10.手工备份恢复--导入导出(练习15.16.17)
2010-02-23 08:59
260 查看
到目前为止介绍的备份和恢复活动都是物理操作,如果只希望把数据库的数据和对象拷入或拷出Oracle数据库,又如何处理呢?Oracle应用程序Export(导出)和Impot(导出)可以把一个数据库的逻辑内容拷贝到一个Oracle二进制格式的转储文件中,并把该文件保存在磁盘或者磁带上,当需要时可以把该二进制文件内容读入一个Oracle数据库库中以创建其中包含的对象。这样的逻辑转移可以在同一个数据库上进行,也可以在不同的Oracle数据库之间进行,即使这些数据库位于硬件和软件配置不同的平台上。
当在一个Oracle数据库上运行Export时,所有的非数据字典对象(如:表)都提取到一个文件中,Imort应用程序从一个Export转出文件中读取对象定义以及表数据,并在Oracle数据库中创建这些对象。导出文件可以作为除正常的物理备份之外的备份。使用Export/Import需要注意的要点:
导入操作只能由Oracle导入应用程序读取;
导入应用程序的版本不能比用于创建转储文件的导出应用程序的版本老;
在运行导入或导出应用程序时数据库必须打开;
导出和导入应用程序可以在任何Net8客户机上运行;所处理的文件常常存放在客户机上,NET8导出或导入会引起额外的网络通信开销。
Export/Import有四种模式:
完整数据库模式(Full database mode):导出数据库的内容写入到一个文件中,但某些用户对象(SYS、ORDSYS、CTXSYS、MDSYS、ORDPLUGINS)并不导出,定义用户模式的导入参数是FULL=Y;
用户模式(User mode) :属于特定用户的所有数据库对象写到一个文件中,该用户的所有表、索引、视图、触发器、同义词、数据库链接、对象、存储代码等,导入用户是在FROMUSER参数中定义;
表模式(Table mode) :单个表以及相关的对象(例如:索引、约束、触发器、授权)写入到一个文件中,每个表用TABLES参数命名;
表空间模式(Tablespace mode) :对应所选表空间以及这些表空间中包括所有对象元数据写入一个文件中,实际的表数据(行)并不写入到导出文件中。产生的导出文件连同表空间数据文件一个从源数据库拷贝到目标数据库,在导入过程中表空间和对象元数据添加到目标数据库上。
Oracle导出和导入应用程序参数说明:
导出/导入应用程序少数参数在导出和导入之间是公用的,但意义和内涵不同:
Full 完整导出一位这提取整个数据库的所有内容,并创建他们;
Owner和Fromuser/Touser Owner参数在导出时提取拥有者的所有对象。如果导出文件中对象的拥有者在导入时需要更改,Fromuser将指定导出文件中包含的源对象拥有者,Touser指定创建和拥有导入对象的新模式。例如:可以导出Stephan的对象,并希望把他们按照Kenny模式导入,可以使用如下导入参数:FROMUSER=STEPHAN TOUSER=KENNY
Oracle的导出/导入应用程序有许多有价值的功能和特性:
备份和恢复 导出和导入对于应用开发、数据库转移和可迁移表空间是很有用的,它们可以方面用于除备份和恢复策略外的各种DBA任务。因为导出是表的一个快照,如果丢失一个表或者数据文件,加入表本质上是动态的,那么用导出文件和导入应用程序来替换所有的数据将十分困难。但是导出对于扩展实际的备份和恢复有用;
数据块损坏 可以导出整个数据库或关键的表,以此发现表中损坏的数据块,导出过程会对导出的表进行完全扫描,强制读取每一个数据块,检查介质损坏的情况;
数据库版本交叉 可以将某一版本的Oracle源数据库上的模式和数据拷贝到不同的版本的一个目标Oracle数据库,当从源数据库导出数据时,使用两个数据库中较早版本进行导出,向目标数据库导入数据时,使用目标数据库的导入版本;
操作系统交叉 可以用导出/导入将数据从某个操作系统的一个Oracle数据库转移到相同或者不同操作系统上的另一个Oracle数据库中;
字符集支持 Oracle的NLS(本地语言支持)特性提供了适合支持本地语言的字符、数字、符号、日期等。如果在导出或导入过程中看到POSSIBLE CHARSET CONVERSION字样时,应该留心。请注意导出和导入客户机的字符集,必要时要调整NLS_LANG环境变量设置;
练习15:导出完整的数据库
本练习将创建PRACTICE数据库的一个完整数据库导出。
步骤一:交互导出完整的数据库
在此任务中,可以通过交互运行导出应用程序创建一个完整数据库导出文件。在操作系统的提示符下,键入exp启动导出程序,按下回车键,会出现相关问题:
username 指要执行导出用户的名称。任何用户都可以导出他们自己的模式。在此练习中,以SYS身份连接,如果希望在NET8上连接数据库,在服务台(sys/system@practice)后面添加用户名;
password 给出第1步输入用户的口令;
buffer size 以字节为单位,制定用于提取行缓冲区的大小,接受默认值;
export file 导出应用程序创建一个二进制文件,其中包含了版本信息、运行细节、对象创建命令和表插入语句等,接受默认文件名expdat.dmp;
entire database 定义导出的范围,可以导出整个数据库、一个或多个用户,一个或多个表,选择“1”进行完整数据库导出;
