过
值得注意的是,Linux所实现的调度域和调度组仅仅描述了一个cpu的静态拓扑和一组默认的配置, 这组默认的配置生成的原则就是在第一部分中描述的各种情况的基础上在负载均衡和cache利用率之间产生最小的对抗 ,Linux并没有将这些配置定死,实际上Linux的负载均衡策略是可以动态配置的。
由于负载均衡实现的时候,对调度域数据结构对象使用了浅拷贝 ,因此对于每一个最小级别的cpu,都有自己的可配置参数,而对于所有属于同一调度域的所有cpu而言,它们有拥有共享的调度组,这些共享的信息在调度域数据结构中用指针实现,因此对于调度域参数而言,每个cpu是可以单独配置的。每个cpu都可配置使得可以根据底层级别cpu上的负载情况(负载只能在最底层级别的cpu上)进行灵活的参数配置,还可以完美支持虚拟化和组调度。
目录/proc/sys/kernel/sched_domain 下有所有的最底层级别的cpu目录,比如你的机器上有4个物理cpu,每个物理cpu有2个核心,每个核心都开启了超线程,则总共的cpu数量是4*2*2=16,因此
root@ZY:/proc/sys/kernel/sched_domain# ls
cpu0 cpu1 cpu2 cpu3 cpu4 cpu5 cpu6 cpu7 ...cpu15
root@ZY:/proc/sys/kernel/sched_domain# cd cpu0/
root@ZY:/proc/sys/kernel/sched_domain/cpu0# ls
domain0 domain1 domain2
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain0/name
SIBLING
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain1/name
MC
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain2/name
CPU
root@ZY:/proc/sys/kernel/sched_domain/cpu0# ls domain0/ #以下这些参数都是可配置的,使用sysctl即可,含义见sched_domain结构体
busy_factor cache_nice_tries forkexec_idx imbalance_pct min_interval newidle_idx
busy_idx flags idle_idx max_interval name wake_idx
列举一个性能调优的实例,当我们手工绑定了进程在各自cpu上运行,并且手工平衡了各个cpu的负载,每一个cpu都有特定的任务,比如cpu0处理网络中断和软中断,cpu1处理磁盘IO,cpu2运行web服务,...(暂不考虑dca等对cache的影响),那么也就不希望内核再做负载均衡了,因此需要针对每一个cpu的调度域进行配置,使之不再进行或者“很不频繁”进行负载均衡操作:
root@ZY:/proc/sys/kernel/sched_domain# echo 100000000000 > cpu0/domain1/min_interval
root@ZY:/proc/sys/kernel/sched_domain# echo 100000000000 > cpu0/domain2/min_interval
...//针对cpuX依照上述执行,另外还要设置max_interval,要大于100000000000 。对于domain0,由于它是SMT级别的,因此负载均衡并不会破坏cache,因此不设置。
...//其实还有很多的参数可以设置,比如flags,imbalance_pct,busy_factor等。
注解: 由于fork和exec的行为是不同的,fork后的新进程还是要访问老进程的数据(写时复制),而exec则彻底告别老进程(虽然还可能会访问同样载入老进程的共享库),因此调度域的flags中的SD_BALANCE_FORK和SD_BALANCE_EXEC最好应该区别开来,我们可以通过在SMT或者MC调度域中设置SD_BALANCE_FORK而SMP中不设置SD_BALANCE_FORK来优化fork后的进程的写时复制,至于SD_BALANCE_EXEC则全部支持,不过这样设置的前提是你对你的应用进程的脾气很了解,如果exec后的进程和之前的进程共享大量的在之前之后都大量被读写的共享库的话,说实话SD_BALANCE_EXEC标志也最好不要设置在SMP调度域中。
完全可以使用sysctl配置系统的debug级别或者重新编译内核增加更多的打印信息,然而编写modules导出自己需要的信息一直都是最好的方式,因为它只输出你需要的信息,而内核的debug信息虽然很详细,但是你可能还真的需要花一番功夫才能明白其所以然。
以下是一个内核模块的代码,它揪出了两个cpu的调度域和调度组信息,然后打印出来,这种编写模块的好处在于,你可以做且仅做你需要的,且一切按照你自己的风格来!
view
plain
static struct rq *(*task_rq)(struct task_struct *p, unsigned long *flags);
struct task_struct *(*gettask)(struct pid *pid, enum pid_type type);
struct pid *(*getpid)(pid_t nr);
int __init domain_init(void){
int cpu = 0, i = 0;
struct sched_domain *sd;
task_rq=0xffffffff8103fbc4; //task_rq_lock的地址
getpid = 0xffffffff810626aa; //find_get_pid的地址
gettask = 0xffffffff81062473;//get_pid_task的地址
struct task_struct *t1 = (*gettask)((*getpid)(3), PIDTYPE_PID); //进程3绑在cpu0上
struct task_struct *t2 = (*gettask)((*getpid)(6), PIDTYPE_PID); //进程6绑在cpu1上
unsigned long fl = 0;
struct rq* r = (*task_rq)(t1, &fl); //得到运行队列,注意锁住了运行队列r
spin_unlock_irqrestore(&r->lock, fl);//解锁,这是一定的,否则系统就不能响应了。
for (sd = r->sd; sd; sd = sd->parent) {
struct sched_group *sg, *sgg;
printk("domain address: %p /n", sd);
printk("domain name: %s /n", sd->name);
sg = sd->groups;
sgg = sg;
printk("group address:%p/n", sg);
