LevelDB中的Skip List(跳跃表)
2011-09-13 22:07
465 查看
LevelDB中的Skip List(跳跃表)
转载:http://blog.nosqlfan.com/html/3041.html本文是关于Skip
List数据结构的,Skip List是在有序List(链表)数据结构的基础上的扩展,解决了有序链表结构查找特定值困难的问题,使用Skip List,可以使得在一个有序链表里查找特定值的时间复杂度为O(logn),在本文中我们看到,Skip List被用在leveldb中,实际上它还被使用在Redis的sorted
sets数据结构中。
这段时间在关注leveldb。leveldb中有一个核心的数据结构skiplist,如图所示skip
list和单链表类似,只不过有些节点有前向指针以便加快遍历,有k个前向指针的节点叫做level k node。
本博客主要介绍skiplist的算法原理,包括skiplist增删改查,下一篇博客将介绍skiplist的复杂度分析。(博客内容主要是翻译Skip
Lists: A probabilistic Alternative to Balanced Trees)
Skip list(跳跃表)是一种可以代替平衡树的数据结构。Skip lists应用概率保证平衡,平衡树采用严格的旋转(比如平衡二叉树有左旋右旋)来保证平衡,因此Skip list比较容易实现,而且相比平衡树有着较高的运行效率。
从概率上保持数据结构的平衡比显示的保持数据结构平衡要简单的多。对于大多数应用,用skip list要比用树更为自然,算法也会相对简单。由于skip list比较简单,实现起来会比较容易,虽然和平衡树有着相同的时间复杂度(O(logn)),但是skip list的常数项会相对小很多。skip list在空间上也比较节省。一个节点平均只需要1.333个指针(甚至更少),并且不需要存储报纸平衡的变量。
Skip Lists
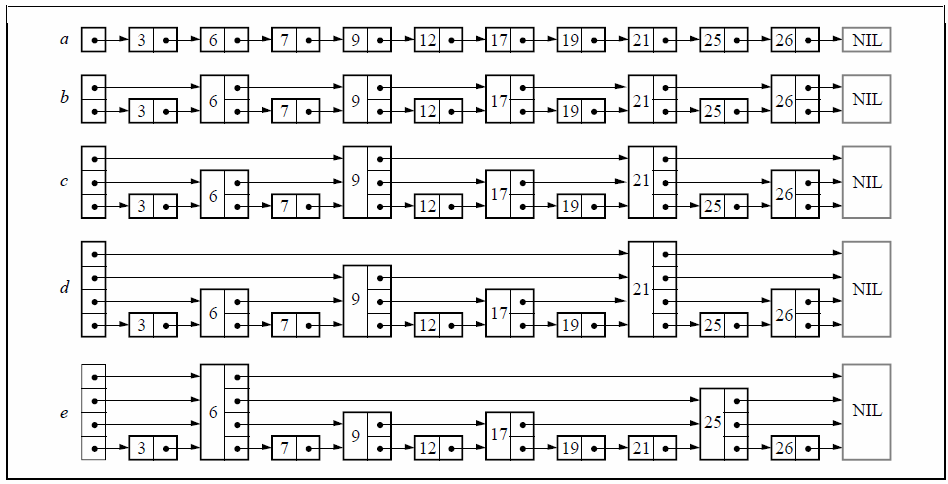
如图链表中的值,非递减顺序排列。图a:为了查找单链表中的某个值,最坏情况下需要将链表全部遍历一遍,需要遍历n个节点。
图b:每2个节点存储了它后面第2个节点,知识最多需要遍历n/2 + 1个节点。
图c:图b基础上每4个节点存储前面第4个节点内容,这时最多遍历n/4 + 2个节点。(n/4 + 4/2)
图d:如果每2^i个节点都指向前面2^i个节点,寻找一个节点的复杂度变成logn(类似于二分查找)。虽然这种结构查找很快但是插入删除却很复杂。
有着k个前向指针(farword pointers)的节点叫做level k node。如果每2^i的节点指向前面2^i个后继节点,那么节点的分布情况为:50% 在第一层,25%在第二层,12.5%在第3层。如果所有节点的层数是随机挑选的。节点第i个前向指针指向后面第2^(i-1)个节点。插入和删除只需要局部修改少数指针,节点的层数(level)在插入时随机选取,并且以后不需要修改。虽然有一些指针的排列会导致很坏的运行时间,但是这些情况很少出现。
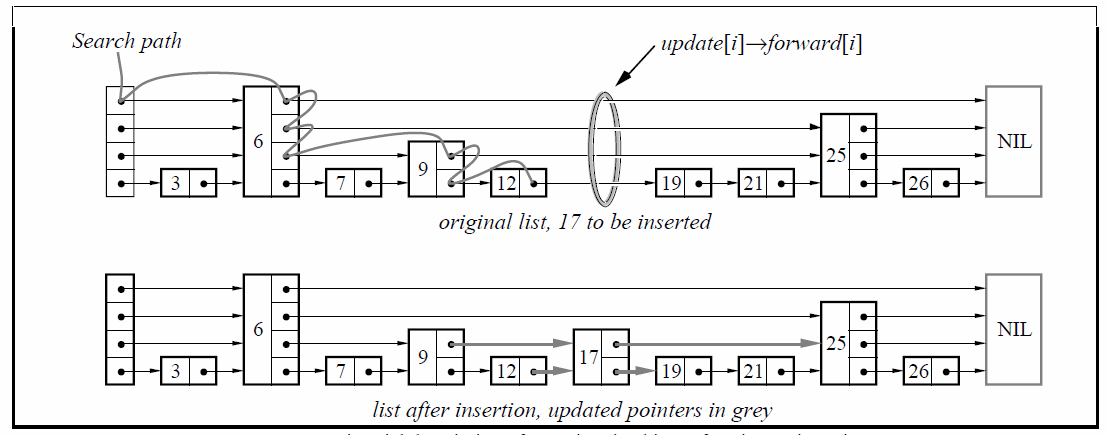
初始化
首先申请一个NIL节点,此节点的Key赋一个最大值作为哨兵节点。链表的level置为1,头结点所有的forward pointer指向NIL节点。
查找
为了找到要查找的值,我们逐次遍历forward pointer。当指针在level 1层不能继续前进时,我们肯定在需要节点的前一个节点处(如果链表中存在要查找的节点)
Search(list, searchKey) x := list->header //loop invariant: x->key < searchKey for i := list->level downto 1 do while x->forward[i]->key < searchKey do x := x->forward[i] //x->key < sarchKey <= x->forward[1]->key x := x->forward[1] if x->key = searchKey then rturn x->value else return failure
随机选择层数
之前讨论时层数的选择是按照1/2(p=1/2)的概率选择的,p可以取[0, 1)间的任意值,算法如下所示。randomLevel() |v| : =1 //random()that returns a random value in [0..1) while random() < p and |v| < MaxLevel do |v| := |v| + 1 return |v|
