SHADER 学习笔记 (2)
2010-11-27 00:25
363 查看
不同的寄存器有不同的功能:
♦ 输入寄存器从顶点缓冲中读取数据
♦ 常量寄存器提供ALU计算需要用到的各种常量
♦ 临时寄存器存储shader计算用到的临时变量
♦ 输出寄存器存放shader程序计算的结果
shader程序的布局
一个汇编着色程序包含不同类型的指令,就像其他编程语言一样,一些指令必须在其他指令前出现。指令可被分为如下几部分:
♢ 版本声明
♢ 注释
♢ 常量
♢ 输入寄存器声明
♢ 操作指令
下面是一个例子:

在每个着色程序中的第一条指令,必须是一个版本声明,这个指令指出着色程序要汇编成的对应版本的代码。本例代码可以在支持vs_1_1的硬件上运行.
注释可以出现在shader程序的任何位置,跟"//"和";"以及"/*...*/"都是注意标记,跟C语言风格类似.
常量可以在程序中设置,也可以在shader代码中通过"def"声明.这些常量按照只读方式被shader读取.每个寄存器可以存放4个值.
输入寄存器,使用前必须用语义关联,因为shader要和输入的顶点缓冲中的数据对应.例子中,v0和缓冲中的位置坐标绑定在一起.
一旦常量和输入寄存器被声明后,就可以使用操作指令来编写shader程序.
----------------------------------------------------------------------------------------
寄存器
不同的寄存器有不同的用途.输入寄存器负责给ALU提供数据.运行时的数据流从顶点缓冲传输进输入寄存器,输入寄存器在把数据提供给ALU.顶点shader的结果写进输出寄存器,然后,结果放回渲染管线以供图元处理.
其他的输入寄存器包括常量寄存器,存储临时值的临时寄存器等.下表展示了各种输入寄存器的类型:
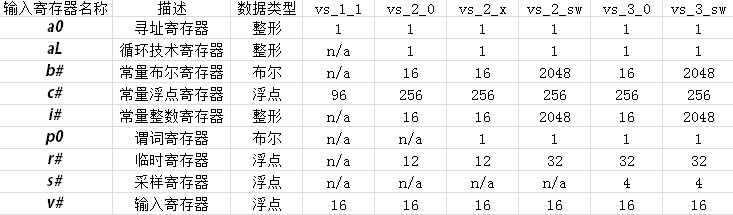
输入寄存器表.(ps: n/a表示该版本下不可用)
a0:一个间接寄存器,可以通过它当一个索引来寻址常量寄存器.在vs_1_1中,只有a0.x可以使用,在其后的版本中所有分量都可以访问.
aL:一个控制最大循环次数的整形计数器.
b#:容纳callnz指令的比较条件.
c#:浮点通用寄存器.
i#:整形常量寄存器,控制loop指令
p0:谓词寄存器,提供按每个分量进行流控制的功能:即,当分量的值为真时该分量才进行指定的操作.
r#:临时寄存器,用于存取临时计算结果,与常量寄存器的不同是,该寄存器是可读可写的,常量寄存器是只读的.
s#:采样寄存器.当纹理被采样时纹素的色彩被写进采样寄存器中.
v#:输入寄存器.顶点缓冲将数据传进顶点shder中预先声明的输入寄存器中.
读端口限制者一条指令同时能读多少个寄存器.具体详细的说明可以参考SDK.一般情况下超过读端口限制会返回一条错误信息.
所有设备通过caps指定他们的特性集.每一种caps都包含在D3DCAPS9结构中.测试caps的简单途径是使用CMyD3DApplication::ConfirmDevices方法,该方法包含在SDK的例子中.

输出寄存器类型(ps:*表示介于0和资源数目的整数)
在所有vs_3_0前的版本中,oD0包含漫反射值,oD1包含镜面反射值.oPos值必须保证被写入值.
在vs_3_0及其后,输出寄存器整合成12个o#寄存器.每个o#寄存器可以当作像素shader插值操作用的参数.另外,输出寄存器现在需要声明.该声明将语义绑定给寄存器,将顶点shader的输出绑定给像素shader的输入.
♦ 所有12个4分量寄存器中,必须有一个声明为位置寄存器.
♦ 所有寄存器使用前必须声明.
在早起的shader模型中,只有c#寄存器可以被索引.在vs_3_0中,v#和0#也可以用a0索引.
----------------------------------------------------------------------------------------
操作指令
指令决定两件事:什么时候数据从寄存器传到ALU;ALU要对数据进行什么操作.有以下集中类型的操作指令:
■ 预设指令
■ 算数指令
■ 宏操作指令
■ 纹理指令
■ 流控制指令
预设指令用于声明shader程序版本和常量.算术指令提供数学操作.宏指令提供高级的函数功能,比如叉乘和线性插值.纹理指令用于采样纹理,流控制指令控制哪些指令被执行.
每个版本的shder支持一个最大数量的指令槽.如果超过这个数量,指令会失效.随着版本的提升,指令槽的最大限制数量不断在提高.下表是各版本指令槽的最大指令容纳数目:
vs_1_1 128
vs_2_0 256
vs_2_x 256
vs_2_sw 无限
vs_3_0 512
vs_3_sw 无限
预设指令:用于初始化,比如声明shader版本,定义常量,声明寄存器.