grants 决定导出应用程序是否导出对象授权,完整数据库导出时,所有的对象授权都导出,选择“YES”;
table data 导出表是可以带表数据,也可以不带表数据,因为我们希望整个数据库内容包含在内,选择“YES”;
extents 如果压缩域,那么在导入时建立的对象创建命令会将所有的数据合并到一个初始域中,如果没有压缩域,对象按照他们在导出已有的域设置创建,选择“NO”;
当导出开始运行时,屏幕会显示正在运行的工作,当导出结束时,在导出命令运行的目录下将创建一个名为expdat.dmp文件,该文件包含了除SYS、ORDSYS、CTXSYS、MDSYS和ORDPLUGINS以外每个用户所拥有全部模式对象的一个副本。
步骤二:通过命令行导出完整的数据库
可以把命令行参数放在一行,提供导出应用程序所需的全部信息,如果未能给出所需的某个参数,导出应用程序会提示输入参数值。为了用命令行参数将整个数据库导出到一个指定文件中,给出USERID、FILE和FULL参数如下:
1 WIN> exp USERID=system/system@practice file=D:\oracle\CODE\chap8\full.dmp FULL=Y
每一个关键字后面跟一个或一组值,可以省略userid关键字,如下所示:
1 WIN> exp system/system@practice file=D:\oracle\CODE\chap8\full.dmp FULL=Y
由该命令创建的文件为D:\oracle\CODE\chap8\full.dmp。
步骤三:通过参数文件导出完整的数据库
如果不希望以命令行参数形式提供关键字的值,可以提供一个导出应用程序能够读取的参数文件,为了向导出提供一个参数文件名,在parfile关键字后面包含命令的一个文件名:
1 WIN>exp parfile=D:\oracle\CODE\chap8\export_full.par
该参数文件export_full.par内容如下:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 ROWS=N
6 BUFFER=10000
7 COMPRESS=N
关键字USERID、FILE和FULL与前一步骤命令行一样,同时还添加其他参数:
Log 导出执行的全部输出结果写入一个名为D:\oracle\CODE\chap8\full.log的文件中;
Buffer 用于提取行的缓冲区大小为10000字节,适当的设置该参数有助于大型导出更快地运行;
Rows 数据行成为导出文件内容的主要部分,设置ROWS=N,导出应用程序只导出对象定义,不到处数据行;
Compress 压缩会导致导入时创建的各个对象使用初始域,这个域大小足以容纳整个对象。
步骤四:以直接模式导出完整的数据库
导出缺省方式是用SQL SELECT语句从表中提取数据,这种方式数据块从磁盘的数据文件中读取出来,经由数据库缓冲池,计算出数据量写入导出文件中。
直接路径导出几乎完全抛开了缓冲池,数据是直接从数据文件中读取,避开了数据库缓冲池(某些数据块,例如段的头部以及可能的一致读取数据仍要经过缓冲池),因此在大型表上直接路径导出的运行速度更快。
对于小型的PRACTICE数据库,通过直接路径导出速度上不会有显著提高,但对于大型数据库,直接路径导出比常规导出要快好几倍。下面给出这个参数文件运行完整的数据库导出:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 COMPRESS=N
6 DIRECT=Y
技巧:如果需要导出大量的数据,可以为每个导出文件指出最大文件大小,给出多个需要创建的文件名,例如:如果操作系统的文件大小限制为2GB,可以指定FILESIZE=2000M,并在FILE参数中给出一列文件名(FILE=exp1.dmp,exp2.dmp,exp3.dmp),每个文件最大可以为2GB。
步骤五:导入整个数据库用于显示
导入应用程序利用导出文件把对象和数据拷贝到数据库中,也可以用导入应用程序来显示一个导出文件的内容,创建输出且不改变数据库的两个参数是SHOW和INDEXFILE。
利用SHOW参数来显示导入的输出结果,如下所示,创建另一个名为import_full.par的参数文件,在该参数文件设置如下参数值:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 SHOW= Y
以在操作系统命令行用imp可执行程序运行这个文件:
1 WIN>imp parfile=D:\oracle\CODE\chap8\import_full.par
导出文件的内容在屏幕上飞速滚动,同时被写入到由LOGOS参数制定的文件中,利用编辑器,打开屏幕输出的日志文件,查看内容:
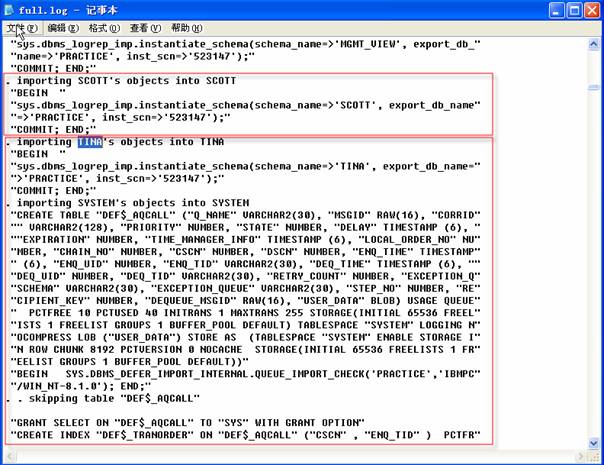
上面列出文件的一些摘录,说明TINA模式部分是什么样的,在文件中首先看到对TINA表的定义,接下来存储PL/SQL语句的源代码,可以查看写入的INSERT_DATE_LOG_ROW的存储过程代码,最后是Oracle作业的一条记录,用户调用存储过程,通过查看这个文件,可以浏览导入进程。该输出文件有两个注意事项:
数据库对象导出和导入的顺序,表在索引之前导入,存储过程在Oracle作业之前;
