某分布式应用实践一致性哈希的一些问题
2011-04-12 21:42
295 查看
出处: http://timyang.net/architecture/consistent-hashing-practice/
场景
假定一个有状态的服务,可以理解成web或者socket服务器,每个用户在这个服务上登录后是有状态的,我们把它的状态连同其他加载到内存的用户数据统称用户session。由于session数据实时会变化,加上程序访问session频率大,几乎所有的操作都跟session数据相关,因此不适合放在远程memcached中
第一阶段
考虑到单服务器不能承载,因此使用了分布式架构,最初的算法为 hash() mod n, hash()通常取用户ID,n为节点数。此方法容易实现且能够满足运营要求。缺点是当单点发生故障时,系统无法自动恢复。
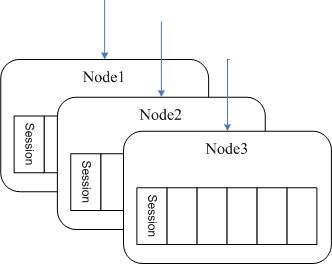
第二阶段
为了解决单点故障,使用 hash() mod (n/2), 这样任意一个用户都有2个服务器备选,可由client随机选取。由于不同服务器之间的用户需要彼此交互,所以所有的服务器需要确切的知道用户所在的位置。因此用户位置被保存到memcached中。
当一台发生故障,client可以自动切换到对应backup,由于切换前另外1台没有用户的session,因此需要client自行重新登录。
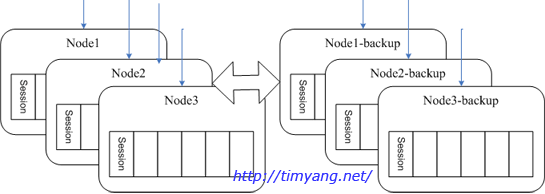
这个阶段的设计存在以下问题
负载不均衡,尤其是单台发生故障后剩下一台会压力过大。
不能动态增删节点
节点发生故障时需要client重新登录
第三阶段
打算去掉硬编码的hash() mod n 算法,改用一致性哈希(consistent hashing)分布
假如采用Dynamo中的strategy 1(可参看Dynamo: Amazon’s Highly Available Key-value Store, PDF, P216)
我们把每台server分成v个虚拟节点,再把所有虚拟节点(n*v)随机分配到一致性哈希的圆环上,这样所有的用户从自己圆环上的位置顺时针往下取到第一个vnode就是自己所属节点。当此节点存在故障时,再顺时针取下一个作为替代节点。
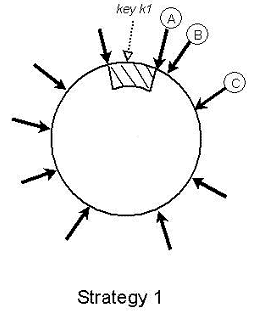
优点:发生单点故障时负载会均衡分散到其他所有节点,程序实现也比较优雅。
应用一致性哈希分布后若干问题
1.如何解决单点故障时候的session迁移?是否所有session都像Dynamo那样写入到多个节点(或双写)?如果双写所有的服务器需要消耗2倍的内存及更多CPU资源,所以优先不考虑双写方案。
2.如果不双写,则发生故障切换时,即使服务器内部自动帮用户切换节点不重新登录,都需要牵涉到大量session重建,会引起集群震荡。当然这里可以稍微优化,比如session按需建立,IDLE的用户可以先不重建。
3.当故障节点恢复时候如何处理?Dynamo的策略是故障期间所有的数据都属于hinted handoff, 就是备用机起业务代理作用,一旦故障机恢复就立即把所有临时数据从备用机拉回去,然后整个集群恢复正常流程。但由于本场景session数据比较笨重,而且牵涉到复制时存在并发变更,如果直接借鉴Dynamo的话则感觉切换成本过高,大部分开发人员倾向于继续用备用机处理该用户业务。如果恢复正常后不切换,则存在用户位置的不确定性,使用一致性哈希算出来的结果和用户实际所在的节点不同。需要顺着圆环往下找用户,效率很低。因此就有提议把所有用户所在的当前节点位置写入memcached。
5. 假如需要将位置写入memcached,那似乎一致性哈希算法又成了花瓶,完全可以由client在create session时候随机选取一个没有故障的节点, 然后把位置写入memcached, 某个节点发生故障时,client再另外选一个随机的,并把新的位置写入memcached, 所有用户所在节点的位置都通过memcached来存储,服务器之间实时的通讯也通过查询memcached来寻址。从实用的角度来看,这样似乎程序更简单。
因此,一致性哈希分布对于这个场景来说是无用的?