算数指令:提供数学运算.数目较多,可查阅SDK.
宏指令:组合了一些算数指令,并且经过特殊优化,建议采用.详细可查阅SDK.
纹理指令:3.0的东西,暂时用不到.
流控制指令:提供分支计算,详情查阅SDK.
----------------------------------------------------------------------------------------
修饰符扩展:

修饰符不占用指令槽。
操作指令修饰符调整对数据的操作,_sat在数据写入到目标寄存器前把数据值夹值在0到1。后面的_pp修饰符指明允许使用低精度指令.但是有写指令不支持_sat修饰符,比如frc和sincos,还有纹理指令,并且目标寄存器不能为o#.
目标寄存器修饰符影响结果如何写入目标寄存器.特别的,一个写掩码控制目标写入的寄存器分量是哪些.另外,写掩码必须按照分量的顺序排列,不管有多少个分量需要写入.比如.rga和.xw是有效的掩码.没使用掩码表示四个分量全写入.
源寄存器修饰符在数据从源寄存器拷贝到ALU前修改数据.(源寄存器中的值不被改变.)源寄存器前的修饰符有负数,绝对值,绝对值后取负三种,在源寄存器后只有混淆这一种.
■ 负数修饰符:如果需要源数据的相反数,只需要在源寄存器前加一个"-"即可.
■ 绝对值修饰符:保证结果是一个数的绝对值.
■ 绝对值后取负:先获得绝对值后对其取负.
■ 混淆:控制被读取的源寄存器分量.混淆不影响源寄存器的数据,因为一个采用混淆修饰的源寄存器在指令操作前先被拷贝到一个临时区域.
----------------------------------------------------------------------------------------
顶点shader不同版本的不同之处:
你应该使用什么版本的顶点shder?你需要静态流控制么?是否要支持纹理采样?也许你厌倦了编写低级的函数并且想使用较高级的宏指令来减轻工作量并且提升性能.一般来说,尽量使用高版本的shader,既能提升性能,又方便将你的shader转换成日后更高级版本的shader程序.当然前提你的硬件需要支持.
DirectX9支持以下几个版本的着色器:
vs_1_1
vs_2_0,vs_2_x,vs_2_sw
vs_3_0,vs_3_sw
vs_1_1是最早的版本.它包含错有基本的寄存器类型:输入,输出,常量,临时和一个寻址寄存器.操作指令集包含所有基本算术指令和几乎一半的宏指令.不支持流控制.
vs_2_0添加一些新的算术指令诸如:abs,crs和一些宏操作指令如lrp,nrm,pow,sgn,sincos等.但是最大的改进是支持静态流控制指令,诸如:if-else-endif,call,loop, rep.shader首次可以采用流控制决定运行分支.为了支持该功能,增加了布尔和整形寄存器.
vs_2_x引入了动态流控制,诸如:break_comp,break_pred,if_comp,if_pred.断言同样被引进指令的执行.
vs_2_sw是纯软件版本的shader,速度很慢,不做过多介绍.
vs_3_0,输出寄存器简化成一种类型的寄存器:o#.因此输出寄存器需要声明相应语义连接像素shader.vs_3_0同样支持断言的动态流控制但不需要像_2_0那样设置caps的标志位.vs_3_0同样支持纹理采样并控制顶点流序列,使用户可以在流重置后仍然有控制能力.
vs_3_sw是_3_0的软件版本,很慢,不多说了.

相关文章推荐
- Shader之学习笔记二
- Unity Shader 学习笔记 (八) 语义词与语义绑定
- Unity Shader入门精要学习笔记 - 第4章 学习 Shader 所需的数学基础
- Shader 学习笔记 20151110
- 【Unity Shaders】学习笔记——SurfaceShader(七)法线贴图
- Unity Shader入门精要学习笔记 - 第8章 透明效果
- 【Unity Shaders】学习笔记——SurfaceShader(八)生成立方图
- unity之shader学习笔记(四)--高光反射
- Shader 学习笔记 20151112
- NVIDIA cg语言编写shader的学习笔记
- Unity Shader 学习笔记(25) 全局雾效
- 【Unity Shaders】学习笔记——Shader和渲染管线
- Unity3D Shaderlab实战学习笔记 一 (《shaders for game programmers and artists》实践)
- cocos2d-x 3.1.1 学习笔记[15] Shader 著色器
- [Unity3D]Shader学习笔记之点和矢量
- 【Unity Shaders】学习笔记——SurfaceShader(十)镜面反射
- Unity Shader 学习笔记 (七) 根据切线和法线方向设置模型颜色shader
- [Unity Shader]Shader学习笔记5 - ShaderLab语法: SubShader
- UnityShader入门精要学习笔记(十七):顶点动画
- 学习Unity3d Shader笔记:用到的一些对象和关键字纪录