搜索引擎中中文词组分词的实现
2007-04-18 13:12
911 查看
Lucene.net标准分词器在英文分词中有非常好的体验。比喻说:在邮件,IP地址,符号处理方面,它都处理得非常好。只是很遗憾,它不支持中文词组分词。于是,我就通过修改里面的核心代码让它扩展,支持中文的分词。
目标:使它能够增加对中文词组的切词。
效果:
原句:“我是中国人!I am chiness!Email:youpeizun126@126.com;IP:172.17.34.168”
切词效果:
我/是/中国人/中国/中/国/人/Email/youpeizun126@126.com/IP/172.17.34.168
所要完成的任务:
1. 装载词库
2. 截取一段连续的中文字段
3. 进行连续的分词.
下面是设计扩展Lucene.net标准分词器的支持中文词组分词的流程图.
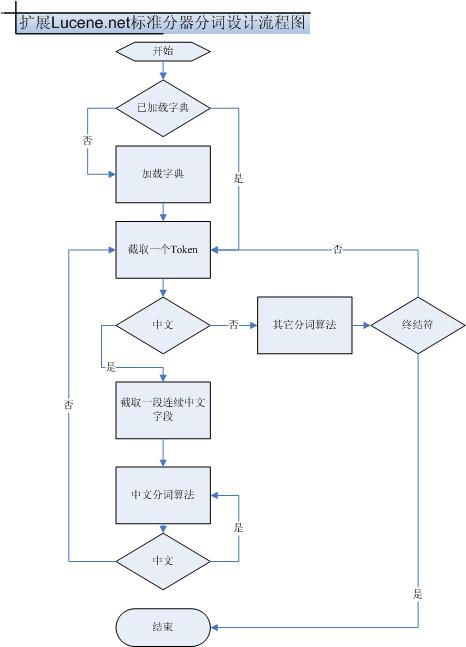
接下来,我把扩展Lucene.net标准分词器所写的核心代码,主要包含三个函数,它们分别实现装载词典,载取连续中文字段,中文词组分词算法功能.


中文词组分词核心代码
/**//*

#region 加载中文词典
public void LoadDirectory(string path)
{
if(!File.Exists("words.txt"))
return;
TextReader tr_words=new StreamReader("words.txt",System.Text.Encoding.Default);
System.Diagnostics.Debug.Write("begin read words");
if(directory==null)
{
directory=new System.Collections.Hashtable();
try
{
string word=null;
while((word=tr_words.ReadLine())!=null)
{
try
{
if(directory[word]==null)
{
directory.Add(word,word);
}
}
catch(SystemException ex_)
{
}
}
}
catch(SystemException ex)
{
}
}
#endregion
}
#region 截取一段连续中文字段
private void InitChinessText()
{
textlengh=0;
cn_index=0;
chinesstext[0]=token.image;
textlengh++;
cn_start=token.beginColumn;
isCnToken=true;
bool isCN= true;
while(isCN&&textlengh<255)
{ token=token_source.GetNextToken();
if(token.kind!=0)
{
isCN=Char.GetUnicodeCategory(token.image,0).Equals(System.Globalization.UnicodeCategory.OtherLetter);
}
else
isCN=false;
if(isCN)
{
chinesstext[textlengh]=token.image;
textlengh++;
}
else
{
cn_end_token=token;
}
}
if(textlengh>=4)
{
wordlengh=4;
}
else
wordlengh=textlengh;
}
#endregion
#region 实现中文分词算法
private string GetNextTokenText()
{ string text=null;
if(wordlengh==4)
{
text=chinesstext[cn_index]+chinesstext[cn_index+1]+chinesstext[cn_index+2]+chinesstext[cn_index+3];
if(directory[text]!=null)
{
}
wordlengh--;
}
if(wordlengh==3)
{
text=chinesstext[cn_index]+chinesstext[cn_index+1]+chinesstext[cn_index+2];
wordlengh--;
if(directory[text]!=null)
{
goto return_;
}
}
if(wordlengh==2)
{
text=chinesstext[cn_index]+chinesstext[cn_index+1];
wordlengh--;
if(directory[text]!=null)
{
goto return_;
}
}
if(wordlengh==1)
{
text=chinesstext[cn_index];
cn_index++;
if((textlengh-cn_index)>=4)
{
wordlengh=4;
}
else
if((textlengh-cn_index)==0)
{
isCnToken=false;
jj_ntk=cn_end_token.kind;
token=new Token();
token.next=cn_end_token;
}
else
{
wordlengh=textlengh-cn_index;
}
}
return_:
return text;
}
#endregion

