内存对齐,位段,大小端
2010-11-28 20:33
169 查看
1, 内存对齐
为什么要讨论内存对齐问题呢?因为最近在写BMP头文件的时候出现了些问题,后来发现是结构体中内存对齐所致的。
当时情况如下:
16 typedef struct
17 {
18 uint16_t identifier;
19 uint32_t file_size;
20 uint16_t reserved1;
21 uint16_t reserved2;
22 uint32_t bmp_offset;
23 }BITMAPFILEHEADER;
.
.
.
// 对这个结构体赋值
277 BITMAPFILEHEADER bfh;
278 memset(&bfh, 0, sizeof(BITMAPFILEHEADER));
279 bfh.identifier = 0x4d42; // 'B','M'
280 bfh.file_size = sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER) + rgb24_size;
281 bfh.reserved1 = 0;
282 bfh.reserved2 = 0;
283 bfh.bmp_offset = bfh.file_size - rgb24_size;
.
.
.
// 把这个结构体写入到头文件中
304 if (fwrite(&bfh, 14, 1, fp) < 0){
305 perror("write_rgb24_bmp:fwrite BITMAPFILEHEADER:");
306 return -1;
307 }
运行程序后,用十六进制格式查看文件,竟然多了个0000,一时十分不解。
0000000 4d42 0000 8438 0003 0000 0000 0038 0000
将内存中的数据写入文件时,文件中的数据排列与内存中的是一样的,所以肯定0000是分配结构体变量空间时所分配的一个字节。故对结构体变量成员内存空间的分配做了如下探讨。
先看一下程序:
1 #include
2 struct t1_stru
3 {
4 char ch;
5 int in;
6 short sh;
7 }t1;
8
9
10 int main()
11 {
12 t1.ch = 0x12; // 这三句赋值语句可以不用理会
13 t1.in = 0x3456789A;
14 t1.sh = 0xBCDE;
15 printf("sizeof(t1.ch)=%d/n", sizeof(t1.ch));
16 printf("sizeof(t1.in)=%d/n", sizeof(t1.in));
17 printf("sizeof(t1.sh)=%d/n", sizeof(t1.sh));
18 printf("sizeof(t1)=%d/n", sizeof(t1));
19 return 0;
20 }
输出结果:
sizeof(t1.ch)=1
sizeof(t1.in)=4
sizeof(t1.sh)=2
sizeof(t1)=12
为什么会出现这样的结果呢?其实是编译器其对结构体成员进行内存对齐的所导致的。
在默认情况下,C/C++的编译器会将结构体,栈中的成员进行内存对齐。
什么是内存对齐呢?即把成员安排在某一些符合某种规律的内存空间地址上,从而加快CPU对数据的读写速度。
如果想深入了解内存对齐如何加快CPU对数据的读写速度请参考:
Data alignment:Straighten up and fly right
http://www.ibm.com/developerworks/library/pa-dalign/
在讲述内存对齐规则之前,首先说明一下#pragma pack (n)语句
#pragma pack (n) 这个语句用于设置结构体的内存对齐方式,具体作用下面再说。在linux gcc 下n可取的值为:1,2,4,当n大于4时按4处理。如果程序中没用显试写出这个语句,那么在linux gcc下,它会对所有结构体都采用#pragma pack (4)的内存对齐方式。需要注意的是,在不同的编译平台上默认的内存对齐方式是不同的。如在VC中,默认是以#pragma pack (8) 的方式进行对齐。
#pragama pack (n)使用方法
#pragama pack (2)
struct structname
{
.
.
.