while (sg->next != sgg) {
sg = sg->next;
printk("group address:%p/n", sg);
}
printk("next domain /n");
}
printk("NEXT CPU /n");
struct rq* r2 = (*task_rq)(t2, &fl);
spin_unlock_irqrestore(&r2->lock, fl);
for (sd = r2->sd; sd; sd = sd->parent) {
struct sched_group *sg, *sgg;
printk("domain address: %p /n", sd);
printk("domain name: %s /n", sd->name);
sg = sd->groups;
sgg = sg;
printk("group address:%p/n", sg);
while (sg->next != sgg) {
sg = sg->next;
printk("group address:%p/n", sg);
}
printk("next domain /n");
}
return 0;
}
void __exit domain_exit(void){
}
module_init(domain_init);
module_exit(domain_exit);
对于一个单物理cpu开启超线程的系统加载上述模块,dmesg得到以下结果:
[63962.546289] domain address: ffff88000180fa20
[63962.546294] domain name: SIBLING
[63962.546297] domain busy: 3
[63962.546300] domain busy: 180fa98
[63962.546303] group address:ffff88000180fae0 #cpu0-第一个逻辑cpu的smt调度域的第一个组,包括它自身(1)
[63962.546306] group address:ffff88000184fae0 #cpu0-第一个逻辑cpu的smt调度域的第二个组,包括它兄弟(2)
[63962.546308] next domain
[63962.546311] domain address: ffff88000180fb30
[63962.546314] domain name: MC
[63962.546316] domain busy: 30
[63962.546319] domain busy: 180fba8
[63962.546321] group address:ffff88000180fbf0
[63962.546324] next domain
[63962.546326] NEXT CPU
[63962.546329] domain address: ffff88000184fa20
[63962.546332] domain name: SIBLING
[63962.546335] domain busy: 0
[63962.546337] domain busy: 184fa98
[63962.546340] group address:ffff88000184fae0 #cpu0-第一个逻辑cpu的smt调度域的第一个组,包括它自身,等于(2)
[63962.546343] group address:ffff88000180fae0 #cpu0-第一个逻辑cpu的smt调度域的第一个组,包括它兄弟,等于(1)
[63962.546345] next domain
[63962.546348] domain address: ffff88000184fb30
[63962.546351] domain name: MC
[63962.546354] domain busy: 2
[63962.546357] domain busy: 184fba8
[63962.546359] group address:ffff88000180fbf0
[63962.546362] next domain
要问关于Linux内核的那些资料最好,我觉得最好的有两个,一个是LKML(Linux kernel
maillist)还有一个就是内核文档,内核文档中的信息相当丰富,涉及了几乎所有的核心功能,因此阅读它们是有帮助的,本文的最后,我尝试将其中《sched-domains.txt》翻译一下,“[]”中的是我的一切注释,注意,以下并不是原文直译,而是意译(信,达,雅三境界中,我可能连“信”都谈不上,因此找个理由,说是意译!)。译文如下:
每一个cpu都拥有一个“base”调度域(struct sched_domain)[注:基本的调度域,也就是最底层的调度域,以下的per-cpu指的就是最底层的cpu]。这些“base”调度域可以通过cpu_sched_domain(i)和this_sched_domain()这两个宏来访问。调度域层次结构从这些“base”调度域开始[注:向上]构建,通过调度域的parent指针可以访问到其上级调度域。parent指针必须是NULL结尾的[注:最高一级别的调度域的parent指针为NULL],调度域是per-cpu的,因为这样可以在更新其字段时,锁的开销更小[注:同时每个调度域也是单独可配置的]。
每一个调度域覆盖一定数量的cpu(存储于span字段)。一个调度域的span必须是其子调度域span的超集。cpui的“base”调度域的span中起码要包含cpui。最顶层的调度域需要覆盖系统所有的cpu,虽然严格来讲这并不是必须的,会导致一些cpu上从来都没有进程运行。调度域的span的含义是“在这些cpu之间进行负载均衡”
每一个调度域必须拥有起码一个cpu调度组(struct sched_groups),这些组组织成一个环形链表,该链表从调度域的groups字段开始。同一个调度域的这些组的cpumasks的并集表示的cpu必须和该调度域的span字段表示的cpu完全相等,同时,属于同一调度域的任意两个组的cpumasks字段的交集必须是空集。一个调度域的调度组覆盖的cpu必须是该调度域所覆盖的。这些调度组的只读数据在cpu之间是共享的。
一个调度域的负载均衡操作发生在其各个调度组之间。此时,每一个调度组被当成了一个整体对待。一个调度组的负载定义为该组中所有的cpu成员的负载之和,并且只有当组与组之间的负载失衡的时候,才会在组与组之间迁移进程。
从源文件kernel/sched.c中可以看出,每一个cpu会周期性的调用rebalance_tick函数。该函数将从该cpu的“base”调度域开始检查该调度域内的进程是否到达了其负载均衡的周期,如果是,则在该调度域调用load_balance,然后在“base”调度域的parent调度域中执行上述操作,这是一个遍历的过程,遍历过程以此类推。
