二叉树——结构查找相关问题
1. 判断t1树是否包含t2树的所有拓扑结构
1.1. 问题
给定彼此独立的两棵树头节点分别为 t1 和 t2,判断 t1 树是否包含 t2 树全部的拓扑结构。
1.2. 思路
题目这里没有要求时间复杂度。所以就可以用最简单的方法,以t1树上的所有节点都作为根节点和t2比对一次,直到成功一次。 比对的过程也是个递归的过程。整个过程相当于两层循环。时间复杂度为O(m×n)
1.3. 代码
public static boolean contains(TreeNode<Integer> t1, TreeNode<Integer> t2) {
if (t2 == null) return true;
if (t1 == null) return false;
return check(t1, t2) || contains(t1.left, t2) || contains(t1.right, t2);
}
private static boolean check(TreeNode<Integer> t1, TreeNode<Integer> t2) {
if (t2 == null) return true;
if (t1 == null || !t1.val.equals(t2.val))
return false;
return check(t1.left, t2.left) && check(t1.right, t2.right);
}
2. 判断t1树是否有与t2树拓扑结构完全相同的子树
2.1. 问题
给定彼此独立的两棵树头节点分别为 t1 和 t2,判断 t1 中是否有与 t2 树拓扑结构完全相同的子树。
2.2. 解法
这道题可以和判断t1树中是否包含t2树的所有拓扑结构这道题进行对比。
方法一:使用针对二叉树的每个节点为根来进行考察的方法,时间复杂度为O(m×n)。
方法二:将两个二叉树序列化成字符串(序列化时,要在值的前后都加上界限符号),然后用字符串匹配算法查看t1对应的字符串中是否包含t2对应的字符串这个子串。KMP算法,这样时间复杂度可以做到O(N+M)。
2.3. 代码
2.3.1. 递归
class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
if (subRoot == null) {
return true;
}
if (root == null) {
return false;
}
return isSubtree(root.left, subRoot) || isSubtree(root.right, subRoot) || isSame(root, subRoot);
}
public boolean isSame(TreeNode p, TreeNode q) {
if(p == null && q == null) {
return true;
}
if(p == null || q == null) {
return false;
}
if(p.val != q.val) {
return false;
}
return isSame(p.left, q.left) &&isSame(p.right, q.right);
}
}
2.3.2. 字符串匹配法
class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
if(subRoot == null) {
return true;
}
if(root == null) {
return false;
}
StringBuilder builder = new StringBuilder();
serialize(root, builder);
String rootStr = builder.toString();
StringBuilder builder2 = new StringBuilder();
serialize(subRoot, builder2);
String subRootStr = builder2.toString();
return rootStr.contains(subRootStr);
}
public void serialize(TreeNode root, StringBuilder builder) {
if(root == null) {
builder.append("!#!");
return;
}
builder.append('!');
builder.append(root.val);
builder.append('!');
serialize(root.left,builder);
serialize(root.right, builder);
}
}
3. 找到二叉树中符合搜索二叉树的最大拓扑结构
3.1. 问题
给定一棵二叉树的头节点 head,已知所有节点的值都不一样,返回其中最大的且符合搜索二叉树条件的最大拓扑结构的大小。
比如对于:
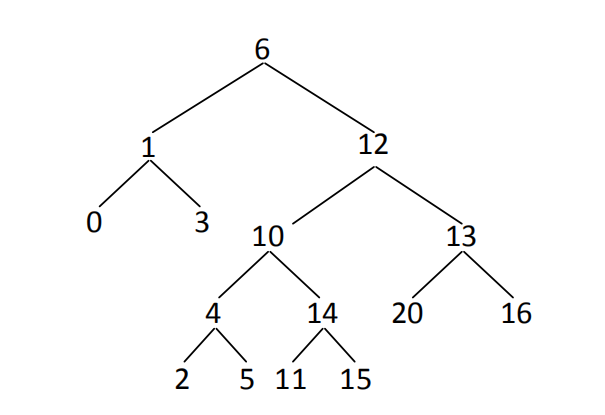
它的符合搜索二叉树条件的最大拓扑结构为:
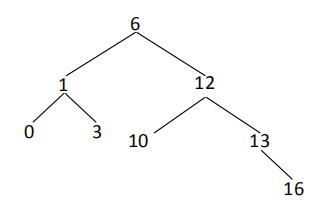
3.2. 思路
这道题比较困难,我第一次写,也是犯了以前做最大矩阵这道题的错误,还是按照找最大搜索二叉子树的树形dp方法,结果后来测试的时候发现行不通,仔细一想确实不能用树形dp的方法,因为对于每个节点来说,f(x)和f(x.left)、f(x.right)并没有递推关系!我之前写的代码里的递推关系都是错的! 我看了书,书中给了两个思路:
时间复杂度为O(n2)的方法:我们只需要遍历每个节点,求以该节点为拓扑结构根节点的最大拓扑结构的大小,然后取其中最大值即可。
时间复杂度为O(n)的方法:在遍历树的时候建立二叉数的拓扑贡献记录即可,然后到上层节点的时候就不需要对其所有子节点进行遍历,只需遍历其左子树的右边界和右子树的左边界即可,然后更新拓扑贡献记录。这种方式其实是使用记忆话的手段,来对方法一进行剪枝。
对于方法一而言,对于某个节点而言如何找以它为拓扑结构根节点的最大拓扑结构呢?我们可以遍历这个节点对应的子树,对每个节点按照从搜索二叉树中找节点的方式进行查找,如果找到的节点与该节点相同,那么说明该节点可以作为最大拓扑结构的一部分;否则,该节点和其子节点都不用看了。
方法一遍历到每个节点的进行处理时候,要检查该节点的子节点,可能的话其所有子孙节点都会检查一遍,相当于两层循环,所以是n^2
方法二中每个节点只会成为一个节点的左子树的右边界或右子树的左边界,所以该节点被检查的次数不会多于两次,所以是线性时间复杂度。
3.3. 代码
3.3.1. 方法一
