我开发的中文分词程序,开源发布
2007-03-19 06:14
399 查看
功能介绍:请参看花2周时间开发的中文分词终于有点小样了 (有些功能没体现出来)
本中文分词是基于匹配模式开发的中文分词程序,为本人练手作品。也可以直接使用。但不建议。因为整体架构有一些基础性问题。不过做为开发中文分词的参考,相信还是有一定价值的。
最近吕震宇老师发布了ICTCLAS的C#版SharpICTCLAS。很优秀的中文分词程序。我的这个和它根本不是一个级别的。不过在自己的应用中,估计还是不能直接拿SharpICTCLAS就用。因为现在中文分词不仅仅关注准确性了,而更多考虑应用的问题了,比如(以下提的例子仅仅为交流而已,希望你在交流的范围进行思考。不存在褒贬什么的含义):
1,全角识别和处理问题
例子:SUN开放了Java源代码
分析:如果能识别SUN有全角字符,而且也正确识别SUN为一个字符,但是从搜索的角度来看。似乎需要把所有形式处理为一种形式sun,当然这也可以看成是属于Lucene的Analyzer的问题
2,英文识别和处理的问题
例子:U.S.A是美国的的英文简称
分析:在SharpICTCLAS中会把U.S.A分成6个字符。估计SharpICTCLAS的英文处理还是比较弱,毕竟是免费版的。
3,专业术语和特殊字符识别和处理问题
比如asp.net是分成asp/./net还是分成asp.net好?test@test.com是做为一个词还是分开等等。
中文的例子就不举了。SharpICTCLAS对纯中文的分词是非常优秀的。
其实我提出上面的问题,是想表达一个观点,没有最好的中文分词。只有最符合应用的中文分词,所以最好的中文分词应该是你自己根据需求定制开发的。希望我的这个中文分词程序(虽然还是比较烂的

)能够为你提供一些参考。那怕是一点点。
架构(类关系图)
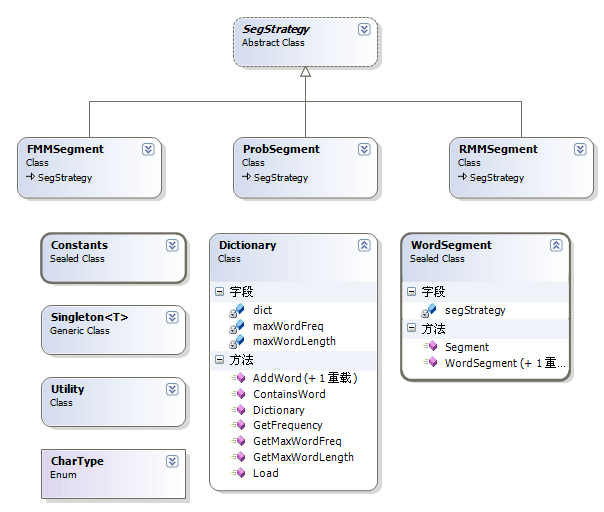
download source code
本中文分词是基于匹配模式开发的中文分词程序,为本人练手作品。也可以直接使用。但不建议。因为整体架构有一些基础性问题。不过做为开发中文分词的参考,相信还是有一定价值的。
最近吕震宇老师发布了ICTCLAS的C#版SharpICTCLAS。很优秀的中文分词程序。我的这个和它根本不是一个级别的。不过在自己的应用中,估计还是不能直接拿SharpICTCLAS就用。因为现在中文分词不仅仅关注准确性了,而更多考虑应用的问题了,比如(以下提的例子仅仅为交流而已,希望你在交流的范围进行思考。不存在褒贬什么的含义):
1,全角识别和处理问题
例子:SUN开放了Java源代码
分析:如果能识别SUN有全角字符,而且也正确识别SUN为一个字符,但是从搜索的角度来看。似乎需要把所有形式处理为一种形式sun,当然这也可以看成是属于Lucene的Analyzer的问题
2,英文识别和处理的问题
例子:U.S.A是美国的的英文简称
分析:在SharpICTCLAS中会把U.S.A分成6个字符。估计SharpICTCLAS的英文处理还是比较弱,毕竟是免费版的。
3,专业术语和特殊字符识别和处理问题
比如asp.net是分成asp/./net还是分成asp.net好?test@test.com是做为一个词还是分开等等。
中文的例子就不举了。SharpICTCLAS对纯中文的分词是非常优秀的。
其实我提出上面的问题,是想表达一个观点,没有最好的中文分词。只有最符合应用的中文分词,所以最好的中文分词应该是你自己根据需求定制开发的。希望我的这个中文分词程序(虽然还是比较烂的
)能够为你提供一些参考。那怕是一点点。
架构(类关系图)
download source code

相关文章推荐
- 我开发的中文分词程序,开源发布
- relaxlife.net发布一个自己开发的中文分词程序
- relaxlife.net发布一个自己开发的中文分词程序
- 【开源】Westore Cloud 发布- 没后端没SQL没DBA,只需 javascript 开发云端小程序
- touch-2.3.1 开发程序与发布环境说明
- 小程序发布上线-微信小程序开发-视频教程17
- 信息系统开发平台OpenExpressApp - 发布【开源信息系统开发平台之 OpenExpressApp框架.pdf】
- Taurus.MVC 2.0 开源发布:WebAPI开发教程
- 【iOS开发】---- CocoaPods:管理Objective-c 程序中各种第三方开源库关联
- Android开发— 开源项目,发布到 JitPack.io
- 微信小程序详细图文教程-10分钟完成微信小程序开发部署发布(3元获取腾讯云服务器带小程序支持系统)
- 使用苏飞httphelper开发自动更新发布文章程序
- 发布cmcc.in 网址缩短,网址压缩程序的源代码,欢迎修改和二次开发
- IOS开发 如何联机调试和发布程序(99$)
- iPhone 开发入门——在 App Store 上发布程序
- 微信小程序开发--开源Demo精选
- Android开发常用开源框架(架构程序)及Volley不再升级了
- iPhone开发入门--- 在App Store上发布程序
- (博客园首发)开源框架knot.js正式发布了,为前端开发带来全新的开发方式--CBS
- 在Visual Studio上开发Node.js程序(2)——远程调试及发布到Azure