*** 调度域的实现[和定制] ***
“base”调度域将构成调度域层级结构的第一级。举例来讲,在SMT的情况下,“base”调度域覆盖了一个物理cpu的所有逻辑cpu,每一个逻辑cpu构成了一个调度组。SMP的情况下,物理cpu调度域作为“base”调度域的parent,它将覆盖一个NUMA节点中的所有的cpu。其每一个调度组覆盖一个物理cpu。同样的道理,在NUMA情况下,节点调度域作为物理cpu调度域的parent,它将覆盖整台机器的所有cpu,其每一个调度组覆盖一个节点的所有cpu。
实现者需要阅读include/linux/sched.h文件里面关于sched_domain结构体的字段的注释以及SD_FLAG_*和SD_*_INIT来了解更多的细节以及了解如何来调节这些参数从而影响内核负载均衡的行为。
如果你想支持SMT,必须定义CONFIG_SCHED_SMT宏,并且提供一个cpumask_t类型的数组cpu_sibling_map[NR_CPUS],元素cpu_sibling_map[i]的含义是所有和cpui属于同一个物理cpu[或者物理cpu核]的逻辑cpu的掩码,这个掩码中当然也包括cpui本身。
[针对特定的体系结构可以对Linux内核默认的调度域/调度组的默认参数以及设置进行重载,此处不再翻译]
第一部分:Linux负载均衡的设计
一.负载均衡的原则
1.确保每个cpu核心的负载均衡;2.在cpu和cache以及内存布局的影响下加权执行1。
对于一般多核心cpu情况,以上两个原则可以简述为下面的原则:
1.尽量不执行进程迁移,以确保cache的热度;
2.除非各个cpu的负载已经严重失衡,执行负载均衡
二.系统以及cpu的拓扑结构
这个道理看似简单,然而如果对于一个大型的综合系统,要想设计一个适用于各种情况的负载均衡体系,却不是很简单。Linux内核的负载均衡设计的相当完美。对于负载均衡,可以分为以下几种情况:以系统复杂度为核心的分类 :
情况一:cpu无任何cache
这种情况下,需要随时保持各cpu上运行的进程数量的均衡
情况二:多处理器,每个处理器有处理器独享的cache
这种情况下,进行负载均衡会影响处理器的cache利用率,负载均衡带来的效益会被cache刷新的开销抵消掉一部分或大部分。
情况三:多处理器,每个处理器有多个处理器核心,每个核心有独享的一级cache,同一处理器的多个核心有共享的二级,三级cache
这种情况下,情况二是要考虑的,然而对于同一处理器的不同核心之间由于存在共享的二级cache,多个核心之间的负载均衡抵消掉的cache利用率收益远远小于不同处理器之间的负载均衡作同样的事情。
情况四:情况三的前提下,每一个处理器的每一个核心又开启了超线程(Intel术语)。
由于超线程使用同一套计算资源,且共享cache,因此其上的负载均衡几乎不会影响cache利用率。然而如果超线程核的调度算法以及操作系统的调度算法设计的不好,造成一个操作系统线程长期使用超线程核,也会造成上一个切换出的操作系统线程的cache被挤出去,遗憾的是,一般情况下我们无力优化操作系统的调度算法,并且无法接触cpu的smt调度算法。
情况五:情况一到四的前提下,增加不对称内存。
这种情况下,负载均衡对cache利用率的影响显然是不可避免的,同时还会影响访问内存的时间,也就是内存的利用效率,这就是NUMA的情况...
以上五种情况基本就是一个复杂系统从最简单到最复杂的排列,如果我们不以整个系统为核心,而以处理器为核心, 应该是以下四种排列情况:
以处理器为核心的分类:
情况一:单个处理器开启超线程
这是我们熟知的SMT情况
情况二:单个处理器多个核心
这是我们熟知的多核处理器情况
情况三:多个处理器
这是我们熟知的SMP情况
情况四:多处理器,多内存域
这是我们熟知的NUMA情况,内存对于不同的处理器来讲,其访问效率是不同的。
三.负载均衡基础设施以及cpu拓扑结构(静态设施)
进程在不同cpu之间的迁移和cache利用率总的来说是对立的,并且根据源cpu和目的cpu之间的关系不同这种对立的程度 也不同。 由于进程迁移是基于cpu的,而cpu最小级别的就是超线程处理器的一个smt核,次小的一级就是一个多核cpu的核,然后就是一个物理cpu封装,再往后就是cpu阵列,根据这些cpu级别的不同,Linux将所有同一级别的cpu归为一个“调度组”,然后将同一级别的所有的调度组组成一个“调度域”, 负载均衡首先在调度域的各个调度组之间进行,然后再在最低一级的cpu上进行,注意负载均衡是基于最小一级的cpu的。整个架构如下图所示:
四.负载均衡算法分析(动态表现)
迁移一个进程的代价就是削弱cache的作用。 因此,只要在拥有cache的处理器之间迁移进程,势必会付出这个代价,因此在设计中必然需要一种“阻力”来尽量不做进程迁移,除非万不得已!这种“阻力”就是负载均衡原则2中的“加权”系数。
1).历史负载值的影响
为防止处理器负载曲线的上下颠簸,用历史值来加权当前值是一个不错的方式 ,也就是说,所谓的负载曲线不再基于时间点 ,而是基于时间段 。 然而历史负载值对总负载的影响肯定没有当前的负载值对总负载的影响大,一个时间点的负载值随着时间的流逝,对负载均衡时总负载的计算的影响应该逐渐减小。因此Linux的负载均衡器设计了一个公式专门用于负载均衡过程中对cpu总负载的计算。该公式如下:
total_load=(previous_load*(delta-1)+nowa_load)/delta
其中delta是一个可变的系数,在linux 2.6.18中设置了3个delta,分别为1,2,4,当然还可以更多,比如高一些版本的内核中delta的取值有CPU_LOAD_IDX_MAX种,CPU_LOAD_IDX_MAX由宏来定义。比如当delta为2的时候,上述公式成为:total_load=(previous_load+nowa_load)/2
相当于历史值占据整个load值一半,而当前值占据另一半。
2).波峰/波谷的平滑化
让历史值参与计算总负载解决了同一条负载曲线颠簸的问题,但是在负载均衡时是比较两条负载曲线同一时间点上的值 ,当二者相差大于一个阀值时,实施进程迁移。 为了做到“尽量不做进程迁移”这个原则,必须将两条负载曲线的波峰和波谷平滑掉。 如果进程迁移源cpu的负载曲线此时正好在波峰,目的cpu的负载曲线此时正好在波谷,此时就需要将波峰和波谷削平,让源cpu的负载下降a,而目的cpu的负载上升b,这样它们之间的负载差就会减少a+b,这个“阻力”足以阻止很多的进程迁移操作。
3).负载曲线平滑操作的基准
负载均衡平滑操作时需要两个值,即上述的a和b,这两个值决定了削平波峰/波谷的幅度,幅度越大,阻碍负载均衡的“力度”也就越大,反之“力度”也就越小。根据参与负载均衡的cpu的层次级别的不同,这种幅度应该不同,幸运的是,可以根据调整“负载均衡过程中对cpu总负载的计算公式”中的delta来影响幅度的大小, 这样,1)和2)就在这点上获得了统一。对于目的cpu,取计算得到的total_load和nowa_load之间的最大值,而对于源cpu,则取二者最小值。可以看出,在公式中,如果delta等于1,则不执行削波峰/波谷操作,这适用于smt的情况,delta越大,历史负载值的影响也就越大,削波峰/波谷后的源cpu负载曲线和目的cpu负载曲线的差值曲线越趋于平滑,这样就越能阻止负载均衡操作(差分算法....)。