}
#pragama pack ()
上面表示在#pragama pack (2) 到 #pragama pack()之间采用n为2的内存对齐方式。#pragma pack () 表示取消自定义字节对齐方式,则在#pragama pack ()以下的程序不在使用#pragma pack (2) 的对齐方式,恢复#pragma pack (4) 这种编译器默认的对齐方式。当然没有#pragma pack ()也可以,那么则表示#pragma pack (2)以下到程序尾都采用此对齐方式。
内存对齐总规则:
结构体成员的地址必须安排在成员大小的整数倍上或者是#pragma pack(n) 所指定的n的倍数上;取两者的最小值,即MIN(sizeof(mem), n),称MIN(sizeof(mem), n)为该结构体的成员对齐模数。同时该结构体的总大小必须为MIN(n, MAX(sizeof(mem1), siezof(mem2)…))的整数倍;而称MIN(n, MAX(sizeof(mem1), siezof(mem2)…))为该结构体的对齐模数。
内存对齐细则:
下面的3条细则符合上面所说的总规则;这里的偏移指某一个数据成员的首地址到该结构体头的地址偏移。
(1) 对结构体的成员,第一个数据位于偏移为0的位置,以后每个数据成员的偏移量必须是成员对齐模数的倍数。
(2) 为结构体的一个成员开辟空间之前,编译器首先检查预开辟空间的偏移是否为成员对齐模数的整数倍,若是,则存放本成员,反之,则在本成员与上一成员之前填充一定的字节,从而达到整数倍的要求。
(3) 在数据成员完成自身的对齐后,结构体本身也要进行对齐。意思是该结构体的大小必须是结构体的对齐模数的整数倍。如果其大小不是,那么则在最后一个成员的后面填充字节。
首先计算出成员对齐模数与结构体的对齐模数:
ch_mod = MIN(4, sizeof(t1.ch)) = 1;
in_mod = MIN(4, sizeof(t1.in)) = 4;
sh_mod = MIN(4, sizeof(t1.sh)) = 2;
t1_mod = MIN(4, MAX(ch_mod, in_mod, sh_mod)) = 4;
然后用gdb调试上面的程序分析内存对齐的规则:
(gdb) p &t1
$1 = (struct t1_stru *) 0x80496d8 // t1结构体的首地址
(gdb) p &t1.ch
$2 = 0x80496d8 "" // ch的首地址
(gdb) p &t1.in
$3 = (int *) 0x80496dc // in的首地址
(gdb) p &t1.sh
$4 = (short int *) 0x80496e0 // sh的首地址
根据细则1:
可以知道t1的结构体的首地址就是t1结构体第一个成员ch的首地址。
根据细则2:
当为in开辟空间时,编译器检查预开辟空间的偏移,即ch后面一个一节的地址空间d9偏移,为1,不是in_mod的整数倍,所以向后找,一直到地址dc,偏移为4,刚好为in对齐模数的1倍,故在此开辟向后开辟4字节的地址空间。在d8与dc之间的地址中填充数据。
根据细则3:
当为sh分配空间后,此时结构体的大小为4+4+2 = 10, 10并不是t1_mod的整数倍,故在sh后填充两字节的数据,从而达到结构体自身的对齐。所以结构体总大小为12。
从下图可以看出该结构体成员赋值的过程:

再看一下程序:
1 #include
2 #include
3
4 struct t1_stru
5 {
6 uint8_t ch;
7 uint32_t in;
8 uint16_t sh;
9 };
10
11 struct t2_stru
12 {
13 uint8_t ch;
14 struct t1_stru t1;
15 uint16_t sh;
16 }t2;
17
18 int main()
19 {
20 t2.ch = 0x12;
21 t2.t1.ch = 0x23;
22 t2.t1.in = 0x3456789A;
23 t2.t1.sh = 0xABCD;
24 t2.sh = 0xACEF;
25 printf("sizeof(t2) = %d/n", sizeof(t2));
26 return 0;
27 }
输出结果为:
sizeof(t2) = 20
分析的方法跟上面的例子一样,当结构体中含有结构体时,计算其大小时,其实就是根据细则不断的嵌套的计算。
首先计算出t2成员对齐模数与t2结构体的对齐模数:
t2.ch_mod = MIN(4, sizeof(t2.ch) = 1;