日志文件中的文本定义隐藏在字词中,利用显示文件输出重新创建存储代码需要有效的编辑。
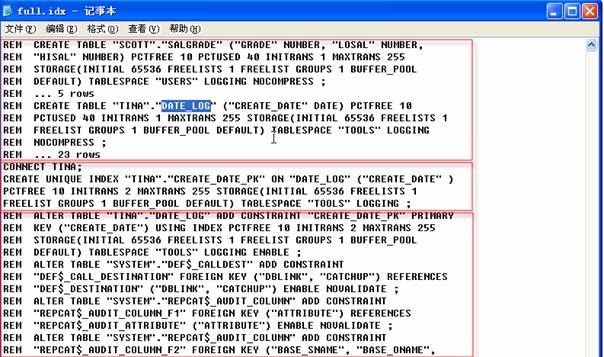
如果只希望在导出文件中包含表和索引定义,那么可以使用INDEXFILE参数,来创建一个只包含表和索引的文件,如下所示:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 INDEXFILE=D:\oracle\CODE\chap8\full.idx
4 FULL=Y
查看生成的索引文件,可以看到表的定义已经注释了,可以删除注释部分,通过运行这个文件重新创建表。
练习16:替换并克隆数据库Scott
本练习中将把用户Scott的数据库对象对象导出到一个单独文件中,利用该文件,可以把该用户复制到数据库,然后利用这个导出文件创建另一个用户。具体的步骤是首先创建一个导出文件,该文件包含了用户Scott所有数据库对象,删除用户Scott后重新创建该用户,并导入所有对象,最后把Scott拥有的数据库对象复制给名为Scott的用户。
步骤一:导出用户Scott
利用下面给出的参数文件导出名为Scott用户的所有对象:
1 #Export user Scott
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 OWNER=SCOTT
关键字“OWNER”决定了该文件包含属于Scott的数据对象,如果希望导出多个用户,在圆括号列出这些所有者,并以逗号分隔。可以查看用LOG关键字定义的日志文件,将看到在导出过程中所创建的屏幕输出。
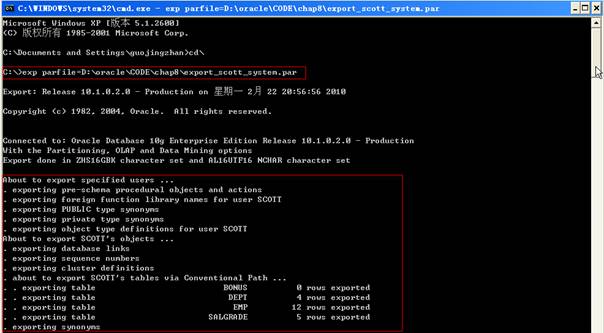
由于用户Scott具有与数据库连接权限,该用户可以自己创建导出,可以使用如下参数文件:
1 #Export user Scott
2 USERID=scott/tiger@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
当以Scott身份连接数据库运行导出时,无需提供OWNER参数。因为Scott只能导出自己的数据对象,导出应用程序默认,如果不指定某个表就导出自己的整个模式。如果希望导出某个用户的模式,可以用那位用户的身份来运行导出,并给出用户口令。如果需要导出一个或多位用户的模式,而不知用户的口令,可以授权DBA用户的身份运行导出,使用参数OWNER,作为一个授权用户,可以一次导出多个用户模式。

步骤二:删除用户Scott
可以用如下DROP USER命令来删除用户Scott:
1 SQL>conn system/system@practice
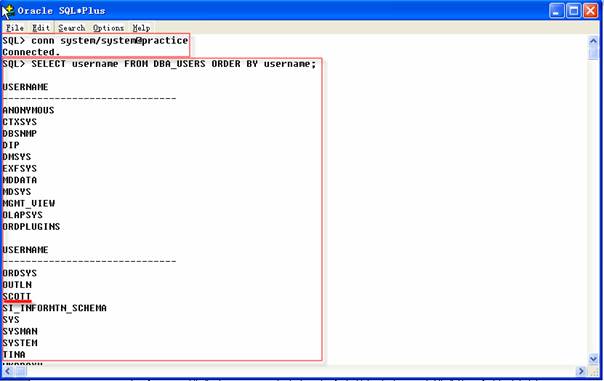
2 SQL>SELECT username FROM DBA_USERS ORDER BY username;
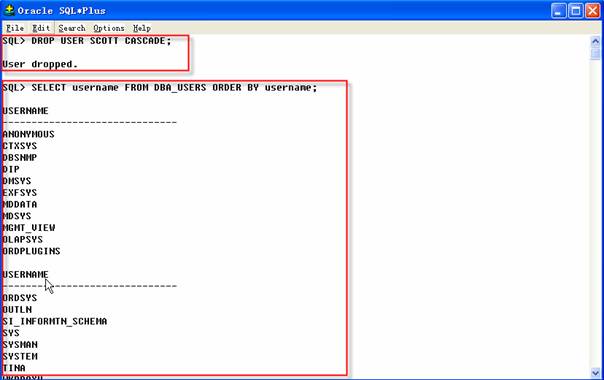
3 SQL>DROP USER SCOTT CASCADE;
4 SQL>SELECT username FROM DBA_USERS ORDER BY username;
DROP USER命令删除一位用户和属于该用户的所有对象,名为DBA_USERS的数据字典视图包含了数据库当前全部用户的一个列表。如果在使用输出命令之前提取该视图的数据将看到Scott数据库的一位用户,删除用户之后,数据字典视图就看到不到用户Scott了。
步骤三:导入用户Scott
到导入Scott模式时,Scott用户账户已经存在数据库中,用户模式的导入并不会创建导入的用户,只会创建用户对象:
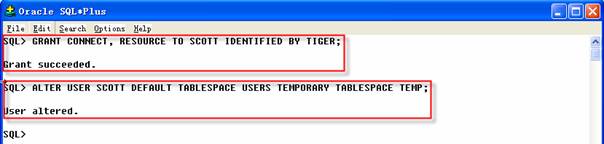
1 SQL>GRANT CONNECT, RESOURCE TO SCOTT IDENTIFIED BY TIGER;
2 SQL>ALTER USER SCOTT DEFAULT TABLESPACE USERS TEMPORARY TABLESPACE TEMP;
在创建用户后可以导入对象。导入与导出有相同的参数,如:USERID、FILE、LOG和PARFILE,但没有关键字OWNER。在导出时,使用OWNER关键字来执行用户模式,作为DBA使用FROMUSER关键字执行用户模式的导入,如下所示:
1 #Import user Scott as a DBA
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 FROMUSER=SCOTT
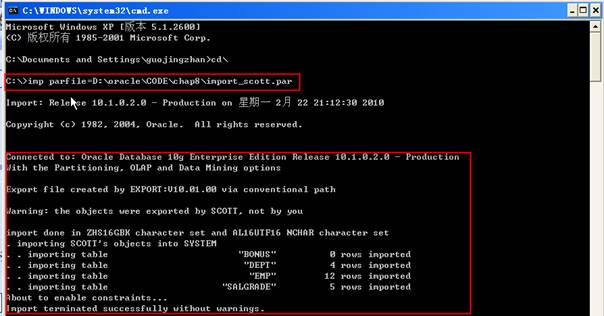
作为用户Scott,可以将一个文件导入自己的模式中,而无需使用关键字FROMUSER,如下所示:
1 #Import user Scott as Scott
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
步骤四:导入用户Scotty
用户Scott告诉你他需要一些空的表来测试新应用程序,他希望你将所有他的模式对象复制到一个名为Scotty的新模式中,为此,你可以从任务1的导出中把Scotty的模式导入到另一个新创建的用户中。
1 SQL>GRANT CONNECT, RESOURCE TO SCOTTY IDENTIFIED BY KITTY;