4).自下而上的遍历方式
Linux在基于调度域进行负载均衡的时候采用的是自下而上的遍历方式,这样就优先在对cache影响最小的cpu之间进行负载均衡,同时这种均衡操作会增加本cpu的负载,反过来在比较高的调度域级别上有力的阻止了对cache影响很大的cpu之间的负载均衡。 我们知道,调度域是从对cache影响最小的最底层向高层构建的。
5).结论
随着cpu级别的提高,由于负载均衡对cache利用率的影响逐渐增大,“阻力”也应该逐渐加大,因此负载均衡对应调度域使用的delta也应该增加。 算法的根本要点是什么呢?画幅图就一目了然了,delta越大,负载值受历史值的影响越大,因此按照公式所示,只有持续单调递增 的cpu负载,在源cpu选择时才会被选中,偶然一次的高负载并不足以引起其上的进程迁移至别处,相应的,只有负载持续单调递减 ,才会引起其它cpu上的进程迁移至此,这正体现了负载以一个时间段而不是一个时间点为统计周期! 而级别越高的cpu间的进程迁移,需要的“阻力”越大,因此就越受历史值的影响,因为只要历史中有一次负载很小,就会很明显的反应在当前,同样的道理,历史中有一次的负载很大,也很容易反映在当前;反之,所需“阻力”越小,就越容易受当前负载值的影响,极端的情况下,超线程的不同逻辑cpu之间的负载计算公式中delta为1,因此它们的负载计算结果完全就是该cpu的当前负载!结论有三:
5.1).通过“负载均衡过程中对cpu总负载的计算公式”平滑了单独cpu的负载曲线,使之不受突变的影响,平滑程度根据delta微调
5.2).通过“削掉波峰/波谷”平滑了源cpu和目的cpu负载曲线在负载均衡这个时间点的差值,尽可能阻止进程迁移,阻止程度根据delta微调
5.3).执行负载均衡的过程中,一轮负载均衡在每一层的效果需要随着级别的升高而降低,这通过自下而上的遍历方式来完成
6).引申
total_load的计算公式实际上使用了一个数列,该数列是一个“等比数列+微扰数列”的和数列, 等比的比值的分母决定着数列的平滑程度,而微扰数列则是cpu的当前真实负载,它根据delta的取值不同对整个cpu的负载影响不同,为了连续化数列,我们设这两个数列为函数f(x)和g(x),证明如下:
6.1).算法改进
不能从delta中得到随着d的增加,阻碍负载均衡的力度将加大这个事实虽然在技术上通过自下而上的遍历方式解决了,然而这使得算法依赖了一个操作方式,这在数学却不是很完美, 因此可以改进,引入一个参数k来微调g(x) ,而不是依赖d来微调,如果配置k和d相等,那么新算法将回退到老算法:有了新的负载计算公式,我们可以控制一个变量k,然后得知,随着d的增加,负载均衡实际发生的可能性将降低。
五.Linux负载均衡的类型以及时机
1.周期性忙负载均衡:在时钟中断中针对当前cpu调用,负载计算时更多受到历史值的影响;
2.周期性空闲负载均衡:当前cpu上没有进程可运行时调用,适当减少历史值的影响,和忙负载均衡的周期相差一个busy_factor因子(该因子可配置)。
3.唤醒进程负载均衡:Linux内核倾向于本地唤醒进程,也就是说将进程唤醒在本cpu上。在网络应用中,这显得尤为重要,众所周知,网卡中断某一个cpu,该cpu处理软中断,软中断处理协议栈,在cpu的处理过程中网络数据相应进入cache,此时唤醒用户态进程继续处理应用数据,如果是本地唤醒的话,应用程序可以有效利用cpu中已经被内核载入的cache。
4.进程新创建的时候会进行负载均衡,因此多了一个进程可能会引起负载失衡。
5.进程调用exec的时候会进行负载均衡,和4一样,这两种负载均衡都是“自负载”均衡,也就是要为自己选择一个cpu来运行
6.当前cpu马上进入idle的时候,会进行负载均衡
7.push平衡,这是一种将本地进程“推”给其他cpu的负载均衡方式
第二部分:Linux负载均衡的实现(2.6.18内核)
一.数据结构
1.sched_group结构
viewplain
struct sched_group {
struct sched_group *next; //下一个group指针
cpumask_t cpumask; //该group包含的cpu掩码
unsigned long cpu_power;
};
2.sched_domain结构
viewplain
struct sched_domain {
/* These fields must be setup */
struct sched_domain *parent; /* top domain must be null terminated */
struct sched_group *groups; /* the balancing groups of the domain */
cpumask_t span; /* span of all CPUs in this domain */
unsigned long min_interval; /* Minimum balance interval ms */
unsigned long max_interval; /* Maximum balance interval ms */
unsigned int busy_factor; /* less balancing by factor if busy */
unsigned int imbalance_pct; //判断该调度域是否已经均衡的一个基准值。
unsigned long long cache_hot_time; /* Task considered cache hot (ns) */
unsigned int cache_nice_tries; /* Leave cache hot tasks for # tries */
unsigned int per_cpu_gain; /* CPU % gained by adding domain cpus */
unsigned int busy_idx; //忙均衡的cpu_load索引,详见第一部分的“负载均衡算法分析”
unsigned int idle_idx; //空闲均衡的cpu_load索引
unsigned int newidle_idx; //马上就要进入idle的cpu为了尽量不进入idle而进行负载均衡时的cpu_load索引
unsigned int wake_idx; //唤醒进程时将进程拉至本cpu的作用力,也是一个cpu_load索引,该索引也即本地唤醒力,对于支持多队列的网卡有很大的性能增强作用。
unsigned int forkexec_idx;
int flags; /* See SD_* */
/* Runtime fields. */
unsigned long last_balance; /* init to jiffies. units in jiffies */
unsigned int balance_interval; /* initialise to 1. units in ms. */
unsigned int nr_balance_failed; /* initialise to 0 */
...