t2.t1_mod = MIN(4, sizeof(t2.t1)) = MIN(4, 12) = 4;
(计算siezeof(t2.t1)则是按照上面的例子那样计算,得12)
t2.sh_mod = MIN(4, sizeof(t2.sh)) = 2;
t2_mod = MIN(4, MAX(t2.ch_mod, t2.t1_mod, t2.sh_mod)) = 4;
故sizeof(t2) = 20;
下图为t2的内存示意图:

2, 位段
位段是以位为单位定义结构体(或共用体)中成员所占存储空间的长度。含有位段的结构体类型成为位段结构。对于定义位段的变量类型只能为:字符型与整形。在Linux gcc 下,对不同类型的位段结构采用压缩存放的方法(下面规则的3,4点体现了不同类型的压缩存放的方法)。
位段结构的定义格式:类型 <成员名>:<占用位数>
在说明位段的一些规则前先解释一些名词的含义:
类型的存储单元:sizeof(类型)字节长度的内存空间
成员类型的位宽:sizeof(类型) * 8 bit
类型的存储单元位宽=成员类型的位宽
以下是位段的一些规则:
(1)第一个位段成员的偏移满足内存对齐的原则。
(2) 相邻的位段结构成员的类型相同。若它们的位宽之和不大于该类型的存储单元的位宽,则后面的成员紧接在前一个成员后;若否,则为后面的成员开辟一个新的存储单元。新的存储单元的偏移满足内存对齐的原则。
(3)相邻的位段结构成员的类型不同,前一成员类型的位宽大于后一成员类型的位宽。若前一成员所在的存储单元还有空间容纳后一成员,则把后一成员紧接在前一成员后;若否,则为后一成员开辟新的存储单元。新的存储单元的偏移满足内存对齐的原则。
(4)相邻的位段结构成员的类型不同,前一成员类型的位宽小于后一成员类型的位宽。若把前一成员所在的存储单元的位宽扩展为后一成员类型的位宽的大小后,能把后一成员容纳下的,则把对前一成员的存储单元进行位宽扩展,并把后一成员紧接在前一成员后;若否,则为后一成员开辟新的存储空间,其存储空间的偏移满足内存对齐的原则。(存储单元的位宽扩展的原则:若前一成员所在的字节单元的偏移不为后一成员大小的整数倍,则先向前兼并字节单元扩展,直到向前找到偏移为后一成员大小的整数倍的字节单元,此时判断扩展的位数是否足够,如果不够则从后开辟新字节单元进行扩展)
(5)可以通过定义长度为0的位段的方式使下一位段从下一存储单元开始。
(6)可以定义无名位段。
(7)定义位段时其长度不能大于存储单元的长度。
(5)位段无地址,不能对位段进行取地址运算。
(6)位段可以以%d,%o,%x格式输出。
(7)位段若出现在表达式中,将被系统自动转换成整数。
(8)位段的最大取值范围不要超出二进制位数定的范围,否则超出部分会丢弃。
下图是编译器分配位段空间时的算法流程:

看下面的列子:
1 #include
2 #include
3
4 struct s1_stru
5 {
6 uint8_t ch1:6;
7 uint8_t ch2:1;
8 uint16_t sh:2;
9 }t1;
10
11 struct s2_stru
12 {
13 uint8_t ch:7;
14 uint16_t sh:9;
15 }t2;
16
17 struct s3_stru
18 {
19 uint8_t ch:7;
20 uint16_t sh:10;
21 }t3;
22
23 struct s4_str
24 {
25 uint8_t ch:7;
26 uint16_t sh:10;
27 uint32_t in:1;
28 uint16_t sh2:2;
29 }t4;
30
31 struct s5_stru
32 {
33 uint8_t ch1:4;
34 uint16_t sh1:10;
35 uint32_t in1;
36 uint8_t ch2:4;
37 uint16_t sh2:4;
38
39 }t5;
40
41 int main(void)
42 {
43 t1.ch1 = 0b111111;
44 t1.ch2 = 0b1;
45 t1.sh = 0b11;
46 t2.ch = 0b1111111;
47 t2.sh = 0b111111111;
48 t3.ch = 0b1111111;
49 t3.sh = 0b1111111111;
50 t4.ch = 0b1111111;
51 t4.sh = 0b1111111111;
52 t4.in = 0b1;
53 t4.sh2 = 0b11;
54 t5.ch1 = 0b1111;
55 t5.sh1 = 0b1111111111;
