Sphinx API类型以及SphinxSE实现原理分析
2011-09-01 13:39
447 查看
Sphinx comes with three different APIs, SphinxAPI, SphinxSE, and SphinxQL.
SphinxAPI is a native library available for Java, PHP, Python, Perl, C, and other languages.
SphinxSE, a pluggable storage engine for MySQL, enables huge result sets to be shipped directly to MySQL server for post-processing.
SphinxQL lets the application query Sphinx using standard MySQL client libary and query syntax.
它在系统中的角色是作为一种查询接口,可以当作是一种api。下图描述了sphinxSE在整个查询系统中的位置。
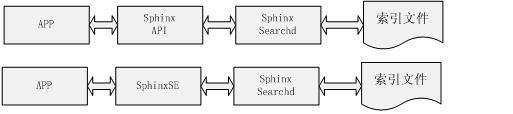
Sphinx的工作过程从下图中加于说明。
1. 应用程序发起查询请求,这个查询请求是查询mysql数据库中sphinxSE引擎的schema;
2. Mysql接收到请求以后,经过sql分析优化等,会提交到sphinxSE引擎代码进行处理;
3. sphinxSE引擎在进行索引查询的时候,会将查询截取出来,转化成sphinx的查询命令;
4. sphinxSE将查询命令发送到sphinx查询服务器进行查询;
5. Sphinx查询服务器查询索引文件,得到结果
6. 将查询结果返回。

具体安装方法可以参考手册http://www.coreseek.cn/docs/coreseek_3.2-sphinx_0.9.9.html,这里就不再重复。
以店铺内商品搜索为例,我们来建立一个搜索表。假设我们只需要查询商品的添加时间,其他的商品属性我们暂不关心。
CREATE TABLE sphinxSE_0709
(
id bigint(20) UNSIGNED NOT NULL,
weight INTEGER default 1,
query VARCHAR(3072) NOT NULL,
Fadd_time timestamp NOT NULL DEFAULT ‘0000-00-00 00:00:00′,
INDEX(query)
) ENGINE=SPHINX CONNECTION=”sphinx://localhost:9312″;
搜索表前三列(字段)的类型必须是INTEGER UNSINGED(或者 BIGINT),INTEGER(或者 BIGINT)和VARCHAR(或者 TEXT),这三列分别对应文档ID,匹配权值和搜索查询。这前三个列的映射关系是固定的,你不能忽略这三列中的任何一个,或者移动其位置,或者改变其类型。搜索查询列必须被索引,其他列必须无索引。列的名字会被忽略,所以可以任意命名。
除此之外,其他列(字段)的类型必须是INTEGER、TIMESTAMP、BIGINT、VARCHAR或者FLOAT之一。它们必须与Sphinx结果集中提供的属性按名称绑定,即它们的名字必须与sphinx.conf中指定的属性名一一对应。如果Sphinx搜索结果中没有某个属性名,该列的值就为NULL.
可以使用字符串参数CONNECTION来指定用这个表搜索时的默认搜索主机、端口号和索引。如果CREATE TABLE中没有使用连接(connection)串,那么默认使用索引名“*”(搜索所有索引)和localhost:9312。连接串的语法如下:
CONNECTION=”sphinx://HOST:PORT/INDEXNAME”
默认的连接串也可以日后用alter命令改变。
select * from sphinxSE_0709 where query=’space;mode=any; sort=extended: Fadd_time desc’;
如例子所示,查询文本和搜索选项都应放在WHERE子句中对query列的限制中(即第三列),选项之间用分号分隔,选项名与选项值用等号隔开。可以指定任意数目的选项。sphinxSE的引擎获取这些信息以后,会生成查询命令,发送到sphinx查询服务器进行查询。收到返回的结果以后,再返回给用户。
可以对SphinxSE搜索表和其他引擎的表之间使用JOIN操作,对多个表的数据进行联合。如果sphinx查询返回的数据根据查询过滤条件过滤以后,得到的数据量不大,那么这种联合的效率是非常高,花费时间基本可以忽略。下面是我想根据查询结果,查询商品的名称和店铺名称的语句。
select ftitle , fqqnick from t_commodity_0709 join sphinxSE_0709 on (t_commodity_0709.Fcommodity_id = sphinxSE_0709.id) where query=’space;mode=any’;
将原来的三列系统行(搜索表中的前三列)扩展为六列系统行,增加了查询总匹配数,本次查询返回的匹配数和查询耗时时间三个性能指标。
因此,在创建sphinxSE的搜索表格的时候,需要稍作修改,增加三个系统列。示例如下。
CREATE TABLE sphinxSE_0709
(
id bigint(20) UNSIGNED NOT NULL,
weight INTEGER default 1,
query VARCHAR(3072) NOT NULL,
Matchestotal INTEGER default 0,
Matchesfound INTEGER default 0,
Querymsec INTEGER default 0,
Fadd_time timestamp NOT NULL DEFAULT ‘0000-00-00 00:00:00′,
INDEX(query)
) ENGINE=SPHINX CONNECTION=”sphinx://localhost:9312″;
结论:SphinxSE会慢一点,但没有明显区别。主要损耗在mysql内部引擎处理会耗费几个毫秒的时间
,这点时间可以忽略不计。如果业务在查询的时候使用join操作,那么在join操作可以省略在应用程序上产生的二次聚合,那么整体上的速度会更快。但使用join操作的时候注意,如果原来系统使用了诸如mem cache等外部缓存, 数据库的join操作会不使用外部cache,那么会不会对mysql数据库的io操作造成压力,需要各个业务自己做评估。
特点:
SphinxSE可以跟数据源db和sphinx分开部署
方便切换sphinx服务器(一条sql命令即可切换)
原理上,所有通过api的查询,都可以通过sphinxSE实现
u sphinxSE和sphinx查询服务器的短连接,稳定性需要经过考验。同时为了避免每次连接都fork出一个进程来处理,最好采用版本比较新的sphinx,因为可以采用进程池来解决这个问题。
SphinxAPI is a native library available for Java, PHP, Python, Perl, C, and other languages.
