neo4j使用指南
2011-05-02 13:23
281 查看
目前neo4j文档只限于官方文档,本文将neo4j官方主要的文档整理了一下,供需要的人参考,内容也会不断更新!
ACID事务
高可用
可伸缩到亿级结点、关系
高速遍历
部署模式
Maven配置
安装
windows
从http://neo4j.org/下载
解压安装文件
配置环境变量:%NEO4J_HOME%和%PATH%
安装系统服务:%NEO4J_HOME%/bin/InstallNeo4j.bat
启动:%NEO4J_HOME%/bin/Neo4j.bat
Linux基本同windows
关键词
node:结点
relationship:关系
property:属性
indexer:索引器
traverser:遍历器
Get Started
一分钟向导
开始向导
基本使用样例
Domain Modeling
一个具体的例子:从建模到类设计到编码全过程
code tips
wrap nodes:将node包装
Subreferences:设置一个root的子引用结点(相当于namespace),再在此结点下建立你应用域的结点
工具neoclipse
开始
特点ACID事务
高可用
可伸缩到亿级结点、关系
高速遍历
部署模式
| Single Instance | Multiple Instances | |
| Embedded | EmbeddedGraphDatabase | HighlyAvailableGraphDatabase |
| Standalone | Neo4j Server | not yet available |
$HOME/.m2/setting.xml增加如下配置:<profiles><profile><repositories><repository><id>neo4j-public-repository</id><name>Publically available Maven 2 repository for Neo4j</name><url>http://m2.neo4j.org</url><snapshots><enabled>true</enabled></snapshots></repository></repositories></profile></profiles>
项目的pom.xml中增加如下配置:
<dependencies><dependency><groupId>org.neo4j</groupId><artifactId>neo4j</artifactId><version>{neo4j.version}</version></dependency></dependencies> 安装
windows
从http://neo4j.org/下载
解压安装文件
配置环境变量:%NEO4J_HOME%和%PATH%
安装系统服务:%NEO4J_HOME%/bin/InstallNeo4j.bat
启动:%NEO4J_HOME%/bin/Neo4j.bat
Linux基本同windows
关键词
node:结点
relationship:关系
property:属性
indexer:索引器
traverser:遍历器
Get Started
一分钟向导
开始向导
基本使用样例
neo4j建模
Design GuideDomain Modeling
一个具体的例子:从建模到类设计到编码全过程
code tips
wrap nodes:将node包装
Subreferences:设置一个root的子引用结点(相当于namespace),再在此结点下建立你应用域的结点
工具neoclipse
REST API
使用curl进行测试:curl -H http_header -X [GET,POST,PUT,DELETE] -d post_data your_url -H http的header -X http的类型 -d post的数据 Accept:application/json -- 可以接受的回复编码格式 Content-type:application/json -- 内容类型格式 例如: curl -H Accept:application/json -H Content-type:application/json -X GET http://localhost:7474/db/data/ curl -H Accept:application/json -H Content-Type:application/json -X post -d '{"key1":"value1"}' http://localhost:7474/db/data/node[/code]
更多REST API信息索引
分类
内部的自然索引:因为其本身就相当于tree结构(一般数据库也用tree做索引,如B树),被traverser使用作遍历
使用集成索引:如Lucene
可以对结点、关系进行索引
为了更新一个索引,必须先移除,再添加
某一索引按key缓存,可设置缓存大小:setCacheCapacity
旧索引机制
IndexService
不要实例化多个LuceneIndexService,因为内部其指向同一个index数据源
LuceneFulltextIndexService 和LuceneIndexService两者指向不同的index数据源
IndexService文档
新索引机制
索引文档事务
事务Overview
嵌套事务:只有一个高层事务,所有嵌套事务均在高层事务内
事务必须在try finally块中,事务必须显示success()
死锁
不要让事务太小(耗I/O),也不要太大(耗内存)
批量插入
特点:
用于数据初始化,批量写入
非事务
非线程安全
性能稍好
可能corrupt数据集
非批量插入时,内存被分配在堆外;在批量插入时,内存被分配在堆内;因此,需要保证足够的堆大小