56 t5.in1 = 0xFFFFFFFF;
57 t5.ch2 = 0b1111;
58 t5.sh2 = 0b1111;
59 printf("sizeof(t1)=%d/n", sizeof(t1));
60 printf("sizeof(t2)=%d/n", sizeof(t2));
61 printf("sizeof(t3)=%d/n", sizeof(t3));
62 printf("sizeof(t4)=%d/n", sizeof(t4));
63 printf("sizeof(t5)=%d/n", sizeof(t5));
64 return 0;
65 }
输出结果:
sizeof(t1)=2
sizeof(t2)=2
sizeof(t3)=4
sizeof(t4)=4
sizeof(t5)=12
结构体变量t1的内存示意图:这幅图说明了两种情况,一是同位段类型的且能够存放在同一存储单元;二是不同位段类型的,但是经过位宽扩展后能够存放在同一单元的。

结构体变量t3的内存示意图:这幅图说明了不同类型的位段成员间需要开辟新空间的情况。

结构体变量t4的内存示意图:这幅图是上面两幅图情况的综合。

下面用图说明一下存储单元位宽扩展的原则
struct examp1
{
uint8_t ch1:7;
uint32_t in1:3;
};
ch1所在偏移为0,是in1类型的大小的整数倍,故从ch1向后开辟新空间扩展。一共开辟3个字节。
struct exampl2
{
uint8_t ch1:7;
uint8_t ch2:7;
uint32_t in1:3;
};
ch2所在的偏移为1,不是in1类型的大小的整数倍,故先从ch2向前兼并字节单元,直到找到偏移为in1类型的大小的整数倍的地址。可知,ch1所在的空间为in1类型的大小的整数倍。故一共向前兼并了1个字节,但是还差两个字节,所以要从ch2向后再开辟两个字节的空间。
类似的有以下两幅图:
struct exampl3
{
uint8_t ch1:7;
uint8_t ch2:7;
uint8_t ch3:7;
uint32_t in1:3;
};
struct exampl4
{
uint8_t ch1:7;
uint8_t ch2:7;
uint8_t ch3:7;
uint8_t ch4:7;
uint32_t in1:3;
};
3,结合位段结构再谈大小端
1 #include
2 #include
3 struct s1_srtuct
4 {
5 uint8_t b1:1;
6 uint8_t b2:1;
7 uint8_t b3:1;
8 uint8_t b4:1;
9 uint8_t b5:1;
10 uint8_t b6:1;
11 uint8_t b7:1;
12 uint8_t b8:1;
13 }t1;
14
15
16 int main(void)
17 {
18 uint8_t *p = (uint8_t *)&t1;
19 t1.b1 = 1;
20 printf("t1=%d/n", *p);
21 return 0;
22 }
输出结果:
t1=1
在linux gcc下,结构体成员空间而是按照由地址低到地址高的顺序分配的。又因为linux是为小端模式的系统,故输出为t1=1;若程序运行在大端模式的系统上,输出则为t1=128。
为什么要讨论内存对齐问题呢?因为最近在写BMP头文件的时候出现了些问题,后来发现是结构体中内存对齐所致的。
当时情况如下:
16 typedef struct
17 {
18 uint16_t identifier;
19 uint32_t file_size;
20 uint16_t reserved1;
21 uint16_t reserved2;
22 uint32_t bmp_offset;
23 }BITMAPFILEHEADER;
.
.
.
// 对这个结构体赋值
277 BITMAPFILEHEADER bfh;
278 memset(&bfh, 0, sizeof(BITMAPFILEHEADER));
279 bfh.identifier = 0x4d42; // 'B','M'
280 bfh.file_size = sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER) + rgb24_size;
281 bfh.reserved1 = 0;
282 bfh.reserved2 = 0;
283 bfh.bmp_offset = bfh.file_size - rgb24_size;
.
.
.