2 SQL>ALTER USER SCOTTY DEFAULT TABLESPACE USERS TEMPORARY TABLESPACE TEMP;
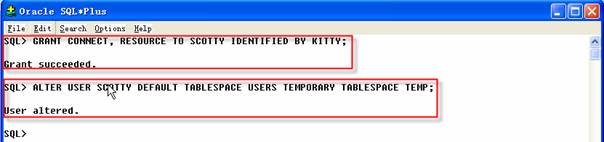
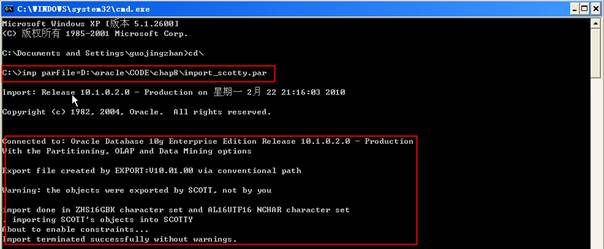
在创建新的用户后,可以把Scott的对象导入到Scotty模式中。这次不需要导入数据,只导入对象,如下所示:
1 #Import user Scotty
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 FROMUSER=SCOTT
6 TOUSER=SCOTTY
7 ROWS=N
练习17:导出一个数据表
该练习中将创建一个文件,该文件包含了PRACTICE数据库中TINA模式的一个表。按照查询参数使用where子句来导出TINA.DATE_LOG表,查询参数允许从一个只包含满足查询子句中谓词的数据行的表进行导出,在截短TINA.DATE_LOG表之后,将从导出文件导入这个表,最后,当从TINA.DATE_LOG中提取数据时,该表中将只有导出过程中创建的那些行。
步骤一:导出表
在从PRACTICE数据库中导出部分表之前向TINA.DATE_LOG表中插入一些将来时间的行,可以向该表插入“SYSDATE+8”,这样表中将包含比今天更大的日期值,插入后提交COMMIT命令。
1 SQL>INSERT INTO tina.date_log VALUES (sysdate+8);
2 SQL>COMMIT;
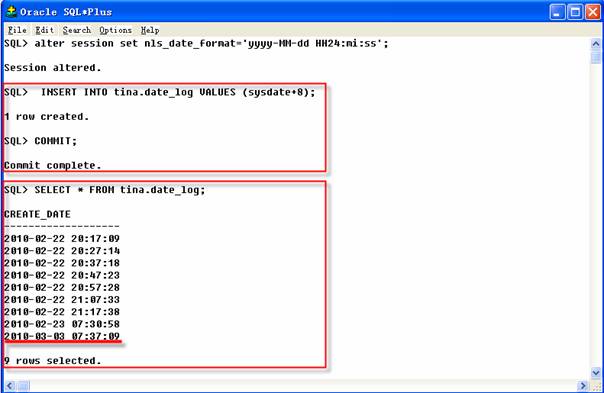
利用一个参数文件创建三个表的导出:
1 WIN>exp parfile=D:\oracle\CODE\chap8\export_date_log.par

具体内容如下:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\export_date_log.dmp
3 LOG=D:\oracle\CODE\chap8\export_date_log.log
4 TABLES=(TINA.DATE_LOG)
5 QUERY="WHERE create_date < SYSDATE"
6 COMPRESS=N
7 DIRECT=N
导出文件将包含TINA.DATE_LOG定义和表中满足where子句条件的行。
步骤二:截短表
利用TRUNCATE TABLE命令,可以快速地从TINA.DATE_LOG表中删除所有数据,删除数据不会打断创建该表中行的作业和存储过程。
1 SQL>SELECT count(*) FROM TINA.DATE_LOG;
2 SQL>SELECT count(*) FROM TINA.DATE_LOG WHERE create_date > SYSDATE;
3 SQL>TRUNCATE TABLE TINA.DATE_LOG;
4 SQL>SELECT count(*) FROM TINA.DATE_LOG;

步骤三:导入表
可以用导出文件中的数据来替换表TINA.DATE_LOG中的行,为执行表的导入,使用“TABLES”关键字,指定想要插入的行,如下所示:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\export_date_log.dmp
3 LOG=D:\oracle\CODE\chap8\import_date_log.log
4 FROMUSER=TINA
5 TABLES=(DATE_LOG)
6 FROMUSER=TINA
7 IGNORE=Y
关键字“IGNORE”指示导入程序向任何已经存在表插入数据行,如果不指定这个关键字,对任何已经存在表的导入都会引起错误,同时该表的行也不会导入。
在操作系统命令行使用如下语句执行导入操作:
1 WIN>imp parfile=D:\oracle\CODE\chap8\import_date_log.par
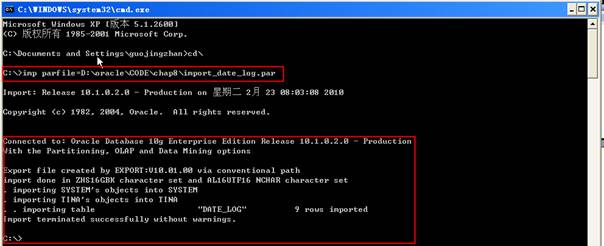
行导入之后,查看确认这些行在表中,同时没有那些的值大于SYSDATE。
1 SQL>SELECT count(*) FROM TINA.DATE_LOG;
2 SQL>SELECT count(*) FROM TINA.DATE_LOG WHERE create_date>SYSDATE;
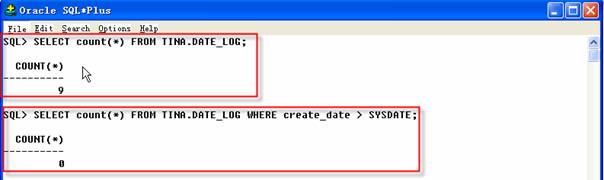
现在表TINA.DATE_LOG中大量的行,但没有一行的日期比今天的大。注意:如果使用查询参数创建一个导出文件后,查询条件并不写入导入文件中,当导入这个文件时,如法判断导入的文件是否包含整个表的内容。
当在一个Oracle数据库上运行Export时,所有的非数据字典对象(如:表)都提取到一个文件中,Imort应用程序从一个Export转出文件中读取对象定义以及表数据,并在Oracle数据库中创建这些对象。导出文件可以作为除正常的物理备份之外的备份。使用Export/Import需要注意的要点:
导入操作只能由Oracle导入应用程序读取;