Spring事务配置:具体见IMDB Example Transaction<tx:annotation-driven /><bean id="transactionManager"class="org.springframework.transaction.jta.JtaTransactionManager"><property name="transactionManager" ref="neo4jTransactionManagerService" /><property name="userTransaction" ref="neo4jUserTransactionService" /></bean><bean id="neo4jTransactionManagerService" class="org.neo4j.kernel.impl.transaction.SpringTransactionManager" /><bean id="neo4jUserTransactionService" class="org.neo4j.kernel.impl.transaction.UserTransactionImpl"><constructor-arg index="0" ref="graphDbService" /></bean>[/code]@Transactional public void newActors( final List<ActorData> actorList ){// code that operates on the graph}[/code]性能
性能关注
CPU:32位、64位
Memory:至少1G,推荐4~8G
Disk:至少SCSI、EIDE,推荐SSD、SATA
FileSystem :支持fsync,fdatasync,至少ext3,推荐ext4、zfs
Software:Java 1.6+,OS:Windows,Linux等性能调整(OS保留内存+File Mapping内存+JVM内存)
两个方面:caches和jvm
caches
File buffer cache(File Mapping)
低层次缓存,操作系统内存映射,尽可能使用操作系统特性
事务提交时,logic log被立即fdatasync to disk,但是数据文件不是被立即存flush到磁盘上,直到logic log进行了rotate,增长logic log大小可以减少flush到磁盘的次数(可以在conf/neo4j-wrapper.conf中的wrapper.logfile.maxsize参数配置)
防止不必要的page flush,配置OS当dirty page达到一定大小时才flush到磁盘(Linux OS参数配置)
延迟写,直到逻辑日志轮转(sync、fsync、fdatasync)
逻辑日志可用于崩溃恢复
定长记录
nodestore 9bytes
relationshipstore 33bytes
propertystore 25bytes(primitive属性)
stringstore 133bytes(指针存在propertystore中,具体数据存在此处,120bytes有效)
arraystore 133bytes(指针存在propertystore中,具体数据存在此处,120bytes有效)
可以配置缓存在JVM内存中,也可以不在JVM内存中
相关配置参数
use_memory_mapped_buffers:true使用操作系统内存mapping,false使用堆内存作映射
neostore.nodestore.db.mapped_memory:结点file memory mapping
neostore.relationshipstore.db.mapped_memory:关系file memory mapping
neostore.propertystore.db.mapped_memory:属性file memory mapping
neostore.propertystore.db.strings.mapped_memory:字符串属性file memory mapping
neostore.propertystore.db.arrays.mapped_memory:数组属性file memory mapping
string_block_size:property中类型string块大小,默认为120bytes(块大小在创建后不能改变,如果一个字符串大小大于块大小,字符串会分布在多个块中,有性能影响)
array_block_size:property中类型array块大小,默认为120bytes(块大小在创建后不能改变,同上)
dump_configuration:是否启动时dump配置
batch_inserter模式时,只需考虑node和relationship,因为在此模式下一般property在写入后不会读取,node和relationship因为会在其中保存属性等会被读取
Object cache
高层次缓存
以优化形式存储,利于快速遍历
缓存在JVM堆中
延迟加载策略
LRU策略
相关配置参数:cache_type:值为soft(default)(SoftReference)、weak(WeakReference)、none(始终保持在jvm中,容易OOM)
jvm
参数:-d32或-d64(32位或64位),-server,内存相关参数(内存大小、分代比例、线程堆栈大小-Xss(所有线程共享?))、垃圾收集器(推荐使用CMS收集器),OOM时自动产生内存dump
大量使用NIO包,很多堆外内存分配
要防止page in or out(观察swap交换情况,不要给OS保留太小内存)
要考虑jvm的pause time(暂停时间) / throughput(吞吐量)
NUMA structure:version 1.6.0 update 18实现,-XX:+UseNUMA
在堆中每个对象大小
Node:688bytes
Relationship:392bytes
Property:232bytes
Primitive:24bytes
String:(64 + 2 * len(string))bytes
Relationships:???