// 把这个结构体写入到头文件中
304 if (fwrite(&bfh, 14, 1, fp) < 0){
305 perror("write_rgb24_bmp:fwrite BITMAPFILEHEADER:");
306 return -1;
307 }
运行程序后,用十六进制格式查看文件,竟然多了个0000,一时十分不解。
0000000 4d42 0000 8438 0003 0000 0000 0038 0000
将内存中的数据写入文件时,文件中的数据排列与内存中的是一样的,所以肯定0000是分配结构体变量空间时所分配的一个字节。故对结构体变量成员内存空间的分配做了如下探讨。
先看一下程序:
1 #include
2 struct t1_stru
3 {
4 char ch;
5 int in;
6 short sh;
7 }t1;
8
9
10 int main()
11 {
12 t1.ch = 0x12; // 这三句赋值语句可以不用理会
13 t1.in = 0x3456789A;
14 t1.sh = 0xBCDE;
15 printf("sizeof(t1.ch)=%d/n", sizeof(t1.ch));
16 printf("sizeof(t1.in)=%d/n", sizeof(t1.in));
17 printf("sizeof(t1.sh)=%d/n", sizeof(t1.sh));
18 printf("sizeof(t1)=%d/n", sizeof(t1));
19 return 0;
20 }
输出结果:
sizeof(t1.ch)=1
sizeof(t1.in)=4
sizeof(t1.sh)=2
sizeof(t1)=12
为什么会出现这样的结果呢?其实是编译器其对结构体成员进行内存对齐的所导致的。
在默认情况下,C/C++的编译器会将结构体,栈中的成员进行内存对齐。
什么是内存对齐呢?即把成员安排在某一些符合某种规律的内存空间地址上,从而加快CPU对数据的读写速度。
如果想深入了解内存对齐如何加快CPU对数据的读写速度请参考:
Data alignment:Straighten up and fly right
http://www.ibm.com/developerworks/library/pa-dalign/
在讲述内存对齐规则之前,首先说明一下#pragma pack (n)语句
#pragma pack (n) 这个语句用于设置结构体的内存对齐方式,具体作用下面再说。在linux gcc 下n可取的值为:1,2,4,当n大于4时按4处理。如果程序中没用显试写出这个语句,那么在linux gcc下,它会对所有结构体都采用#pragma pack (4)的内存对齐方式。需要注意的是,在不同的编译平台上默认的内存对齐方式是不同的。如在VC中,默认是以#pragma pack (8) 的方式进行对齐。
#pragama pack (n)使用方法
#pragama pack (2)
struct structname
{
.
.
.
}
#pragama pack ()
上面表示在#pragama pack (2) 到 #pragama pack()之间采用n为2的内存对齐方式。#pragma pack () 表示取消自定义字节对齐方式,则在#pragama pack ()以下的程序不在使用#pragma pack (2) 的对齐方式,恢复#pragma pack (4) 这种编译器默认的对齐方式。当然没有#pragma pack ()也可以,那么则表示#pragma pack (2)以下到程序尾都采用此对齐方式。
内存对齐总规则:
结构体成员的地址必须安排在成员大小的整数倍上或者是#pragma pack(n) 所指定的n的倍数上;取两者的最小值,即MIN(sizeof(mem), n),称MIN(sizeof(mem), n)为该结构体的成员对齐模数。同时该结构体的总大小必须为MIN(n, MAX(sizeof(mem1), siezof(mem2)…))的整数倍;而称MIN(n, MAX(sizeof(mem1), siezof(mem2)…))为该结构体的对齐模数。
内存对齐细则:
下面的3条细则符合上面所说的总规则;这里的偏移指某一个数据成员的首地址到该结构体头的地址偏移。