};
二.代码
1.初始化
1.1.build_sched_domains函数
对于每一个最低级别的cpu(比如超线程cpu)依次执行:view
plain
//初始化物理处理器调度域
p = sd;
sd = &per_cpu(phys_domains, i);
group = cpu_to_phys_group(i);
*sd = SD_CPU_INIT; //宏定义浅拷贝,每一个最低层次的cpu都有一个per cpu项,就是sched_domain,属于同一个sched_domain的各个cpu共享该结构体中的指针数据。
sd->span = nodemask;
sd->parent = p;
sd->groups = &sched_group_phys[group];
//初始化物理处理器的处理器核调度域
p = sd;
sd = &per_cpu(core_domains, i);
group = cpu_to_core_group(i);
*sd = SD_MC_INIT; //宏定义浅拷贝
sd->span = cpu_coregroup_map(i);
cpus_and(sd->span, sd->span, *cpu_map);
sd->parent = p;
sd->groups = &sched_group_core[group];
//初始化SMT逻辑处理器调度域
p = sd;
sd = &per_cpu(cpu_domains, i);
group = cpu_to_cpu_group(i);
*sd = SD_SIBLING_INIT; //宏定义浅拷贝
sd->span = cpu_sibling_map[i];
cpus_and(sd->span, sd->span, *cpu_map);
sd->parent = p;
sd->groups = &sched_group_cpus[group];
其中三个函数返回了cpu在对应级别的编号,用于初始化调度组:
1.1.1.返回物理cpu的cpu号:
viewplain
static int cpu_to_phys_group(int cpu)
{//cpu核组的第一个cpu的cpu号
cpumask_t mask = cpu_coregroup_map(cpu);
return first_cpu(mask);
}
1.1.2.返回cpu核的cpu号:
viewplain
static int cpu_to_core_group(int cpu)
{//逻辑cpu组的第一个cpu的cpu号
return first_cpu(cpu_sibling_map[cpu]);
}
1.1.3.返回逻辑cpu的cpu号:
viewplain
static int cpu_to_cpu_group(int cpu)
{//直接返回cpu,这是最底层次的
return cpu;
}
初始化了每一个逻辑cpu的调度域之后,依次初始化每一个调度域的各个调度组
view
plain
for_each_cpu_mask(i, *cpu_map) {
cpumask_t this_sibling_map = cpu_sibling_map[i];
cpus_and(this_sibling_map, this_sibling_map, *cpu_map);
if (i != first_cpu(this_sibling_map)) //仅以共享cpu核或者共享物理cpu的第一个逻辑cpu开始创建该调度域中所有的调度组
continue;
init_sched_build_groups(sched_group_cpus, this_sibling_map, &cpu_to_cpu_group);
}
for_each_cpu_mask(i, *cpu_map) {
cpumask_t this_core_map = cpu_coregroup_map(i);
cpus_and(this_core_map, this_core_map, *cpu_map);
if (i != first_cpu(this_core_map)) //仅以共享物理cpu的第一个cpu核开始创建该调度域中所有的调度组
continue;
init_sched_build_groups(sched_group_core, this_core_map, &cpu_to_core_group);
}
for (i = 0; i < MAX_NUMNODES; i++) {
cpumask_t nodemask = node_to_cpumask(i);
cpus_and(nodemask, nodemask, *cpu_map);
if (cpus_empty(nodemask)) //以一个NUMA节点的所有物理cpu为mask创建该调度域中所有的调度组
continue;
init_sched_build_groups(sched_group_phys, nodemask, &cpu_to_phys_group);
}
1.2.init_sched_build_groups函数
该函数初始化了同一调度域中的所有的调度组,逻辑很简单:view
plain
static void init_sched_build_groups(struct sched_group groups[], cpumask_t span,
int (*group_fn)(int cpu)) //该回调函数就是1.1.1/1.1.2/1.1.3所示的函数
{
struct sched_group *first = NULL, *last = NULL;
cpumask_t covered = CPU_MASK_NONE;
int i;
for_each_cpu_mask(i, span) { //外层循环,创建每一个调度组
int group = group_fn(i);
struct sched_group *sg = &groups[group];
int j;
if (cpu_isset(i, covered))
continue;
sg->cpumask = CPU_MASK_NONE;
sg->cpu_power = 0;
for_each_cpu_mask(j, span) { //内层循环,为每一个调度组添加所有的成员
if (group_fn(j) != group)
continue;
cpu_set(j, covered);
cpu_set(j, sg->cpumask);
}
if (!first)
first = sg;
if (last)
last->next = sg;
last = sg;
}
last->next = first;
}
2.负载均衡运行
2.1.rebalance_tick函数
每次时钟中断时,要判断是否要做负载均衡操作了,具体来讲实现两个逻辑:
2.1.1.更新cpu_load,也就是实现了计算总负载的公式
viewplain
for (i = 0, scale = 1; i < 3; i++, scale <<= 1) {//在高一些的内核版本中,不再仅设置3个cpu_load值,而是CPU_LOAD_IDX_MAX(#define CPU_LOAD_IDX_MAX 5)个,这样,囊括的策略就更多了。
unsigned long old_load, new_load;
old_load = this_rq->cpu_load[i];
new_load = this_load;
this_rq->cpu_load[i] = (old_load*(scale-1) + new_load) / scale;
}
可见,Linux将3个负载值保存成了数组,随着索引的增加,历史值影响逐渐加大,具体祥见第一部分的分析
2.1.2.从下往上依次判断是否进行负载均衡
viewplain
j = cpu_offset(this_cpu); //不同的cpu对应的j是不同的,j的值实际就是jiffies+cpu*HZ/NR_CPUS
for_each_domain(this_cpu, sd) {
if (!(sd->flags & SD_LOAD_BALANCE))
continue;
interval = sd->balance_interval;
if (idle != SCHED_IDLE)
interval *= sd->busy_factor;
if (j - sd->last_balance >= interval) { //用到了j,可见不同的cpu不会同时对该cpu进行负载均衡
if (load_balance(this_cpu, this_rq, sd, idle)) {
idle = NOT_IDLE; //返回非0,说明成功迁移了进程到本cpu,更新idle
}
sd->last_balance += interval;
}
}
j的设置是巧妙的,由于每次时钟中断都会导致jiffies递增,因此当某个时刻j-sd->last_balance正好等于interval的时候,比该cpu的cpu号大的cpu的结果将是j-sd->last_balance<interval,由此多个cpu同时操作同一个cpu的几率将减少(有效避免了该cpu将别的cpu上的进程拉了过来,然而别的cpu在调用同一函数的时候又将进程拉了回去这种互相扯皮的事情),鉴于随机数的产生会有很大的开销,因此采用了jiffies+cpu*HZ/NR_CPUS这种算法来混乱化执行的时间。 然而,由于对于每一个cpu,balance_interval参数是可以配置的,因此配置不同的balance_interval参数可能会抵消掉这种混乱化操作的结果。
2.2.load_balance函数
该函数比较复杂,它在同一个调度域的各个调度组之间进行负载均衡,总的来讲分为三块
2.2.1.找出最busy的组
2.2.2.在最busy的组中找出最busy的cpu
2.2.3.迁移最busy的cpu上的进程到本cpu,并返回实际迁移的进程的数目
2.3.find_busiest_group函数
该函数实现很复杂,然而逻辑很简单,基本策略祥见第一部分的“负载均衡算法分析”。对于代码,实际上就是一个两层的循环加上数据的更新 :view
plain
do { //外层循环,遍历该调度域的每一个调度组
...
