《Data-Intensive Text Processing with MapReduce》第4章-压缩
2010-05-23 08:40
387 查看
在用map-reduce进行倒排索引的建立的时候,进入文档的编号已经有序了,按照升序排序,这时候可以对文档编号进行压缩。例如,最开始的时候文档序列如下:

通过“相邻差”的方式对文档id进行压缩,结果如下

,第二个文档的文档号7保存成第一个文档与第二个文档的差值,2=7-5,同理,第3个文档12保存成与第二个文档的差值,5=12-7。。。。,采取这种方式,差值的最差情况是:最大文档号-最小文档号。
从数字的角度来看, 缺失降低了数字的大小,但是从占用空间的角度来讲,并没有降低数字的大小。int类型假如占4个字节的话,那么可以存储的最大的非负整数是2**32,所以, 数字7和数字12都是占用同样4字节的空间。问题的核心是采用了int类型的定长编码方式,如果采取非定长编码,则可以解决这个问题。

用1个字节编码,

用两个字节编码,

用三个字节。。。
127,128的编码如下,
1 1111111, 0 0000001 1 0000000,这种编码的坏处是解码的时候,需要移位运算,还有frequent branch mispredict。
一种改进的办法是Jeff Dean在WSDM上提出的办法,将每四个字节一起编码,然后用一个字节的prefix来表示后续四个字节的长度,例如00,00,01,10表示后续的4个字节的长度分别是1,1,2,3字节。这样一组的的长度最短是5个字节,最长的长度是17个字节。将所有的前缀(prefix)表存起来,在进行解码的时候直接查表,就能将后续4个字节一起解析出来。通过这种方式比上面的varInt方式速度能提高2倍。
对于大多数机器体系,常常一下子读入一个字的长度,因此基于字对齐的压缩编码更常用,其中最常用的是simple-9,基于32bit,4字节的编码。32bit中4bit保留作为selector,剩余的28bit用来对数据进行编码。例如28bit可以存储28个1bit的数据,或者14个2bit的数据。。直到3个9bit的数据(有一位未使用),公有9种方式,所有交simple-9。

其中,unary是最简单的前缀编码。一个数字x表示成x-1个1,然后在结尾加一个0完成编码。例如上图中的9的编码是8个1,然后在结尾加一个0。这种方式编码的缺点很明显,对1000进行编码时,需要999个1,对大数据肯定是不行的。

在实际的使用中最多。对于一个数字x,对于

部分,采用了上面提到的unary编码,而对剩余的部分

则将其转换成二进制,并用n-1bit进行编码。例如,当x=10的时候,

4,对应的unary编码是1110,对于剩余的部分

最终的编码为1110:010。
解码的时候也很方便,只需要先读入unary编码,假设unary解码的结果是4,然后读入4-1=3bit的数据111,转换成数字,则最终的数字x是2**3+7=15。对于小于16的数,占用的bit小于8个字节
前面提到的都是无参数编码,下面介绍一种有参数的编码。叫着Golomb code。对于一个数x,参数b,首先计算

部分,并且将q+1用unary编码,剩余

用截断二进制编码(truncated binary)。例如假如x=2,b=5,则q=0,r=1.0的unary编码是0。对于10,q=1,对应q+1为10,r=4。
如果b是2的指数倍,则结果就是原数字的二进制编码。
否则,对于r,

值编码到

,对于b=5, 则3被编成11,而将剩余的

值编码到

,r=4剩余的部分是4-3=1编码到1。
truncated binary,wikipedia的介绍如下http://en.wikipedia.org/wiki/Truncated_binary_encoding
<