Insert(list, searchKey, newValue) local update[1..MaxLevel] x : =list->header for i := list->level donwto 1 do while x->forward[i]->key < searchKey do x := x->forward[i] //x->key < searchKey <= x->forward[i]->key update[i] := x x := x->forward[1] if x->key = searchKey then x->value := newValue else |v| := randomLevel() if |v| > list->level then for i := list->level + 1 to |v| do update[i] := list->header list->level := |v| x := makeNode(|v|, searchKey, value) for i := 1 to level do x->forward[i] := update[i]->forward[i] update[i]->forward[i] := x
Delete(list searchKey) local update[1..MaxLevel] x := list->header for i := list->level downto 1 do while x->forward[i]->key < searchKey do x := x->forward[i] update[i] := x x := x->forward[1] if x->key = searchKey then for i := 1 to list->level do if update[i]->forward[i] != x then break update[i]->forward[i] := x->forward[i] free(x) while list->leve > 1 and list->header->forward[list->level] = NULL do list->level := list->level - 1
结论
从理论的角度看,skiplist是完全没有必要的。Skip lists能做的事情平衡树也同样能做,并且在最坏情况下的时间复杂度比Skip lists要好。但是实现平衡树却是一项复杂的工作,除了在数据结构课程上实现平衡树外,实际应用中很少会实现它。作为一种简单的数据结构,在大多数应用中Skip lists能够代替平衡树。Skip lists算法非常容易实现、扩展和修改。Skip lists和进行过优化的平衡树有着同样高的性能,Skip lists的性能远远超过未经优化的平衡二叉树。
来源:blog.xiaoheshang.info
看到大家在微博上对Skip List讨论非常激烈,再分享一个讲Skip List的图文并茂的PPT:
skip
list
View more presentations from iammutex

相关文章推荐
- LevelDB中的Skip List(跳跃表)
- LevelDb skiplist
- 浅析SkipList跳跃表原理及代码实现
- 【从下而上学习Redis】数据结构篇(一):跳跃表(skiplist)
- Skip List(跳跃表)原理详解与实现
- 跳跃表(Skip List)的实现及测试 C++实现
- Java实现跳跃表(skiplist)的简单实例
- 数据结构与算法(c++)——跳跃表(skip list)
- 【算法导论33】跳跃表(Skip list)原理与java实现
- 跳跃表(Skip List)-实现(Java)
- c++实现跳跃表(Skip List)的方法示例
- LevelDB : Skip List
- LevelDB源码剖析之SkipList
- LevelDB源码之SkipList原理
- 跳跃表(Skip List)
- Redis Skip List(跳跃表)
- 跳跃表Skip List的原理和实现(Java)
- Skip List(跳跃表)原理详解与实现
- 【算法导论33】跳跃表(Skip list)原理与java实现
- Redis内部数据结构详解之跳跃表(skiplist)