某分布式应用实践一致性哈希的一些问题
最近项目中一个分布式应用碰到一些设计问题,听过上次技术沙龙key value store漫谈的同学可能会比较容易理解以下说明。场景
假定一个有状态的服务,可以理解成web或者socket服务器,每个用户在这个服务上登录后是有状态的,我们把它的状态连同其他加载到内存的用户数据统称用户session。由于session数据实时会变化,加上程序访问session频率大,几乎所有的操作都跟session数据相关,因此不适合放在远程memcached中
第一阶段
考虑到单服务器不能承载,因此使用了分布式架构,最初的算法为 hash() mod n, hash()通常取用户ID,n为节点数。此方法容易实现且能够满足运营要求。缺点是当单点发生故障时,系统无法自动恢复。
第二阶段
为了解决单点故障,使用 hash() mod (n/2), 这样任意一个用户都有2个服务器备选,可由client随机选取。由于不同服务器之间的用户需要彼此交互,所以所有的服务器需要确切的知道用户所在的位置。因此用户位置被保存到memcached中。
当一台发生故障,client可以自动切换到对应backup,由于切换前另外1台没有用户的session,因此需要client自行重新登录。
这个阶段的设计存在以下问题
负载不均衡,尤其是单台发生故障后剩下一台会压力过大。
不能动态增删节点
节点发生故障时需要client重新登录
第三阶段
打算去掉硬编码的hash() mod n 算法,改用一致性哈希(consistent hashing)分布
假如采用Dynamo中的strategy 1(可参看Dynamo: Amazon’s Highly Available Key-value Store, PDF, P216)
我们把每台server分成v个虚拟节点,再把所有虚拟节点(n*v)随机分配到一致性哈希的圆环上,这样所有的用户从自己圆环上的位置顺时针往下取到第一个vnode就是自己所属节点。当此节点存在故障时,再顺时针取下一个作为替代节点。
优点:发生单点故障时负载会均衡分散到其他所有节点,程序实现也比较优雅。
应用一致性哈希分布后若干问题
1.如何解决单点故障时候的session迁移?是否所有session都像Dynamo那样写入到多个节点(或双写)?如果双写所有的服务器需要消耗2倍的内存及更多CPU资源,所以优先不考虑双写方案。
2.如果不双写,则发生故障切换时,即使服务器内部自动帮用户切换节点不重新登录,都需要牵涉到大量session重建,会引起集群震荡。当然这里可以稍微优化,比如session按需建立,IDLE的用户可以先不重建。
3.当故障节点恢复时候如何处理?Dynamo的策略是故障期间所有的数据都属于hinted handoff, 就是备用机起业务代理作用,一旦故障机恢复就立即把所有临时数据从备用机拉回去,然后整个集群恢复正常流程。但由于本场景session数据比较笨重,而且牵涉到复制时存在并发变更,如果直接借鉴Dynamo的话则感觉切换成本过高,大部分开发人员倾向于继续用备用机处理该用户业务。如果恢复正常后不切换,则存在用户位置的不确定性,使用一致性哈希算出来的结果和用户实际所在的节点不同。需要顺着圆环往下找用户,效率很低。因此就有提议把所有用户所在的当前节点位置写入memcached。
5. 假如需要将位置写入memcached,那似乎一致性哈希算法又成了花瓶,完全可以由client在create session时候随机选取一个没有故障的节点, 然后把位置写入memcached, 某个节点发生故障时,client再另外选一个随机的,并把新的位置写入memcached, 所有用户所在节点的位置都通过memcached来存储,服务器之间实时的通讯也通过查询memcached来寻址。从实用的角度来看,这样似乎程序更简单。
因此,一致性哈希分布对于这个场景来说是无用的?

相关文章推荐
- 某分布式应用实践一致性哈希的一些问题
- 某分布式应用实践一致性哈希的一些问题
- 某分布式应用实践一致性哈希的一些问题
- 某分布式应用实践一致性哈希的一些问题
- Linux环境下Weblogic部署应用的一些问题
- 今天你AJAX了没有?——关于AJAX应用所解决的一些常见问题
- 一个分布式应用的常见的设计问题
- 应用 Python 解决一些实际问题
- 总结yourphp应用过程中的一些问题及解决方法
- 由VOIP的应用想起的UDP的一些技术问题
- 关于背包问题的一些理解和应用
- Hadoop 2.8.2 和 Spark 2.1.0 分布式搭建及遇到的一些小问题
- 好开心呀,能用自己学习知识去做作业了,也算是解决一些问题吧。操作系统实践作业:短作业优先(SJF)和先来先服务算法(FCFS)
- Camera应用在调试中遇到的一些问题
- Java应用在运行时常见的一些问题
- 关于iOS应用设计的一些最佳实践
- DotNET企业架构应用实践-企业管理软件架构的历史与发展(中)- 分布式系统 推荐
- 表格和伪选择器的综合应用以及一些细节问题
- 关于百度定位申请应用AK的一些问题
- 本文简述了Ajax技术适用场景、Ajax不适用场景的具体情况以及应用时候存在的一些问题。