HDFS读写文件实例与解析
2011-08-29 17:49
246 查看
使用实例:
1.项目结构(引入包hadoop-0.20.2-core.jar和commons-logging.jar)

2.代码
HdfsCommon.java
4. 在终端下,使用hadoop命令行测试结果。
读文件流程:

1.client调用FileSystem.open()方法:
FileSystem通过RPC与namenode通信,namenode返回该文件的部分或全部block列表(含有block拷贝的datanode地址)。
选取距离客户端最近的datanode建立连接,读取block,返回FSDataInputStream。
2.client调用输入流的read()方法:
当读到block结尾时,FSDataInputStream关闭与当前datanode的连接,并为读取下一个block寻找最近datanode。
读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
如果block列表读完后,文件还未结束,FileSystem会继续从namenode获取下一批block列表。
这些操作对client透明,client感觉到的是连续的流。
3.关闭FSDataInputStream
写文件流程:
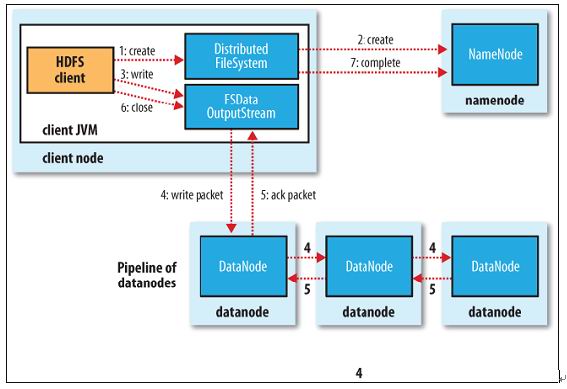
1.client调用FileSystem的create()方法:
FileSystem向namenode发出请求,在namenode的namespace里面创建一 新文件,但是并不关联任何块。
Namenode检查文件是否已存在、操作权限。如果检查通过,namenode记录新文件信息,并在某一个datanode上创建数据块。
返回FSDataOutputStream,将client引导至该数据块执行写入操作。
2.client调用输出流的write()方法:HDFS默认将每个数据块放置3份。FSDataOutputStream将数据首先写到第一节点,第一节点将数据包传送并写入第二节点,第二节点=》第三节点。
3.client调用流的close()方法:flush缓冲区的数据包,block完成复制份数后,namenode返回成功消息。
补:1.客户端可以独立于Hadoop的集群。2.hadoop的底层传输协议为RPC。3.写数据备份放置策略:如果客户端在集群上,第一份在客户端,否则随机;第二份与第一份不在同一机架;第三份与第二份在同一机架,不同节点;其余放在随机节点,但避免一个机架多份备份。
1.项目结构(引入包hadoop-0.20.2-core.jar和commons-logging.jar)
2.代码
HdfsCommon.java
public class HdfsCommon {
private Configuration conf;
private FileSystem fs;
public HdfsCommon() throws IOException{
conf=new Configuration();
fs=FileSystem.get(conf);
}
/**
* 上传文件,
* @param localFile 本地路径
* @param hdfsPath 格式为hdfs://ip:port/destination
* @throws IOException
*/
public void upFile(String localFile,String hdfsPath) throws IOException{
InputStream in=new BufferedInputStream(new FileInputStream(localFile));
OutputStream out=fs.create(new Path(hdfsPath));
IOUtils.copyBytes(in, out, conf);
}
/**
* 附加文件
* @param localFile
* @param hdfsPath
* @throws IOException
*/
public void appendFile(String localFile,String hdfsPath) throws IOException{
InputStream in=new FileInputStream(localFile);
OutputStream out=fs.append(new Path(hdfsPath));
IOUtils.copyBytes(in, out, conf);
}
/**
* 下载文件
* @param hdfsPath
* @param localPath
* @throws IOException
*/
public void downFile(String hdfsPath, String localPath) throws IOException{
InputStream in=fs.open(new Path(hdfsPath));
OutputStream out=new FileOutputStream(localPath);
IOUtils.copyBytes(in, out, conf);
}
/**
* 删除文件或目录
* @param hdfsPath
* @throws IOException