导入应用程序的版本不能比用于创建转储文件的导出应用程序的版本老;
在运行导入或导出应用程序时数据库必须打开;
导出和导入应用程序可以在任何Net8客户机上运行;所处理的文件常常存放在客户机上,NET8导出或导入会引起额外的网络通信开销。
Export/Import有四种模式:
完整数据库模式(Full database mode):导出数据库的内容写入到一个文件中,但某些用户对象(SYS、ORDSYS、CTXSYS、MDSYS、ORDPLUGINS)并不导出,定义用户模式的导入参数是FULL=Y;
用户模式(User mode) :属于特定用户的所有数据库对象写到一个文件中,该用户的所有表、索引、视图、触发器、同义词、数据库链接、对象、存储代码等,导入用户是在FROMUSER参数中定义;
表模式(Table mode) :单个表以及相关的对象(例如:索引、约束、触发器、授权)写入到一个文件中,每个表用TABLES参数命名;
表空间模式(Tablespace mode) :对应所选表空间以及这些表空间中包括所有对象元数据写入一个文件中,实际的表数据(行)并不写入到导出文件中。产生的导出文件连同表空间数据文件一个从源数据库拷贝到目标数据库,在导入过程中表空间和对象元数据添加到目标数据库上。
Oracle导出和导入应用程序参数说明:
| 参数 | 描 述 |
| Userid | Userid参数为运行导出/导入应用程序的用户提供数据库用户的id和口令,如果以SCOTT身份连接数据库,应输入: Userid=scott/tiger 如果准备在NET8连接,应该输入: Userid=scott/tiger@pracitce 如果必须以SYSDBA身份运行导出或导入程序,应该输入: Userid=”scott/tiger as SYSDBA” |
| File | 参数file定义导出应用程序将要创建的或者导入应用程序将要读取的文件名称,可以完整给出路径名称;如果只提供文件名称,文件将创建到当前目录下或从当前目录下读取;如果没有提供文件名称,这两种应用程序在当前工作目录下寻找expdat.dmp文件 |
| Log | 导出/导入屏幕数据可以捕捉到参数log定义的一个文件中。可以完整地给出路径名称,如果仅提供文件名称,文件将在当前目录下创建 |
| Help | 在命令提示符下可以键入help=y来获取导出和导入应用程序的所有参数的一个简要列表,当用HELP参数列出导出的参数时,部分参数在简单的描述后面都会给出默认值 |
| Parfile | 导出/导入应用程序的参数可以从一个参数文件的文件中读取 |
| Tables | 导出时提取表列表中的那些表或在导入包含在导出文件中的表 |
| Rows | 表示提取每个导出表的行或指示导入应用程序插入每个导入表中的行 |
Full 完整导出一位这提取整个数据库的所有内容,并创建他们;
Owner和Fromuser/Touser Owner参数在导出时提取拥有者的所有对象。如果导出文件中对象的拥有者在导入时需要更改,Fromuser将指定导出文件中包含的源对象拥有者,Touser指定创建和拥有导入对象的新模式。例如:可以导出Stephan的对象,并希望把他们按照Kenny模式导入,可以使用如下导入参数:FROMUSER=STEPHAN TOUSER=KENNY
Oracle的导出/导入应用程序有许多有价值的功能和特性:
备份和恢复 导出和导入对于应用开发、数据库转移和可迁移表空间是很有用的,它们可以方面用于除备份和恢复策略外的各种DBA任务。因为导出是表的一个快照,如果丢失一个表或者数据文件,加入表本质上是动态的,那么用导出文件和导入应用程序来替换所有的数据将十分困难。但是导出对于扩展实际的备份和恢复有用;
数据块损坏 可以导出整个数据库或关键的表,以此发现表中损坏的数据块,导出过程会对导出的表进行完全扫描,强制读取每一个数据块,检查介质损坏的情况;
数据库版本交叉 可以将某一版本的Oracle源数据库上的模式和数据拷贝到不同的版本的一个目标Oracle数据库,当从源数据库导出数据时,使用两个数据库中较早版本进行导出,向目标数据库导入数据时,使用目标数据库的导入版本;
操作系统交叉 可以用导出/导入将数据从某个操作系统的一个Oracle数据库转移到相同或者不同操作系统上的另一个Oracle数据库中;
字符集支持 Oracle的NLS(本地语言支持)特性提供了适合支持本地语言的字符、数字、符号、日期等。如果在导出或导入过程中看到POSSIBLE CHARSET CONVERSION字样时,应该留心。请注意导出和导入客户机的字符集,必要时要调整NLS_LANG环境变量设置;
练习15:导出完整的数据库
本练习将创建PRACTICE数据库的一个完整数据库导出。
步骤一:交互导出完整的数据库
在此任务中,可以通过交互运行导出应用程序创建一个完整数据库导出文件。在操作系统的提示符下,键入exp启动导出程序,按下回车键,会出现相关问题:
username 指要执行导出用户的名称。任何用户都可以导出他们自己的模式。在此练习中,以SYS身份连接,如果希望在NET8上连接数据库,在服务台(sys/system@practice)后面添加用户名;
password 给出第1步输入用户的口令;
buffer size 以字节为单位,制定用于提取行缓冲区的大小,接受默认值;