local_group = cpu_isset(this_cpu, group->cpumask);
...
for_each_cpu_mask(i, group->cpumask) { //内存循环,遍历同一调度组的所有cpu,并累加这些cpu的负载
struct rq *rq = cpu_rq(i);
if (*sd_idle && !idle_cpu(i))
*sd_idle = 0;
if (local_group) //我们自己的组,削掉波谷,因为我们尽力在避免迁移进程
load = target_load(i, load_idx);
else //不是我们自己的组,削掉波峰,因为我们尽力避免迁移进程
load = source_load(i, load_idx);
avg_load += load;
sum_nr_running += rq->nr_running;
sum_weighted_load += rq->raw_weighted_load;
}
if (local_group) {
...
} else if (avg_load > max_load &&
...
busiest = group; //在同一层次(即同一调度域),永远不会将自己的组作为最busy的组。在一层是一个组,在其下层可能就是一个组,而调度域的遍历方向是自下而上的,因此这个算法的要点则是认为自己附近的cpu已经均衡过了。一般的第n层的所有的group在第n+1层会恰好组成同一group。
...
}
...
group = group->next;
} while (group != sd->groups);
其中source_load取了cpu_load[delta]和nowa_load的最小值,削掉了波峰,而target_load则相反,削掉了波谷
view
plain
static inline unsigned long source_load(int cpu, int type)
{
struct rq *rq = cpu_rq(cpu);
return min(rq->cpu_load[type-1], rq->raw_weighted_load);
}
static inline unsigned long target_load(int cpu, int type)
{
struct rq *rq = cpu_rq(cpu);
return max(rq->cpu_load[type-1], rq->raw_weighted_load);
}
可以看到,基于调度域的负载均衡是从下往上进行的,这样做的好处在于,每次优先从最底层级别附近pull进程过来,这样对cache的影响最小,比如两个逻辑cpu之间迁移进程对cache的影响就会小到可以忽略。随着调度域的级别的增加以及pull过来的进程增加,本cpu的负载会增加,一般而言,到达物理cpu级别这个调度域,本cpu已经就已经很忙了,因此也就很难再进行负载均衡了,实际上这也是一种阻碍进程迁移的方式。
2.4.find_busiest_queue函数
在最busy的组中寻找最busy的cpu,很简单,就是一次冒泡算法。
2.5.move_tasks函数
迁移进程
2.6.can_migrate_task函数
内核代码中的注释解决本函数:We do not migrate tasks that are:
1) running (obviously), or
2) cannot be migrated to this CPU due to cpus_allowed, or
3) are cache-hot on their current CPU.
Aggressive migration if:
1) task is cache cold, or
2) too many balance attempts have failed.
需要注意的是,cache的热度是通过进程离开运行态到现在的时间差来决定的,而这个差的阀值到底是多少,则由调度域的一个cache_hot_time字段决定。
2.7.migration_thread内核线程
本文不谈这种push模式的进程迁移,同时也不深究所谓的主动均衡和被动均衡,这些在理解了核心算法后都会很简单的。故此处略过
第三部分:负载均衡的配置
一.概述
值得注意的是,Linux所实现的调度域和调度组仅仅描述了一个cpu的静态拓扑和一组默认的配置, 这组默认的配置生成的原则就是在第一部分中描述的各种情况的基础上在负载均衡和cache利用率之间产生最小的对抗 ,Linux并没有将这些配置定死,实际上Linux的负载均衡策略是可以动态配置的。由于负载均衡实现的时候,对调度域数据结构对象使用了浅拷贝 ,因此对于每一个最小级别的cpu,都有自己的可配置参数,而对于所有属于同一调度域的所有cpu而言,它们有拥有共享的调度组,这些共享的信息在调度域数据结构中用指针实现,因此对于调度域参数而言,每个cpu是可以单独配置的。每个cpu都可配置使得可以根据底层级别cpu上的负载情况(负载只能在最底层级别的cpu上)进行灵活的参数配置,还可以完美支持虚拟化和组调度。
二.配置方法
目录/proc/sys/kernel/sched_domain 下有所有的最底层级别的cpu目录,比如你的机器上有4个物理cpu,每个物理cpu有2个核心,每个核心都开启了超线程,则总共的cpu数量是4*2*2=16,因此root@ZY:/proc/sys/kernel/sched_domain# ls
cpu0 cpu1 cpu2 cpu3 cpu4 cpu5 cpu6 cpu7 ...cpu15
root@ZY:/proc/sys/kernel/sched_domain# cd cpu0/
root@ZY:/proc/sys/kernel/sched_domain/cpu0# ls
domain0 domain1 domain2
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain0/name
SIBLING
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain1/name
MC
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain2/name
CPU
root@ZY:/proc/sys/kernel/sched_domain/cpu0# ls domain0/ #以下这些参数都是可配置的,使用sysctl即可,含义见sched_domain结构体
busy_factor cache_nice_tries forkexec_idx imbalance_pct min_interval newidle_idx
busy_idx flags idle_idx max_interval name wake_idx
三.配置实例