(1) 对结构体的成员,第一个数据位于偏移为0的位置,以后每个数据成员的偏移量必须是成员对齐模数的倍数。
(2) 为结构体的一个成员开辟空间之前,编译器首先检查预开辟空间的偏移是否为成员对齐模数的整数倍,若是,则存放本成员,反之,则在本成员与上一成员之前填充一定的字节,从而达到整数倍的要求。
(3) 在数据成员完成自身的对齐后,结构体本身也要进行对齐。意思是该结构体的大小必须是结构体的对齐模数的整数倍。如果其大小不是,那么则在最后一个成员的后面填充字节。
首先计算出成员对齐模数与结构体的对齐模数:
ch_mod = MIN(4, sizeof(t1.ch)) = 1;
in_mod = MIN(4, sizeof(t1.in)) = 4;
sh_mod = MIN(4, sizeof(t1.sh)) = 2;
t1_mod = MIN(4, MAX(ch_mod, in_mod, sh_mod)) = 4;
然后用gdb调试上面的程序分析内存对齐的规则:
(gdb) p &t1
$1 = (struct t1_stru *) 0x80496d8 // t1结构体的首地址
(gdb) p &t1.ch
$2 = 0x80496d8 "" // ch的首地址
(gdb) p &t1.in
$3 = (int *) 0x80496dc // in的首地址
(gdb) p &t1.sh
$4 = (short int *) 0x80496e0 // sh的首地址
根据细则1:
可以知道t1的结构体的首地址就是t1结构体第一个成员ch的首地址。
根据细则2:
当为in开辟空间时,编译器检查预开辟空间的偏移,即ch后面一个一节的地址空间d9偏移,为1,不是in_mod的整数倍,所以向后找,一直到地址dc,偏移为4,刚好为in对齐模数的1倍,故在此开辟向后开辟4字节的地址空间。在d8与dc之间的地址中填充数据。
根据细则3:
当为sh分配空间后,此时结构体的大小为4+4+2 = 10, 10并不是t1_mod的整数倍,故在sh后填充两字节的数据,从而达到结构体自身的对齐。所以结构体总大小为12。
从下图可以看出该结构体成员赋值的过程:

再看一下程序:
1 #include
2 #include
3
4 struct t1_stru
5 {
6 uint8_t ch;
7 uint32_t in;
8 uint16_t sh;
9 };
10
11 struct t2_stru
12 {
13 uint8_t ch;
14 struct t1_stru t1;
15 uint16_t sh;
16 }t2;
17
18 int main()
19 {
20 t2.ch = 0x12;
21 t2.t1.ch = 0x23;
22 t2.t1.in = 0x3456789A;
23 t2.t1.sh = 0xABCD;
24 t2.sh = 0xACEF;
25 printf("sizeof(t2) = %d/n", sizeof(t2));
26 return 0;
27 }
输出结果为:
sizeof(t2) = 20
分析的方法跟上面的例子一样,当结构体中含有结构体时,计算其大小时,其实就是根据细则不断的嵌套的计算。
首先计算出t2成员对齐模数与t2结构体的对齐模数:
t2.ch_mod = MIN(4, sizeof(t2.ch) = 1;
t2.t1_mod = MIN(4, sizeof(t2.t1)) = MIN(4, 12) = 4;
(计算siezeof(t2.t1)则是按照上面的例子那样计算,得12)
t2.sh_mod = MIN(4, sizeof(t2.sh)) = 2;
t2_mod = MIN(4, MAX(t2.ch_mod, t2.t1_mod, t2.sh_mod)) = 4;
故sizeof(t2) = 20;
下图为t2的内存示意图:

2, 位段
位段是以位为单位定义结构体(或共用体)中成员所占存储空间的长度。含有位段的结构体类型成为位段结构。对于定义位段的变量类型只能为:字符型与整形。在Linux gcc 下,对不同类型的位段结构采用压缩存放的方法(下面规则的3,4点体现了不同类型的压缩存放的方法)。
位段结构的定义格式:类型 <成员名>:<占用位数>
在说明位段的一些规则前先解释一些名词的含义:
类型的存储单元:sizeof(类型)字节长度的内存空间