public static int maxTopology1(TreeNode<Integer> root) {
if (root == null) return 0;
int res = Math.max(maxTopology1(root.left), maxTopology1(root.right));
res = Math.max(res, process(root));
return res;
}
private static int process(TreeNode<Integer> root) {
if (root == null) return 0;
Queue<TreeNode<Integer>> queue = new LinkedList<>();
queue.add(root);
int res = 0;
TreeNode<Integer> node;
while (!queue.isEmpty()) {
node = queue.poll();
if (isBSTNode(root, node)) {
res++;
if (node.left != null)
queue.add(node.left);
if (node.right != null)
queue.add(node.right);
}
}
return res;
}
private static boolean isBSTNode(TreeNode<Integer> root, TreeNode<Integer> node) {
TreeNode<Integer> cur = root;
while (cur != null) {
if (cur.val > node.val) cur = cur.left;
else if (cur.val < node.val) cur = cur.right;
else return cur == node;
}
return false;
}
3.3.2. 方法二
private static class Record {
int left;
int right;
public Record(int left, int right) {
this.left = left;
this.right = right;
}
public int sum() {
return left + right + 1;
}
}
public static int maxTopology2(TreeNode<Integer> root) {
if (root == null) return 0;
HashMap<TreeNode<Integer>, Record> records = new HashMap<>();
return process(root, records);
}
private static int process(TreeNode<Integer> node, Map<TreeNode<Integer>, Record> records) {
if (node == null)
return 0;
int res = Math.max(process(node.left, records), process(node.right, records));
TreeNode<Integer> end = node.left;
TreeNode<Integer> cur = node.left;
int minus;
//这里第一次写错了,第一次循环条件写成end != null && end.val < node.val。
while (records.containsKey(end) && end.val < node.val) {
end = end.right;
}
if (records.containsKey(end)) {
minus = records.remove(end).sum();
while (cur != end) {
records.get(cur).right -= minus;
cur = cur.right;
}
}
cur = end = node.right;
while (records.containsKey(end) && end.val > node.val) {
end = end.left;
}
if (records.containsKey(end)) {
minus = records.remove(end).sum();
while (cur != end) {
records.get(cur).left -= minus;
cur = cur.left;
}
}
//起初在外层方法里的records中放(null,new Record(0,0)),然后这里不对空检查,其实错了
Record self = new Record(0, 0);
Record left = records.getOrDefault(node.left, null);
Record right = records.getOrDefault(node.right, null);
self.left = left != null ? left.sum() : 0;
self.right = right != null ? right.sum() : 0;
records.put(node, self);
return Math.max(res, self.sum());
}

- 数据结构---二叉树查找问题
- 二叉树相关笔试面试问题集锦
- 二叉树结构 codevs 1029 遍历问题
- 二叉树问题(打印二叉树,二叉树子结构、镜像、遍历,二叉树满足的路径)
- 数据结构教程—二叉树相关操作C++实现
- 【Azure Developer】使用PowerShell Where-Object方法过滤多维ArrayList时候,遇见的诡异问题 -- 当查找结果只有一个对象时,返回结果修改了对象结构,把多维变为一维
- 查找表相关问题
- 二叉树问题(打印二叉树,二叉树子结构、镜像、遍历,二叉树满足的路径)
- 若干数组查找问题及相关高效算法(未完待续)
- 面试题二叉树相关问题总结
- [linux]死锁问题查找问题的相关命令
- 剑指Offer 二叉树相关问题
- 数据结构(六)——二叉树 前序、中序、后序、层次遍历及非递归实现 查找、统计个数、比较、求深度的递归实现
- 二叉树的相关操作:创建、查找、求高度和深度、各种遍历(前、中、后、层序)等等
- 关于二分查找的相关问题
- 【Lehr】【数据结构与算法】【C语言】二叉树及其相关操作
- 二叉树相关问题
- 面试题精选(83):二叉树相关的问题
- 二叉树问题---判断t1树是否包含t2树全部的拓扑结构
- 数据结构问题根据广义表创建二叉树的四种遍历方式