SphinxSE, a pluggable storage engine for MySQL, enables huge result sets to be shipped directly to MySQL server for post-processing.
SphinxQL lets the application query Sphinx using standard MySQL client libary and query syntax.
一. sphinxSE工作原理
sphinxSE是一个mysql的扩展数据库引擎,通过sphinxSE可以使用类似sql的语法,通过mysql对sphinx进行数据查询。它在系统中的角色是作为一种查询接口,可以当作是一种api。下图描述了sphinxSE在整个查询系统中的位置。
Sphinx的工作过程从下图中加于说明。
1. 应用程序发起查询请求,这个查询请求是查询mysql数据库中sphinxSE引擎的schema;
2. Mysql接收到请求以后,经过sql分析优化等,会提交到sphinxSE引擎代码进行处理;
3. sphinxSE引擎在进行索引查询的时候,会将查询截取出来,转化成sphinx的查询命令;
4. sphinxSE将查询命令发送到sphinx查询服务器进行查询;
5. Sphinx查询服务器查询索引文件,得到结果
6. 将查询结果返回。
二. sphinxSE的应用
为一个sphinx应用建立sphinxSE的查询接口,需要以下一些步骤。1. 安装sphinxSE
需要选择一个mysql数据库,安装sphinxSE引擎。这个mysql数据库,可以跟数据源不是同一台机器,也可以是同一台机器。但要注意,如果在查询的时候想使用join操作,那么安装sphinxSE的mysql就需要跟数据源的mysql相同。具体安装方法可以参考手册http://www.coreseek.cn/docs/coreseek_3.2-sphinx_0.9.9.html,这里就不再重复。
2. 建立引擎类型为sphinx的搜索表
要通过SphinxSE搜索,您需要建立特殊的ENGINE=SPHINX的“搜索表”。这个表格是一个空表,你不能通过insert命令往里面插数据。对应每一个searchd进程,应该建立一个这样的表格。以店铺内商品搜索为例,我们来建立一个搜索表。假设我们只需要查询商品的添加时间,其他的商品属性我们暂不关心。
CREATE TABLE sphinxSE_0709
(
id bigint(20) UNSIGNED NOT NULL,
weight INTEGER default 1,
query VARCHAR(3072) NOT NULL,
Fadd_time timestamp NOT NULL DEFAULT ‘0000-00-00 00:00:00′,
INDEX(query)
) ENGINE=SPHINX CONNECTION=”sphinx://localhost:9312″;
搜索表前三列(字段)的类型必须是INTEGER UNSINGED(或者 BIGINT),INTEGER(或者 BIGINT)和VARCHAR(或者 TEXT),这三列分别对应文档ID,匹配权值和搜索查询。这前三个列的映射关系是固定的,你不能忽略这三列中的任何一个,或者移动其位置,或者改变其类型。搜索查询列必须被索引,其他列必须无索引。列的名字会被忽略,所以可以任意命名。
除此之外,其他列(字段)的类型必须是INTEGER、TIMESTAMP、BIGINT、VARCHAR或者FLOAT之一。它们必须与Sphinx结果集中提供的属性按名称绑定,即它们的名字必须与sphinx.conf中指定的属性名一一对应。如果Sphinx搜索结果中没有某个属性名,该列的值就为NULL.