*/
结束,谢谢你的阅读.
目标:使它能够增加对中文词组的切词。
效果:
原句:“我是中国人!I am chiness!Email:youpeizun126@126.com;IP:172.17.34.168”
切词效果:
我/是/中国人/中国/中/国/人/Email/youpeizun126@126.com/IP/172.17.34.168
所要完成的任务:
1. 装载词库
2. 截取一段连续的中文字段
3. 进行连续的分词.
下面是设计扩展Lucene.net标准分词器的支持中文词组分词的流程图.
接下来,我把扩展Lucene.net标准分词器所写的核心代码,主要包含三个函数,它们分别实现装载词典,载取连续中文字段,中文词组分词算法功能.
中文词组分词核心代码
/**//*
#region 加载中文词典
public void LoadDirectory(string path)
{
if(!File.Exists("words.txt"))
return;
TextReader tr_words=new StreamReader("words.txt",System.Text.Encoding.Default);
System.Diagnostics.Debug.Write("begin read words");
if(directory==null)
{
directory=new System.Collections.Hashtable();
try
{
string word=null;
while((word=tr_words.ReadLine())!=null)
{
try
{
if(directory[word]==null)
{
directory.Add(word,word);
}
}
catch(SystemException ex_)
{
}
}
}
catch(SystemException ex)
{
}
}
#endregion
}
#region 截取一段连续中文字段
private void InitChinessText()
{
textlengh=0;
cn_index=0;
chinesstext[0]=token.image;
textlengh++;
cn_start=token.beginColumn;
isCnToken=true;
bool isCN= true;
while(isCN&&textlengh<255)
{ token=token_source.GetNextToken();
if(token.kind!=0)
{
isCN=Char.GetUnicodeCategory(token.image,0).Equals(System.Globalization.UnicodeCategory.OtherLetter);
}
else
isCN=false;
if(isCN)
{
chinesstext[textlengh]=token.image;
textlengh++;
}
else
{
cn_end_token=token;
}
}
if(textlengh>=4)
{
wordlengh=4;
}
else
wordlengh=textlengh;
}
#endregion
#region 实现中文分词算法
private string GetNextTokenText()
{ string text=null;
if(wordlengh==4)
{
text=chinesstext[cn_index]+chinesstext[cn_index+1]+chinesstext[cn_index+2]+chinesstext[cn_index+3];
if(directory[text]!=null)
{
}
wordlengh--;
}
if(wordlengh==3)
{
text=chinesstext[cn_index]+chinesstext[cn_index+1]+chinesstext[cn_index+2];
wordlengh--;
if(directory[text]!=null)
{
goto return_;
}
}
if(wordlengh==2)
{
text=chinesstext[cn_index]+chinesstext[cn_index+1];
wordlengh--;
if(directory[text]!=null)
{
goto return_;
}
}
if(wordlengh==1)
{
text=chinesstext[cn_index];
cn_index++;
if((textlengh-cn_index)>=4)
{
wordlengh=4;
}
else
if((textlengh-cn_index)==0)
{
isCnToken=false;
jj_ntk=cn_end_token.kind;
token=new Token();
token.next=cn_end_token;
}
else
{
wordlengh=textlengh-cn_index;
}
}
return_:
return text;
}
#endregion
*/
结束,谢谢你的阅读.

相关文章推荐
- Lucene.net 搜索引擎中中文词组分词的实现
- Beta笔记——搜索引擎的设计与实现(1):使用Lucene.Net建立索引与中文分词
- 搜索引擎之中文分词实现(java版)
- 搜索引擎之中文分词实现(java版)
- 搜索引擎之中文分词实现(java版)
- 搜索引擎之中文分词实现(java版)http://dev.csdn.net/author/jnsuyun/93a3a18757e34954ad24e1a3a2a2902c.html
- 《解密搜索引擎技术实战:Lucene&Java精华版》---第四章中文分词原理与实现学习笔记(一)
- 搜索引擎之中文分词(Chinese Word Segmentation)简介
- 使用Discuz关键词服务器实现PHP中文分词
- 中文搜索引擎技术揭密:中文分词
- 搜索引擎的那些事(中文分词)
- 中文分词之Java实现使用IK Analyzer实现
- Nutch中如何实现中文分词功能
- 中文分词实现——双向最大匹配
- 搜索引擎分词:Nutch整合Paoding中文分词步骤详解
- coreseek+mmseg实现中文分词
- Java实现敏感词过滤 - IKAnalyzer中文分词工具
- Elasticsearch1.x 基于lc-pinyin和ik分词实现 中文、拼音、同义词搜索
- 中文分词之Java实现使用IK Analyzer实现
- 基于hanLP的中文分词详解-MapReduce实现&自定义词典文件