成员类型的位宽:sizeof(类型) * 8 bit
类型的存储单元位宽=成员类型的位宽
以下是位段的一些规则:
(1)第一个位段成员的偏移满足内存对齐的原则。
(2) 相邻的位段结构成员的类型相同。若它们的位宽之和不大于该类型的存储单元的位宽,则后面的成员紧接在前一个成员后;若否,则为后面的成员开辟一个新的存储单元。新的存储单元的偏移满足内存对齐的原则。
(3)相邻的位段结构成员的类型不同,前一成员类型的位宽大于后一成员类型的位宽。若前一成员所在的存储单元还有空间容纳后一成员,则把后一成员紧接在前一成员后;若否,则为后一成员开辟新的存储单元。新的存储单元的偏移满足内存对齐的原则。
(4)相邻的位段结构成员的类型不同,前一成员类型的位宽小于后一成员类型的位宽。若把前一成员所在的存储单元的位宽扩展为后一成员类型的位宽的大小后,能把后一成员容纳下的,则把对前一成员的存储单元进行位宽扩展,并把后一成员紧接在前一成员后;若否,则为后一成员开辟新的存储空间,其存储空间的偏移满足内存对齐的原则。(存储单元的位宽扩展的原则:若前一成员所在的字节单元的偏移不为后一成员大小的整数倍,则先向前兼并字节单元扩展,直到向前找到偏移为后一成员大小的整数倍的字节单元,此时判断扩展的位数是否足够,如果不够则从后开辟新字节单元进行扩展)
(5)可以通过定义长度为0的位段的方式使下一位段从下一存储单元开始。
(6)可以定义无名位段。
(7)定义位段时其长度不能大于存储单元的长度。
(5)位段无地址,不能对位段进行取地址运算。
(6)位段可以以%d,%o,%x格式输出。
(7)位段若出现在表达式中,将被系统自动转换成整数。
(8)位段的最大取值范围不要超出二进制位数定的范围,否则超出部分会丢弃。
下图是编译器分配位段空间时的算法流程:

看下面的列子:
1 #include
2 #include
3
4 struct s1_stru
5 {
6 uint8_t ch1:6;
7 uint8_t ch2:1;
8 uint16_t sh:2;
9 }t1;
10
11 struct s2_stru
12 {
13 uint8_t ch:7;
14 uint16_t sh:9;
15 }t2;
16
17 struct s3_stru
18 {
19 uint8_t ch:7;
20 uint16_t sh:10;
21 }t3;
22
23 struct s4_str
24 {
25 uint8_t ch:7;
26 uint16_t sh:10;
27 uint32_t in:1;
28 uint16_t sh2:2;
29 }t4;
30
31 struct s5_stru
32 {
33 uint8_t ch1:4;
34 uint16_t sh1:10;
35 uint32_t in1;
36 uint8_t ch2:4;
37 uint16_t sh2:4;
38
39 }t5;
40
41 int main(void)
42 {
43 t1.ch1 = 0b111111;
44 t1.ch2 = 0b1;
45 t1.sh = 0b11;
46 t2.ch = 0b1111111;
47 t2.sh = 0b111111111;
48 t3.ch = 0b1111111;
49 t3.sh = 0b1111111111;
50 t4.ch = 0b1111111;
51 t4.sh = 0b1111111111;
52 t4.in = 0b1;
53 t4.sh2 = 0b11;
54 t5.ch1 = 0b1111;
55 t5.sh1 = 0b1111111111;
56 t5.in1 = 0xFFFFFFFF;
57 t5.ch2 = 0b1111;
58 t5.sh2 = 0b1111;
59 printf("sizeof(t1)=%d/n", sizeof(t1));
60 printf("sizeof(t2)=%d/n", sizeof(t2));
61 printf("sizeof(t3)=%d/n", sizeof(t3));
62 printf("sizeof(t4)=%d/n", sizeof(t4));
63 printf("sizeof(t5)=%d/n", sizeof(t5));
64 return 0;
65 }
输出结果:
sizeof(t1)=2
sizeof(t2)=2
sizeof(t3)=4
sizeof(t4)=4
sizeof(t5)=12
结构体变量t1的内存示意图:这幅图说明了两种情况,一是同位段类型的且能够存放在同一存储单元;二是不同位段类型的,但是经过位宽扩展后能够存放在同一单元的。

结构体变量t3的内存示意图:这幅图说明了不同类型的位段成员间需要开辟新空间的情况。
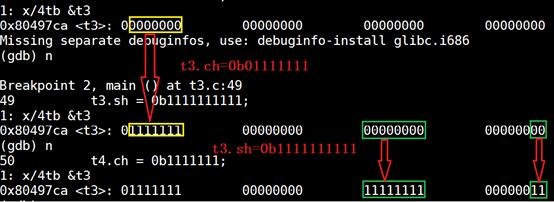
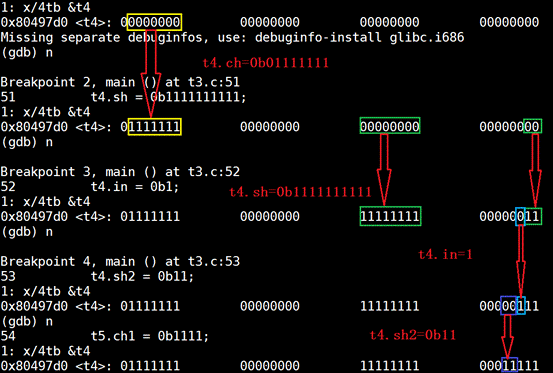
结构体变量t4的内存示意图:这幅图是上面两幅图情况的综合。
下面用图说明一下存储单元位宽扩展的原则
struct examp1
{
uint8_t ch1:7;
uint32_t in1:3;
};
| 偏移: | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 类型: | ch1 |
struct exampl2
{
uint8_t ch1:7;
uint8_t ch2:7;
uint32_t in1:3;
};
| 偏移: | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 类型: | ch1 | ch2 |
类似的有以下两幅图:
struct exampl3
{
uint8_t ch1:7;
uint8_t ch2:7;
uint8_t ch3:7;
uint32_t in1:3;
};
| 偏移: | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 类型: | ch1 | ch2 | ch3 |
{
uint8_t ch1:7;
uint8_t ch2:7;
uint8_t ch3:7;
uint8_t ch4:7;
uint32_t in1:3;
};
| 偏移: | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 类型: | ch1 | ch2 | ch3 | ch4 |
1 #include
2 #include
3 struct s1_srtuct
4 {
5 uint8_t b1:1;
6 uint8_t b2:1;
7 uint8_t b3:1;
8 uint8_t b4:1;
9 uint8_t b5:1;
10 uint8_t b6:1;
11 uint8_t b7:1;
12 uint8_t b8:1;
13 }t1;
14
15
16 int main(void)
17 {
18 uint8_t *p = (uint8_t *)&t1;
19 t1.b1 = 1;
20 printf("t1=%d/n", *p);
21 return 0;
22 }
输出结果:
t1=1
在linux gcc下,结构体成员空间而是按照由地址低到地址高的顺序分配的。又因为linux是为小端模式的系统,故输出为t1=1;若程序运行在大端模式的系统上,输出则为t1=128。

相关文章推荐
- 内存对齐,位段,大小端
- 关于C++中的大小端、位段(惑位域)和内存对齐
- 关于大小端、内存对齐 转
- c语言数据类型 之 内存对齐与位段
- 大端和小端--内存对齐问题
- 计算机大端模式和小端模式 内存对齐问题(sizeof)[密码学哈希密码部分参考]
- C++随记总结(1)----关于C++中的大小端、位段(惑位域)和内存对齐
- 计算机大端模式和小端模式 内存对齐问题(sizeof)
- [转]位域、大小端、内存对齐
- 大端小端区别、Union和Struct的内存分配、对齐方式
- 大端和小端--内存对齐问题
- 关于C++中的大小端、位段(惑位域)和内存对齐
- 经典面试题 之 大小端 & 内存对齐补齐
- 大端和小端--内存对齐问题
- C++11中枚举enum和union,顺带说一下内存对齐和大小端问题
- 计算机大端模式和小端模式 内存对齐问题(sizeof)
- 关于C++中的大小端、位段(惑位域)和内存对齐
- C++随记总结(1)----关于C++中的大小端、位段(惑位域)和内存对齐
- CPP--借助神器VS理解内存存储(含大小端对齐)
- 大小端、位段和内存对齐