*/
public void delFile(String hdfsPath) throws IOException{
fs.delete(new Path(hdfsPath), true);
}
}core-site.xml<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- global properties --> <property> <name>hadoop.tmp.dir</name> <value>/home/whuqin/tmp</value> </property> <!-- file system properties --> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>测试代码Test.java
public class Test {
public static void main(String[] args) throws IOException {
HdfsCommon hdfs=new HdfsCommon();
// hdfs.upFile("/home/whuqin/file01", "hdfs://localhost:9000/user/whuqin/input/file01copy1");
// hdfs.downFile("hdfs://localhost:9000/user/whuqin/input/file01copy", "/home/whuqin/fileCopy");
// hdfs.appendFile("/home/whuqin/file01", "hdfs://localhost:9000/user/whuqin/input/file01copy");
hdfs.delFile("hdfs://localhost:9000/user/whuqin/input/file01copy1");
}
}3.直接点击项目,右键运行即可(在eclipse下)4. 在终端下,使用hadoop命令行测试结果。
读文件流程:
1.client调用FileSystem.open()方法:
FileSystem通过RPC与namenode通信,namenode返回该文件的部分或全部block列表(含有block拷贝的datanode地址)。
选取距离客户端最近的datanode建立连接,读取block,返回FSDataInputStream。
2.client调用输入流的read()方法:
当读到block结尾时,FSDataInputStream关闭与当前datanode的连接,并为读取下一个block寻找最近datanode。
读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
如果block列表读完后,文件还未结束,FileSystem会继续从namenode获取下一批block列表。
这些操作对client透明,client感觉到的是连续的流。
3.关闭FSDataInputStream
写文件流程:
1.client调用FileSystem的create()方法:
FileSystem向namenode发出请求,在namenode的namespace里面创建一 新文件,但是并不关联任何块。
Namenode检查文件是否已存在、操作权限。如果检查通过,namenode记录新文件信息,并在某一个datanode上创建数据块。
返回FSDataOutputStream,将client引导至该数据块执行写入操作。
2.client调用输出流的write()方法:HDFS默认将每个数据块放置3份。FSDataOutputStream将数据首先写到第一节点,第一节点将数据包传送并写入第二节点,第二节点=》第三节点。
3.client调用流的close()方法:flush缓冲区的数据包,block完成复制份数后,namenode返回成功消息。
补:1.客户端可以独立于Hadoop的集群。2.hadoop的底层传输协议为RPC。3.写数据备份放置策略:如果客户端在集群上,第一份在客户端,否则随机;第二份与第一份不在同一机架;第三份与第二份在同一机架,不同节点;其余放在随机节点,但避免一个机架多份备份。

相关文章推荐
- HDFS读写文件实例与解析
- php的SimpleXML方法读写XML接口文件实例解析
- Java nio(文件读写 实例解析)
- HDFS文件的读写操作理论解析
- php的SimpleXML方法读写XML接口文件实例解析
- php的SimpleXML方法读写XML接口文件实例解析
- Hadoop_HDFS文件读写代码流程解析和副本存放机制
- php的SimpleXML方法读写XML接口文件实例解析
- pcap文件的python解析实例
- HDFS读写过程解析(zz)
- Python 文件读写操作实例详解
- perl读写文件代码实例
- HDFS文件读写流程
- dom4解析xml格式文件实例
- HDFS基本的读写文件
- Nagios详解(基础、安装、配置文件解析及监控实例)
- JavaWeb实现文件上传下载功能实例解析
- JavaWeb实现文件上传下载功能实例解析
- mybatis实现物理分页准备之mybatis配置文件解析及实例
- dom4j 对xml文件循环解析简单实例