浏览器访问web资源的过程
2011-11-30 10:42
148 查看
从浏览器输入网址到结果返回的具体过程图
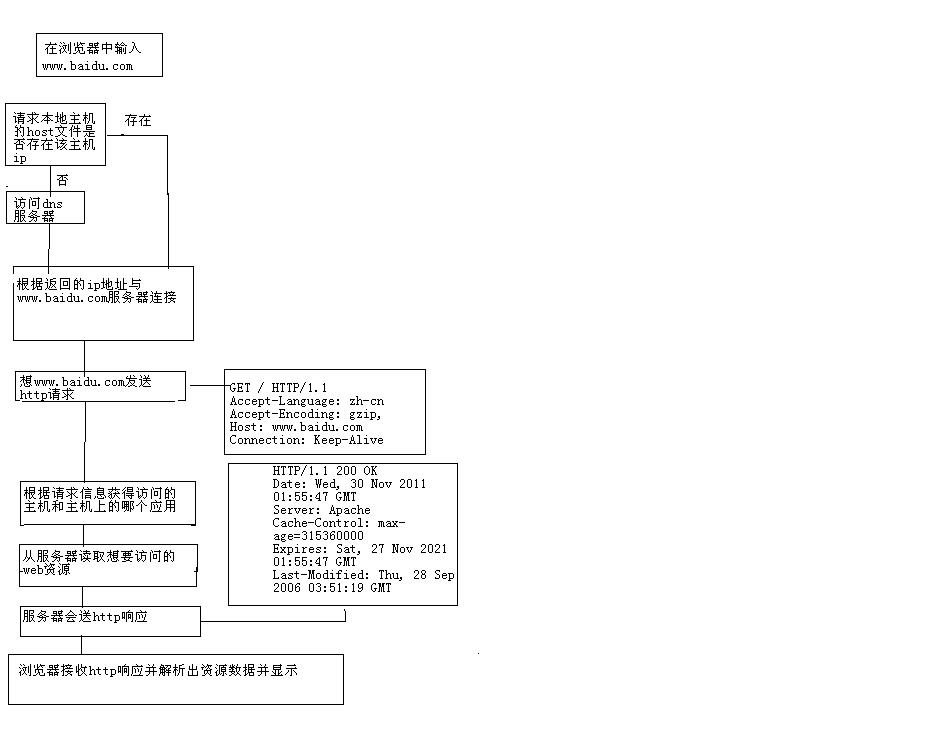
一个完整的http请求包括一个消息行,若干消息头以及实体内容吗,如下图

Get是一种请求方式,book/java.html即访问该主机下的book应用下的java.html资源,http/1.1即http协议版本为1.1
Accept指客户端可以接受的数据格式
Accept-language指客户端使用的语言,en-us,en指英语,us指美国,zh-cn中zh指汉语,cn之中国
Connection连接方式:若为close则指服务器处理完一次http请求后自动断开连接,keep_alive处理一次请求仍保持连接,不断开
Refer:服务器通过该消息头的内容判断该资源是从哪个资源来访问服务器的,主要起到防盗链作用,例如在百度新闻上有一条链接为“xx新闻”,该链接指向的网址为www.sina.com.cn/news/gov.html那么当访问该资源时,新浪服务器收到的Referer内容为new.baidu.com,此时新浪服务器即可判断该资源已被其他网站引用,如果该资源采用了防盗链功能,那么将不能直接访问到该资源而是会跳转到新浪服务器指定返回的页面。
user_agent:告诉服务器客户端的软件环境
Accept-Encoding指客户端能是别的压缩格式,为了减小网络传输量,服务器会根据客户端能够接受的压缩格式对资源压缩后返回给客户端,然后客户端自动解压。
http响应就是服务器向和客户端回送的数据,包括一个状态行,若干消息头和实体内容,如下图
200指响应状态码
200指服务器正确处理了客户端的请求
304一般指告诉客户端从缓存中读取,
常见的错误码就是404了,这中情况下指的是刻画端访问的资源不存在,403指客户端访问的资源存在但是没有足够的权限访问
500指服务器处理请求资源时发生异常。
http响应 记录了数据的大小格式,服务器等相关信息
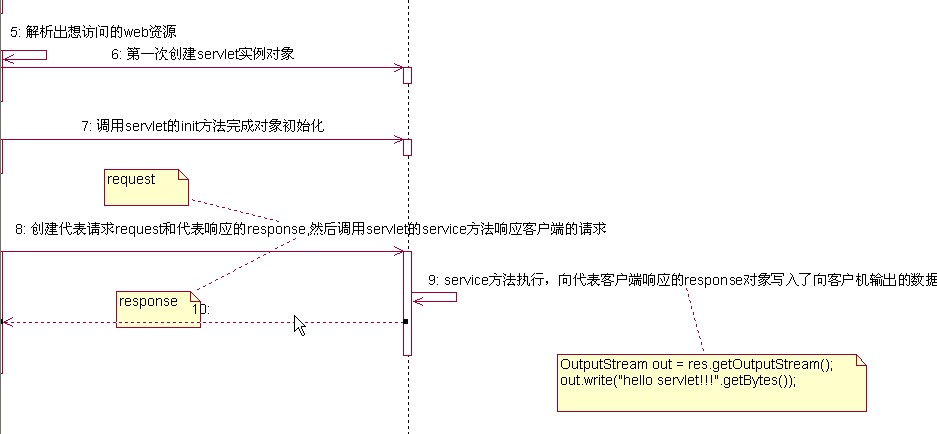
服务器读解析出需要访问的web资源到回送http响应的细节过程如下图

相关文章推荐
- 浏览器访问web资源的过程
- 浏览器访问web资源的过程
- javaweb-day04-4(javaWeb开发入门 - 画图演示:浏览器访问服务器的静态web资源的过程)
- 浏览器访问web资源的过程(telnet 服务 、 回显设置 XP WIN7)
- 浏览器访问Web资源的流程图
- java程序模拟浏览器访问Web服务器的处理过程
- Servlet3.0中WEB-INF\lib下的jar包中的资源可以直接通过浏览器访问
- web资源访问过程及http协议详解
- 浏览器访问 web服务器 的过程
- 访问web资源,浏览器报404的可能原因总结(访问的页面不存在)
- javaWeb_07-UML描述web资源访问流程
- 浏览器访问网页的详细内部过程
- 在 Action 中访问 WEB 资源(struts2获取HttpServletRequest, HttpSession, ServletContext)
- Web资源访问及HTTP协议详解
- android开发我的新浪微博客户端-OAuth认证过程中用WebView代替原来的系统自带浏览器
- 用webdriver+phantomjs实现无浏览器的自动化过程
- Web资源访问及HTTP协议详解
- 利用WebResource.axd通过一个URL来访问装配件的内置资源