通过“相邻差”的方式对文档id进行压缩,结果如下
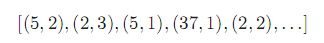
,第二个文档的文档号7保存成第一个文档与第二个文档的差值,2=7-5,同理,第3个文档12保存成与第二个文档的差值,5=12-7。。。。,采取这种方式,差值的最差情况是:最大文档号-最小文档号。
从数字的角度来看, 缺失降低了数字的大小,但是从占用空间的角度来讲,并没有降低数字的大小。int类型假如占4个字节的话,那么可以存储的最大的非负整数是2**32,所以, 数字7和数字12都是占用同样4字节的空间。问题的核心是采用了int类型的定长编码方式,如果采取非定长编码,则可以解决这个问题。
4.5.1字节对齐的和字对齐的编码
为了降低编码的长度,节约存储空间,引入了可变长编码varInt,varInt的最高位是1的话,表示当前bit是最后一个bit,否则为0,表示不是最后一个bit,这样的话每个字节有7位可以使用,1个字节表示的最大值是127。
用1个字节编码,
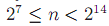
用两个字节编码,
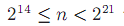
用三个字节。。。
127,128的编码如下,
1 1111111, 0 0000001 1 0000000,这种编码的坏处是解码的时候,需要移位运算,还有frequent branch mispredict。
一种改进的办法是Jeff Dean在WSDM上提出的办法,将每四个字节一起编码,然后用一个字节的prefix来表示后续四个字节的长度,例如00,00,01,10表示后续的4个字节的长度分别是1,1,2,3字节。这样一组的的长度最短是5个字节,最长的长度是17个字节。将所有的前缀(prefix)表存起来,在进行解码的时候直接查表,就能将后续4个字节一起解析出来。通过这种方式比上面的varInt方式速度能提高2倍。
对于大多数机器体系,常常一下子读入一个字的长度,因此基于字对齐的压缩编码更常用,其中最常用的是simple-9,基于32bit,4字节的编码。32bit中4bit保留作为selector,剩余的28bit用来对数据进行编码。例如28bit可以存储28个1bit的数据,或者14个2bit的数据。。直到3个9bit的数据(有一位未使用),公有9种方式,所有交simple-9。
4.5.2bit对齐的编码
首先需要介绍下前缀编码。如果在对字符的2进制编码中不存在某一个字符的编码是另一个字符编码的前缀,那么就称这种编码方式为非前缀编码,Huffman编码就是一种非前缀编码。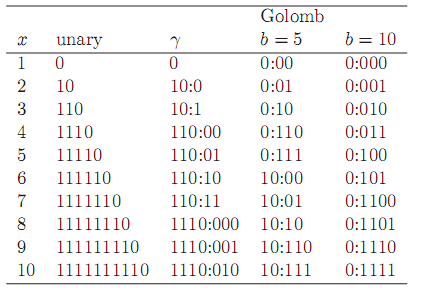
其中,unary是最简单的前缀编码。一个数字x表示成x-1个1,然后在结尾加一个0完成编码。例如上图中的9的编码是8个1,然后在结尾加一个0。这种方式编码的缺点很明显,对1000进行编码时,需要999个1,对大数据肯定是不行的。
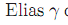
在实际的使用中最多。对于一个数字x,对于

部分,采用了上面提到的unary编码,而对剩余的部分
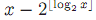
则将其转换成二进制,并用n-1bit进行编码。例如,当x=10的时候,

4,对应的unary编码是1110,对于剩余的部分

最终的编码为1110:010。
解码的时候也很方便,只需要先读入unary编码,假设unary解码的结果是4,然后读入4-1=3bit的数据111,转换成数字,则最终的数字x是2**3+7=15。对于小于16的数,占用的bit小于8个字节
前面提到的都是无参数编码,下面介绍一种有参数的编码。叫着Golomb code。对于一个数x,参数b,首先计算
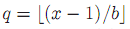
部分,并且将q+1用unary编码,剩余

用截断二进制编码(truncated binary)。例如假如x=2,b=5,则q=0,r=1.0的unary编码是0。对于10,q=1,对应q+1为10,r=4。
如果b是2的指数倍,则结果就是原数字的二进制编码。
否则,对于r,

值编码到

,对于b=5, 则3被编成11,而将剩余的
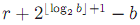
值编码到

,r=4剩余的部分是4-3=1编码到1。
truncated binary,wikipedia的介绍如下http://en.wikipedia.org/wiki/Truncated_binary_encoding
<

相关文章推荐
- Data-Intensive Text Processing with MapReduce第三章(3)-MapReduce算法设计-3.2 PAIRS(对)和STRIPES(条纹)
- 《Data-intensive Text Processing with MapReduce》读书笔记第3章:MapReduce算法设计(1)
- Data-Intensive Text Processing with MapReduce第三章(4)-MapReduce算法设计-3.3计算相对频率
- 《Data-intensive Text Processing with MapReduce》读书笔记第1章:引言
- 《Data-intensive Text Processing with MapReduce》读书笔记第3章:MapReduce算法设计(2)
- Data-Intensive Text Processing with MapReduce第三章(5)-MapReduce算法设计-3.4 二次排序
- 《Data-intensive Text Processing with MapReduce》读书笔记第3章:MapReduce算法设计(5)
- 《Data-intensive Text Processing with MapReduce》读书笔记第2章:MapReduce基础(3)
- 《Data-intensive Text Processing with MapReduce》读书笔记第3章:MapReduce算法设计(3)
- Data-Intensive Text Processing with MapReduce第三章(3)——COMPUTING RELATIVE FREQUENCIES
- Data-Intensive Text Processing with MapReduce第三章(4)-SECONDARY SORTING
- Data-Intensive Text Processing with MapReduce第三章(6)-MapReduce算法设计-3.5相关连接(RELATIONAL JOINS)
- 《Data-intensive Text Processing with MapReduce》读书笔记第2章:MapReduce基础(1)
- Data-Intensive Text Processing with MapReduce
- Data-Intensive Text Processing with MapReduce第三章(6)-MapReduce算法设计-3.5相关连接(RELATIONAL JOINS)
- Data-Intensive Text Processing with MapReduce第三章(7)-3.6总结
- 《Data-intensive Text Processing with MapReduce》读书笔记第2章:MapReduce基础(4)
- 《Data-intensive Text Processing with MapReduce》读书笔记第3章:MapReduce算法设计(4)
- Data-Intensive Text Processing with MapReduce 第三章(1)——local aggregation
- data-intensive text processing with mapreduce-MapReduce Algorithm Design