列举一个性能调优的实例,当我们手工绑定了进程在各自cpu上运行,并且手工平衡了各个cpu的负载,每一个cpu都有特定的任务,比如cpu0处理网络中断和软中断,cpu1处理磁盘IO,cpu2运行web服务,...(暂不考虑dca等对cache的影响),那么也就不希望内核再做负载均衡了,因此需要针对每一个cpu的调度域进行配置,使之不再进行或者“很不频繁”进行负载均衡操作:root@ZY:/proc/sys/kernel/sched_domain# echo 100000000000 > cpu0/domain1/min_interval
root@ZY:/proc/sys/kernel/sched_domain# echo 100000000000 > cpu0/domain2/min_interval
...//针对cpuX依照上述执行,另外还要设置max_interval,要大于100000000000 。对于domain0,由于它是SMT级别的,因此负载均衡并不会破坏cache,因此不设置。
...//其实还有很多的参数可以设置,比如flags,imbalance_pct,busy_factor等。
注解: 由于fork和exec的行为是不同的,fork后的新进程还是要访问老进程的数据(写时复制),而exec则彻底告别老进程(虽然还可能会访问同样载入老进程的共享库),因此调度域的flags中的SD_BALANCE_FORK和SD_BALANCE_EXEC最好应该区别开来,我们可以通过在SMT或者MC调度域中设置SD_BALANCE_FORK而SMP中不设置SD_BALANCE_FORK来优化fork后的进程的写时复制,至于SD_BALANCE_EXEC则全部支持,不过这样设置的前提是你对你的应用进程的脾气很了解,如果exec后的进程和之前的进程共享大量的在之前之后都大量被读写的共享库的话,说实话SD_BALANCE_EXEC标志也最好不要设置在SMP调度域中。
第四部分:又一个内核hack
完全可以使用sysctl配置系统的debug级别或者重新编译内核增加更多的打印信息,然而编写modules导出自己需要的信息一直都是最好的方式,因为它只输出你需要的信息,而内核的debug信息虽然很详细,但是你可能还真的需要花一番功夫才能明白其所以然。以下是一个内核模块的代码,它揪出了两个cpu的调度域和调度组信息,然后打印出来,这种编写模块的好处在于,你可以做且仅做你需要的,且一切按照你自己的风格来!
view
plain
static struct rq *(*task_rq)(struct task_struct *p, unsigned long *flags);
struct task_struct *(*gettask)(struct pid *pid, enum pid_type type);
struct pid *(*getpid)(pid_t nr);
int __init domain_init(void){
int cpu = 0, i = 0;
struct sched_domain *sd;
task_rq=0xffffffff8103fbc4; //task_rq_lock的地址
getpid = 0xffffffff810626aa; //find_get_pid的地址
gettask = 0xffffffff81062473;//get_pid_task的地址
struct task_struct *t1 = (*gettask)((*getpid)(3), PIDTYPE_PID); //进程3绑在cpu0上
struct task_struct *t2 = (*gettask)((*getpid)(6), PIDTYPE_PID); //进程6绑在cpu1上
unsigned long fl = 0;
struct rq* r = (*task_rq)(t1, &fl); //得到运行队列,注意锁住了运行队列r
spin_unlock_irqrestore(&r->lock, fl);//解锁,这是一定的,否则系统就不能响应了。
for (sd = r->sd; sd; sd = sd->parent) {
struct sched_group *sg, *sgg;
printk("domain address: %p /n", sd);
printk("domain name: %s /n", sd->name);
sg = sd->groups;
sgg = sg;
printk("group address:%p/n", sg);
while (sg->next != sgg) {
sg = sg->next;
printk("group address:%p/n", sg);
}
printk("next domain /n");
}
printk("NEXT CPU /n");
struct rq* r2 = (*task_rq)(t2, &fl);
spin_unlock_irqrestore(&r2->lock, fl);
for (sd = r2->sd; sd; sd = sd->parent) {
struct sched_group *sg, *sgg;
printk("domain address: %p /n", sd);
printk("domain name: %s /n", sd->name);
sg = sd->groups;
sgg = sg;
printk("group address:%p/n", sg);
while (sg->next != sgg) {
sg = sg->next;
printk("group address:%p/n", sg);
}
printk("next domain /n");
}
return 0;
}
void __exit domain_exit(void){
}
module_init(domain_init);
module_exit(domain_exit);
对于一个单物理cpu开启超线程的系统加载上述模块,dmesg得到以下结果:
[63962.546289] domain address: ffff88000180fa20
[63962.546294] domain name: SIBLING
[63962.546297] domain busy: 3
[63962.546300] domain busy: 180fa98
[63962.546303] group address:ffff88000180fae0 #cpu0-第一个逻辑cpu的smt调度域的第一个组,包括它自身(1)
[63962.546306] group address:ffff88000184fae0 #cpu0-第一个逻辑cpu的smt调度域的第二个组,包括它兄弟(2)
[63962.546308] next domain
[63962.546311] domain address: ffff88000180fb30
[63962.546314] domain name: MC
[63962.546316] domain busy: 30
[63962.546319] domain busy: 180fba8
[63962.546321] group address:ffff88000180fbf0
[63962.546324] next domain
[63962.546326] NEXT CPU