export file 导出应用程序创建一个二进制文件,其中包含了版本信息、运行细节、对象创建命令和表插入语句等,接受默认文件名expdat.dmp;
entire database 定义导出的范围,可以导出整个数据库、一个或多个用户,一个或多个表,选择“1”进行完整数据库导出;
grants 决定导出应用程序是否导出对象授权,完整数据库导出时,所有的对象授权都导出,选择“YES”;
table data 导出表是可以带表数据,也可以不带表数据,因为我们希望整个数据库内容包含在内,选择“YES”;
extents 如果压缩域,那么在导入时建立的对象创建命令会将所有的数据合并到一个初始域中,如果没有压缩域,对象按照他们在导出已有的域设置创建,选择“NO”;
当导出开始运行时,屏幕会显示正在运行的工作,当导出结束时,在导出命令运行的目录下将创建一个名为expdat.dmp文件,该文件包含了除SYS、ORDSYS、CTXSYS、MDSYS和ORDPLUGINS以外每个用户所拥有全部模式对象的一个副本。
步骤二:通过命令行导出完整的数据库
可以把命令行参数放在一行,提供导出应用程序所需的全部信息,如果未能给出所需的某个参数,导出应用程序会提示输入参数值。为了用命令行参数将整个数据库导出到一个指定文件中,给出USERID、FILE和FULL参数如下:
1 WIN> exp USERID=system/system@practice file=D:\oracle\CODE\chap8\full.dmp FULL=Y
每一个关键字后面跟一个或一组值,可以省略userid关键字,如下所示:
1 WIN> exp system/system@practice file=D:\oracle\CODE\chap8\full.dmp FULL=Y
由该命令创建的文件为D:\oracle\CODE\chap8\full.dmp。
步骤三:通过参数文件导出完整的数据库
如果不希望以命令行参数形式提供关键字的值,可以提供一个导出应用程序能够读取的参数文件,为了向导出提供一个参数文件名,在parfile关键字后面包含命令的一个文件名:
1 WIN>exp parfile=D:\oracle\CODE\chap8\export_full.par
该参数文件export_full.par内容如下:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 ROWS=N
6 BUFFER=10000
7 COMPRESS=N
关键字USERID、FILE和FULL与前一步骤命令行一样,同时还添加其他参数:
Log 导出执行的全部输出结果写入一个名为D:\oracle\CODE\chap8\full.log的文件中;
Buffer 用于提取行的缓冲区大小为10000字节,适当的设置该参数有助于大型导出更快地运行;
Rows 数据行成为导出文件内容的主要部分,设置ROWS=N,导出应用程序只导出对象定义,不到处数据行;
Compress 压缩会导致导入时创建的各个对象使用初始域,这个域大小足以容纳整个对象。
步骤四:以直接模式导出完整的数据库
导出缺省方式是用SQL SELECT语句从表中提取数据,这种方式数据块从磁盘的数据文件中读取出来,经由数据库缓冲池,计算出数据量写入导出文件中。
直接路径导出几乎完全抛开了缓冲池,数据是直接从数据文件中读取,避开了数据库缓冲池(某些数据块,例如段的头部以及可能的一致读取数据仍要经过缓冲池),因此在大型表上直接路径导出的运行速度更快。
对于小型的PRACTICE数据库,通过直接路径导出速度上不会有显著提高,但对于大型数据库,直接路径导出比常规导出要快好几倍。下面给出这个参数文件运行完整的数据库导出:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 COMPRESS=N
6 DIRECT=Y
技巧:如果需要导出大量的数据,可以为每个导出文件指出最大文件大小,给出多个需要创建的文件名,例如:如果操作系统的文件大小限制为2GB,可以指定FILESIZE=2000M,并在FILE参数中给出一列文件名(FILE=exp1.dmp,exp2.dmp,exp3.dmp),每个文件最大可以为2GB。
步骤五:导入整个数据库用于显示
导入应用程序利用导出文件把对象和数据拷贝到数据库中,也可以用导入应用程序来显示一个导出文件的内容,创建输出且不改变数据库的两个参数是SHOW和INDEXFILE。
利用SHOW参数来显示导入的输出结果,如下所示,创建另一个名为import_full.par的参数文件,在该参数文件设置如下参数值:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 SHOW= Y
以在操作系统命令行用imp可执行程序运行这个文件:
1 WIN>imp parfile=D:\oracle\CODE\chap8\import_full.par
导出文件的内容在屏幕上飞速滚动,同时被写入到由LOGOS参数制定的文件中,利用编辑器,打开屏幕输出的日志文件,查看内容:
上面列出文件的一些摘录,说明TINA模式部分是什么样的,在文件中首先看到对TINA表的定义,接下来存储PL/SQL语句的源代码,可以查看写入的INSERT_DATE_LOG_ROW的存储过程代码,最后是Oracle作业的一条记录,用户调用存储过程,通过查看这个文件,可以浏览导入进程。该输出文件有两个注意事项:
数据库对象导出和导入的顺序,表在索引之前导入,存储过程在Oracle作业之前;
日志文件中的文本定义隐藏在字词中,利用显示文件输出重新创建存储代码需要有效的编辑。
如果只希望在导出文件中包含表和索引定义,那么可以使用INDEXFILE参数,来创建一个只包含表和索引的文件,如下所示:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 INDEXFILE=D:\oracle\CODE\chap8\full.idx
4 FULL=Y
查看生成的索引文件,可以看到表的定义已经注释了,可以删除注释部分,通过运行这个文件重新创建表。
练习16:替换并克隆数据库Scott
本练习中将把用户Scott的数据库对象对象导出到一个单独文件中,利用该文件,可以把该用户复制到数据库,然后利用这个导出文件创建另一个用户。具体的步骤是首先创建一个导出文件,该文件包含了用户Scott所有数据库对象,删除用户Scott后重新创建该用户,并导入所有对象,最后把Scott拥有的数据库对象复制给名为Scott的用户。
步骤一:导出用户Scott
利用下面给出的参数文件导出名为Scott用户的所有对象:
1 #Export user Scott
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 OWNER=SCOTT
关键字“OWNER”决定了该文件包含属于Scott的数据对象,如果希望导出多个用户,在圆括号列出这些所有者,并以逗号分隔。可以查看用LOG关键字定义的日志文件,将看到在导出过程中所创建的屏幕输出。
由于用户Scott具有与数据库连接权限,该用户可以自己创建导出,可以使用如下参数文件:
1 #Export user Scott
2 USERID=scott/tiger@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
当以Scott身份连接数据库运行导出时,无需提供OWNER参数。因为Scott只能导出自己的数据对象,导出应用程序默认,如果不指定某个表就导出自己的整个模式。如果希望导出某个用户的模式,可以用那位用户的身份来运行导出,并给出用户口令。如果需要导出一个或多位用户的模式,而不知用户的口令,可以授权DBA用户的身份运行导出,使用参数OWNER,作为一个授权用户,可以一次导出多个用户模式。
步骤二:删除用户Scott
可以用如下DROP USER命令来删除用户Scott:
1 SQL>conn system/system@practice
2 SQL>SELECT username FROM DBA_USERS ORDER BY username;
3 SQL>DROP USER SCOTT CASCADE;
4 SQL>SELECT username FROM DBA_USERS ORDER BY username;
DROP USER命令删除一位用户和属于该用户的所有对象,名为DBA_USERS的数据字典视图包含了数据库当前全部用户的一个列表。如果在使用输出命令之前提取该视图的数据将看到Scott数据库的一位用户,删除用户之后,数据字典视图就看到不到用户Scott了。
步骤三:导入用户Scott
到导入Scott模式时,Scott用户账户已经存在数据库中,用户模式的导入并不会创建导入的用户,只会创建用户对象:
1 SQL>GRANT CONNECT, RESOURCE TO SCOTT IDENTIFIED BY TIGER;
2 SQL>ALTER USER SCOTT DEFAULT TABLESPACE USERS TEMPORARY TABLESPACE TEMP;
在创建用户后可以导入对象。导入与导出有相同的参数,如:USERID、FILE、LOG和PARFILE,但没有关键字OWNER。在导出时,使用OWNER关键字来执行用户模式,作为DBA使用FROMUSER关键字执行用户模式的导入,如下所示:
1 #Import user Scott as a DBA
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 FROMUSER=SCOTT
作为用户Scott,可以将一个文件导入自己的模式中,而无需使用关键字FROMUSER,如下所示:
1 #Import user Scott as Scott
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
步骤四:导入用户Scotty
用户Scott告诉你他需要一些空的表来测试新应用程序,他希望你将所有他的模式对象复制到一个名为Scotty的新模式中,为此,你可以从任务1的导出中把Scotty的模式导入到另一个新创建的用户中。
1 SQL>GRANT CONNECT, RESOURCE TO SCOTTY IDENTIFIED BY KITTY;
2 SQL>ALTER USER SCOTTY DEFAULT TABLESPACE USERS TEMPORARY TABLESPACE TEMP;
在创建新的用户后,可以把Scott的对象导入到Scotty模式中。这次不需要导入数据,只导入对象,如下所示:
1 #Import user Scotty