写性能:事务大小(事务小,I/O多;事务大,内存多);避免dirty page flushed to disk unexpectedly(不需要flush时flush)
更多配置,见Configuration Settings
更多性能,见Performance Guide配置
neo4j-wrapper.conf:logfile相关配置,jvm相关参数配置
conf/neo4j-server.properties:neo4j参数配置文件
org.neo4j.server.database.location:db位置,相对于NEO4J_HOME
org.neo4j.server.webserver.port:端口号,默认7474
org.neo4j.server.webadmin.rrdb.location:运行数据metrics信息文件,默认data/graph.db/../rrd
org.neo4j.server.webadmin.data.url:REST API endpoint url,默认/db/data/
org.neo4j.server.webadmin.management.uri:管理界面url,默认/db/manage/
org.neo4j.server.db.tuning.properties:指定性能参数配置文件,默认conf/neo4j.properties
conf/neo4j.properties:neo4j低层参数配置文件
conf/log4j.properties:log4j配置文件
conf/coord-wrapper.conf:ha结点启动相关配置
conf/coord.cfg:ha结点的zookeeper相关配置neo4j高可用部署
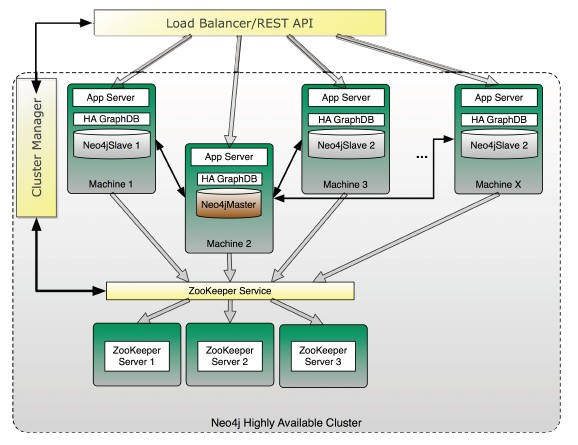
neo4j-ha架构图
功能
fault-tolerant
horizontally scaling
slave可写,同时同步到master,异步同步到其他他slave;对于master的写,会异步同步到slave
使用Apache Zookeeper保持各节点间的状态信息
HA配置参数
ha. machine_id:server id
ha. server:master的host和port
ha. zoo_keeper_servers:zookeeper连接,以逗号分隔
ha. pull_interval:slave从master拉数据的间隔
更多信息,见neo4j_ha_cluster
例子:examplesneo4j shell
配置文件加入:enable_remote_shell = true(默认端口为1337)或enable_remote_shell = port = 1331(指定端口)
neo4j-shell -host -port
man可以查找命令,具体命令参数用manneo4j备份
参数:keep_logical_logs:trueneo4j监控
监控,见Monitorneo4j安全
Trouble Shooting
neo4j中的所有api都是线程安全的,因此不需要额外的同步;串行,性能是否可以?相关文档
neo4j-manual-stable.pdf
相关wiki文档
stackoverflow中问题讨论



相关文章推荐
- neo4j使用指南
- neo4j使用指南
- redis桌面管理工具 redis-desktop-manager使用指南
- Cygwin使用指南
- [Python]MySQLdb for Python使用指南/Python的数据库操作
- 使用Python来编写HTTP服务器的超级指南
- vscode从听说到使用,vetur,prettier,htmljscssPrettify踩坑指南。
- 从菜鸟到精通--iPhone 4 使用指南(序言一)
- JQuery FlexiGrid的asp.net完美解决方案-dotNetFlexGrid使用指南(二)服务端查询、快速查询和Html模板
- ELK使用指南
- android EventBus 3.0使用指南
- Gradle2.0用户指南翻译——第十一章. 使用Gradle命令行
- QuickServer开发指南(7)- 使用和定制日志
- Android创建和使用数据库详细指南
- 白盒静态自动化测试工具:FindBugs使用指南
- openfiler和netapp使用指南参考网址
- Ant介绍以及基本使用指南
- 使用POI操作excel(读取和创建)快速开发指南
- FFmpeg滤镜文档-使用指南