[63962.546329] domain address: ffff88000184fa20
[63962.546332] domain name: SIBLING
[63962.546335] domain busy: 0
[63962.546337] domain busy: 184fa98
[63962.546340] group address:ffff88000184fae0 #cpu0-第一个逻辑cpu的smt调度域的第一个组,包括它自身,等于(2)
[63962.546343] group address:ffff88000180fae0 #cpu0-第一个逻辑cpu的smt调度域的第一个组,包括它兄弟,等于(1)
[63962.546345] next domain
[63962.546348] domain address: ffff88000184fb30
[63962.546351] domain name: MC
[63962.546354] domain busy: 2
[63962.546357] domain busy: 184fba8
[63962.546359] group address:ffff88000180fbf0
[63962.546362] next domain
第五部分:Linux内核《sched-domains.txt》翻译
要问关于Linux内核的那些资料最好,我觉得最好的有两个,一个是LKML(Linux kernelmaillist)还有一个就是内核文档,内核文档中的信息相当丰富,涉及了几乎所有的核心功能,因此阅读它们是有帮助的,本文的最后,我尝试将其中《sched-domains.txt》翻译一下,“[]”中的是我的一切注释,注意,以下并不是原文直译,而是意译(信,达,雅三境界中,我可能连“信”都谈不上,因此找个理由,说是意译!)。译文如下:
每一个cpu都拥有一个“base”调度域(struct sched_domain)[注:基本的调度域,也就是最底层的调度域,以下的per-cpu指的就是最底层的cpu]。这些“base”调度域可以通过cpu_sched_domain(i)和this_sched_domain()这两个宏来访问。调度域层次结构从这些“base”调度域开始[注:向上]构建,通过调度域的parent指针可以访问到其上级调度域。parent指针必须是NULL结尾的[注:最高一级别的调度域的parent指针为NULL],调度域是per-cpu的,因为这样可以在更新其字段时,锁的开销更小[注:同时每个调度域也是单独可配置的]。
每一个调度域覆盖一定数量的cpu(存储于span字段)。一个调度域的span必须是其子调度域span的超集。cpui的“base”调度域的span中起码要包含cpui。最顶层的调度域需要覆盖系统所有的cpu,虽然严格来讲这并不是必须的,会导致一些cpu上从来都没有进程运行。调度域的span的含义是“在这些cpu之间进行负载均衡”
每一个调度域必须拥有起码一个cpu调度组(struct sched_groups),这些组组织成一个环形链表,该链表从调度域的groups字段开始。同一个调度域的这些组的cpumasks的并集表示的cpu必须和该调度域的span字段表示的cpu完全相等,同时,属于同一调度域的任意两个组的cpumasks字段的交集必须是空集。一个调度域的调度组覆盖的cpu必须是该调度域所覆盖的。这些调度组的只读数据在cpu之间是共享的。
一个调度域的负载均衡操作发生在其各个调度组之间。此时,每一个调度组被当成了一个整体对待。一个调度组的负载定义为该组中所有的cpu成员的负载之和,并且只有当组与组之间的负载失衡的时候,才会在组与组之间迁移进程。
从源文件kernel/sched.c中可以看出,每一个cpu会周期性的调用rebalance_tick函数。该函数将从该cpu的“base”调度域开始检查该调度域内的进程是否到达了其负载均衡的周期,如果是,则在该调度域调用load_balance,然后在“base”调度域的parent调度域中执行上述操作,这是一个遍历的过程,遍历过程以此类推。
*** 调度域的实现[和定制] ***
“base”调度域将构成调度域层级结构的第一级。举例来讲,在SMT的情况下,“base”调度域覆盖了一个物理cpu的所有逻辑cpu,每一个逻辑cpu构成了一个调度组。SMP的情况下,物理cpu调度域作为“base”调度域的parent,它将覆盖一个NUMA节点中的所有的cpu。其每一个调度组覆盖一个物理cpu。同样的道理,在NUMA情况下,节点调度域作为物理cpu调度域的parent,它将覆盖整台机器的所有cpu,其每一个调度组覆盖一个节点的所有cpu。
实现者需要阅读include/linux/sched.h文件里面关于sched_domain结构体的字段的注释以及SD_FLAG_*和SD_*_INIT来了解更多的细节以及了解如何来调节这些参数从而影响内核负载均衡的行为。
如果你想支持SMT,必须定义CONFIG_SCHED_SMT宏,并且提供一个cpumask_t类型的数组cpu_sibling_map[NR_CPUS],元素cpu_sibling_map[i]的含义是所有和cpui属于同一个物理cpu[或者物理cpu核]的逻辑cpu的掩码,这个掩码中当然也包括cpui本身。
[针对特定的体系结构可以对Linux内核默认的调度域/调度组的默认参数以及设置进行重载,此处不再翻译]

相关文章推荐
- Linux调度域负载均衡-设计,实现和应用
- Linux+Nginx+Tomcat+Redis实现负载均衡,应用集群及session共享
- linux 双网卡绑定(bonding)实现负载均衡或故障转移
- Nginx负载均衡配置(实现多台主机应用负载均衡并且隐藏应用主机不受攻击)
- Linux LVS Keepalived实现Httpd服务器80端口的负载均衡
- linux 双网卡绑定(bonding)实现负载均衡或故障转移
- 详解之:linux下tomcat、nginx的负载均衡及memcached对session共享的实现配置详细总结
- Linux中Apache+Tomcat+JK实现负载均衡和群集的完整过程
- linux集群系列(一):LVS+Keepalived以DR模式实现负载均衡
- nginx实现http负载均衡的几种调度算法具体补充
- linux 双网卡绑定(bonding)实现负载均衡或故障转移
- linux 双网卡绑定(bonding)实现负载均衡或故障转移
- nginx实现tomcat的负载均衡及企业内部应用的代理
- 负载均衡--大型在线系统实现的关键(下篇)(服务器集群架构的设计与选择)
- 如何实现大型网站架构设计的负载均衡
- Linux中Apache+Tomcat+JK实现负载均衡和群集的完整过程(转载)
- linux 双网卡绑定(bonding)实现负载均衡或故障转移
- CCNP sla,route-map结合应用实现负载均衡和冗余
- Linux中Apache+Tomcat+JK实现负载均衡和群集的完整过程
- 读薄「Linux 内核设计与实现」(2) - 进程管理和调度