可以使用字符串参数CONNECTION来指定用这个表搜索时的默认搜索主机、端口号和索引。如果CREATE TABLE中没有使用连接(connection)串,那么默认使用索引名“*”(搜索所有索引)和localhost:9312。连接串的语法如下:
CONNECTION=”sphinx://HOST:PORT/INDEXNAME”
默认的连接串也可以日后用alter命令改变。
3. 通过sphinxSE进行查询
查询的语句跟普通的sql语句类似。根据一个例子来说明吧。select * from sphinxSE_0709 where query=’space;mode=any; sort=extended: Fadd_time desc’;
如例子所示,查询文本和搜索选项都应放在WHERE子句中对query列的限制中(即第三列),选项之间用分号分隔,选项名与选项值用等号隔开。可以指定任意数目的选项。sphinxSE的引擎获取这些信息以后,会生成查询命令,发送到sphinx查询服务器进行查询。收到返回的结果以后,再返回给用户。
可以对SphinxSE搜索表和其他引擎的表之间使用JOIN操作,对多个表的数据进行联合。如果sphinx查询返回的数据根据查询过滤条件过滤以后,得到的数据量不大,那么这种联合的效率是非常高,花费时间基本可以忽略。下面是我想根据查询结果,查询商品的名称和店铺名称的语句。
select ftitle , fqqnick from t_commodity_0709 join sphinxSE_0709 on (t_commodity_0709.Fcommodity_id = sphinxSE_0709.id) where query=’space;mode=any’;
三. 对sphinxSE的扩展
原来缺省的sphinxSE的搜索表,只返回了搜索的结果,但没有对本次搜索的统计和性能进行返回,需要通过其他方式获取。这种两次获取的方式,可能导致获取的统计信息不是本次查询的信息。而在我们的应用中,都需要这些统计信息,因此我们对sphinxSE引擎进行了扩充,将原来的三列系统行(搜索表中的前三列)扩展为六列系统行,增加了查询总匹配数,本次查询返回的匹配数和查询耗时时间三个性能指标。
因此,在创建sphinxSE的搜索表格的时候,需要稍作修改,增加三个系统列。示例如下。
CREATE TABLE sphinxSE_0709
(
id bigint(20) UNSIGNED NOT NULL,
weight INTEGER default 1,
query VARCHAR(3072) NOT NULL,
Matchestotal INTEGER default 0,
Matchesfound INTEGER default 0,
Querymsec INTEGER default 0,
Fadd_time timestamp NOT NULL DEFAULT ‘0000-00-00 00:00:00′,
INDEX(query)
) ENGINE=SPHINX CONNECTION=”sphinx://localhost:9312″;
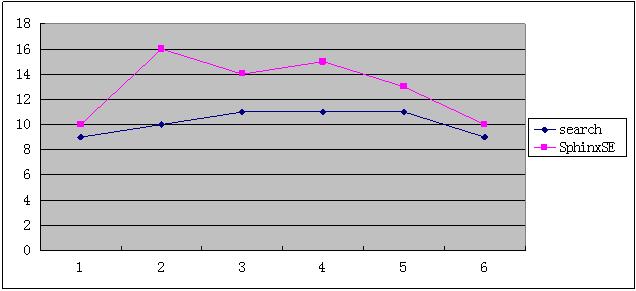
四. sphinxSE接口的性能
测试环境:表大小265746条记录,64位机器, 查询中英文都有,每次测试的查询词语都不一样,查询时间单位ms结论:SphinxSE会慢一点,但没有明显区别。主要损耗在mysql内部引擎处理会耗费几个毫秒的时间
,这点时间可以忽略不计。如果业务在查询的时候使用join操作,那么在join操作可以省略在应用程序上产生的二次聚合,那么整体上的速度会更快。但使用join操作的时候注意,如果原来系统使用了诸如mem cache等外部缓存, 数据库的join操作会不使用外部cache,那么会不会对mysql数据库的io操作造成压力,需要各个业务自己做评估。
特点:
SphinxSE可以跟数据源db和sphinx分开部署
方便切换sphinx服务器(一条sql命令即可切换)
原理上,所有通过api的查询,都可以通过sphinxSE实现
u sphinxSE和sphinx查询服务器的短连接,稳定性需要经过考验。同时为了避免每次连接都fork出一个进程来处理,最好采用版本比较新的sphinx,因为可以采用进程池来解决这个问题。

相关文章推荐
- Spring3.1.0实现原理分析(一).类型转换
- Java 8 动态类型语言Lambda表达式实现原理分析
- mysql数据库主从配置详解以及主从实现原理分析
- spark ml 算法原理剖析以及具体的源码实现分析
- 数据库shard中间件对比,以及sharding-jdbc 实现原理分析
- jQuery的datatable的使用例子,以及通过例子分析datatable插件的实现过程,即不但要会用,还要懂其原理
- C++ STL中顺序容器类型以及实现原理
- java过滤器原理分析以及实现,通过过滤器实现自动登陆
- 快速排序算法原理,实现,以及时间复杂度分析
- IronPython for ASP.NET 的原理分析(一):如何在 CLR 类型上实现动态性
- 浅谈实现滑动验证码,Java核心代码以及原理分析
- Spring3.1.0实现原理分析(一).类型转换
- 主成分分析(PCA)原理与故障诊断(SPE、T^2以及结合二者的综合指标)-MATLAB实现
- IronPython for ASP.NET 的原理分析(一):如何在 CLR 类型上实现动态性
- HashMap实现原理分析以及HashSet
- Java 8 动态类型语言Lambda表达式实现原理分析
- Android的延迟实现的几种解决方案以及原理分析
- Cubby的plugin的实现原理以及执行顺序分析
- CSS中垂直居中大总结以及实现原理分析
- mysql数据库主从配置详解以及主从实现原理分析