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 FROMUSER=SCOTT
6 TOUSER=SCOTTY
7 ROWS=N
练习17:导出一个数据表
该练习中将创建一个文件,该文件包含了PRACTICE数据库中TINA模式的一个表。按照查询参数使用where子句来导出TINA.DATE_LOG表,查询参数允许从一个只包含满足查询子句中谓词的数据行的表进行导出,在截短TINA.DATE_LOG表之后,将从导出文件导入这个表,最后,当从TINA.DATE_LOG中提取数据时,该表中将只有导出过程中创建的那些行。
步骤一:导出表
在从PRACTICE数据库中导出部分表之前向TINA.DATE_LOG表中插入一些将来时间的行,可以向该表插入“SYSDATE+8”,这样表中将包含比今天更大的日期值,插入后提交COMMIT命令。
1 SQL>INSERT INTO tina.date_log VALUES (sysdate+8);
2 SQL>COMMIT;
利用一个参数文件创建三个表的导出:
1 WIN>exp parfile=D:\oracle\CODE\chap8\export_date_log.par
具体内容如下:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\export_date_log.dmp
3 LOG=D:\oracle\CODE\chap8\export_date_log.log
4 TABLES=(TINA.DATE_LOG)
5 QUERY="WHERE create_date < SYSDATE"
6 COMPRESS=N
7 DIRECT=N
导出文件将包含TINA.DATE_LOG定义和表中满足where子句条件的行。
步骤二:截短表
利用TRUNCATE TABLE命令,可以快速地从TINA.DATE_LOG表中删除所有数据,删除数据不会打断创建该表中行的作业和存储过程。
1 SQL>SELECT count(*) FROM TINA.DATE_LOG;
2 SQL>SELECT count(*) FROM TINA.DATE_LOG WHERE create_date > SYSDATE;
3 SQL>TRUNCATE TABLE TINA.DATE_LOG;
4 SQL>SELECT count(*) FROM TINA.DATE_LOG;
步骤三:导入表
可以用导出文件中的数据来替换表TINA.DATE_LOG中的行,为执行表的导入,使用“TABLES”关键字,指定想要插入的行,如下所示:
1 USERID=system/system@practice
2 FILE=D:\oracle\CODE\chap8\export_date_log.dmp
3 LOG=D:\oracle\CODE\chap8\import_date_log.log
4 FROMUSER=TINA
5 TABLES=(DATE_LOG)
6 FROMUSER=TINA
7 IGNORE=Y
关键字“IGNORE”指示导入程序向任何已经存在表插入数据行,如果不指定这个关键字,对任何已经存在表的导入都会引起错误,同时该表的行也不会导入。
在操作系统命令行使用如下语句执行导入操作:
1 WIN>imp parfile=D:\oracle\CODE\chap8\import_date_log.par
行导入之后,查看确认这些行在表中,同时没有那些的值大于SYSDATE。
1 SQL>SELECT count(*) FROM TINA.DATE_LOG;
2 SQL>SELECT count(*) FROM TINA.DATE_LOG WHERE create_date>SYSDATE;
现在表TINA.DATE_LOG中大量的行,但没有一行的日期比今天的大。注意:如果使用查询参数创建一个导出文件后,查询条件并不写入导入文件中,当导入这个文件时,如法判断导入的文件是否包含整个表的内容。

相关文章推荐
- 8.手工备份恢复--备用数据库(练习10、11)
- 手工备份恢复--导入导出
- db2导入导出单表数据 db2备份恢复
- OCR磁盘的导出和导入、备份和恢复以及移动(ocrconfig命令的应用)
- Oracle数据库导入导出命令(备份与恢复)归纳总结
- MongoDB 导出导入备份恢复数据实例
- Oracle的导入导出(备份与恢复)
- MongoDB导入、导出、备份、恢复、用户授权(四)
- 【Oracle】OCR的备份和恢复之导出导入
- MongoDB数据库的文件备份恢复以及文件导入导出
- MongoDB数据库的文件备份恢复以及文件导入导出
- MongoDB数据库的文件备份恢复以及文件导入导出
- ROS配置的导出/导入、系统的备份/恢复
- Oracle简单的备份和恢复-导出和导入(1)
- MongoDB --- 数据导入、导出、备份与恢复
- 数据库备份和恢复--数据的导入导出 (mysql)
- Mongodb数据处理(备份mongodump、恢复mongorestore、导入mongoimport、导出mongoexport)
- mysql导入及导出:备份与恢复
- 7.手工备份恢复--复制数据库(练习9)
- Mysql 一次性备份导出/导入恢复所有数据库